Generative Adversarial Networks
ACTL3143 & ACTL5111 Deep Learning for Actuaries
Before GANs we had autoencoders
An autoencoder takes a data/image, maps it to a latent space via en encoder module, then decodes it back to an output with the same dimensions via a decoder module.
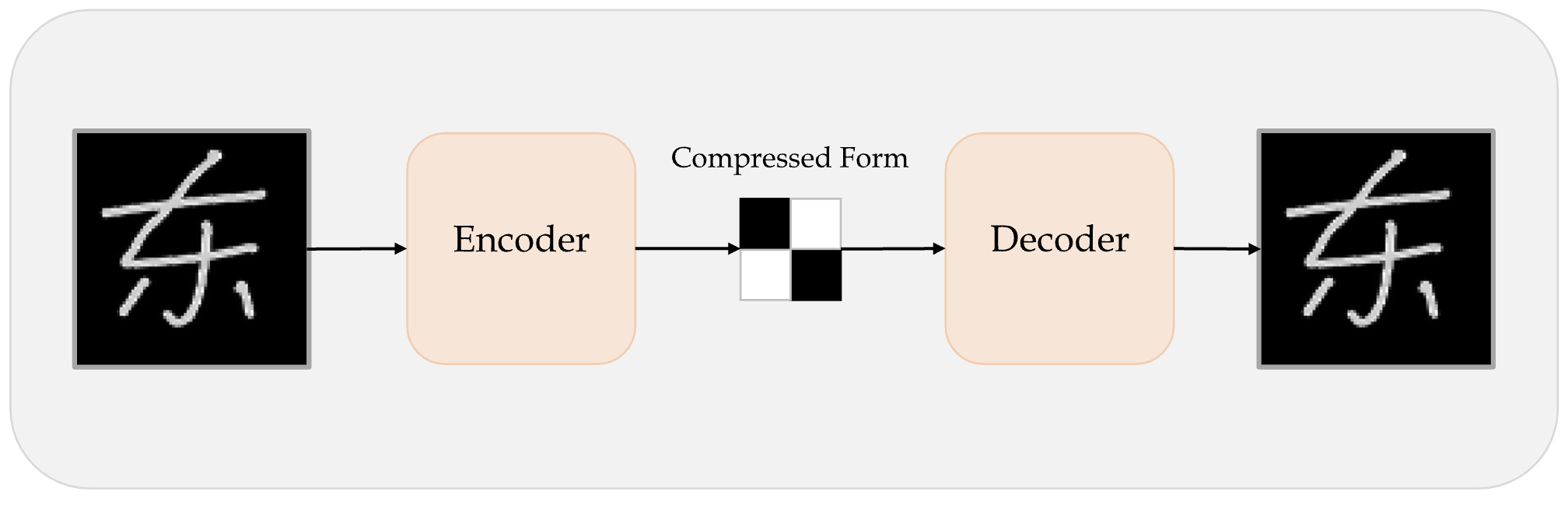
Schematic of an autoencoder.
GAN faces


Try out https://www.whichfaceisreal.com.
GAN structure
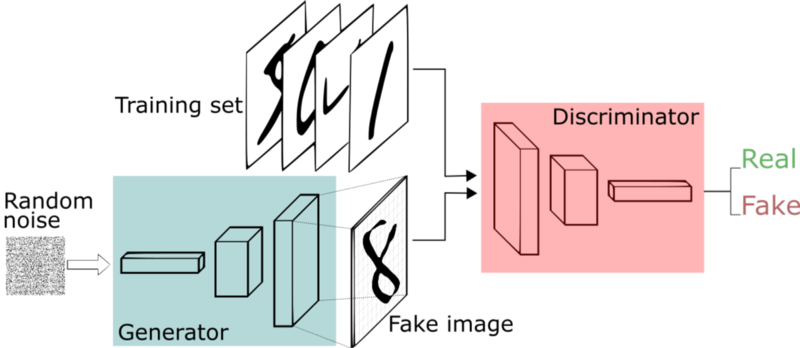
A schematic of a generative adversarial network.
GAN intuition



Unconditional GANs
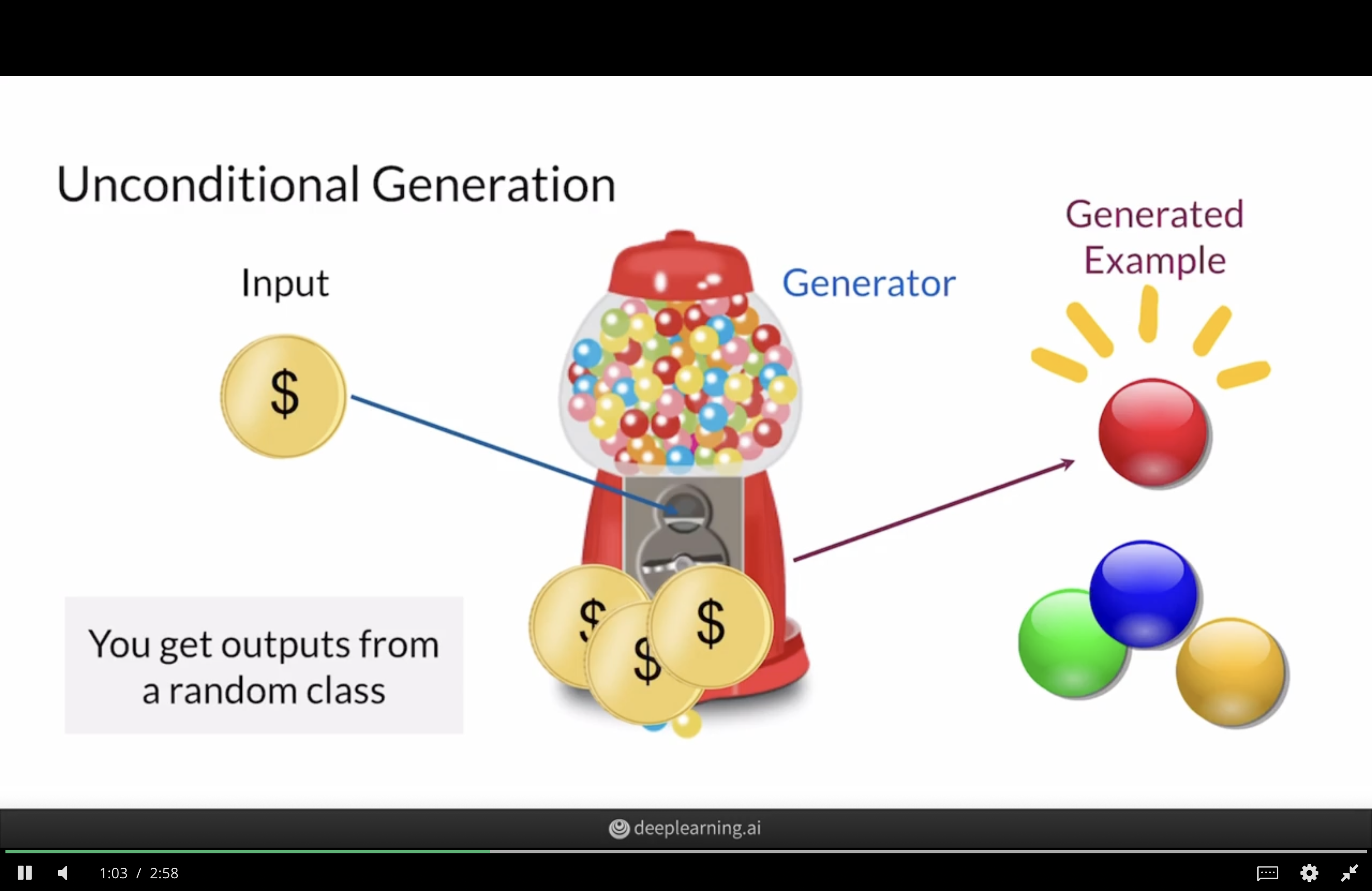
Analogy for an unconditional GAN
Conditional GANs
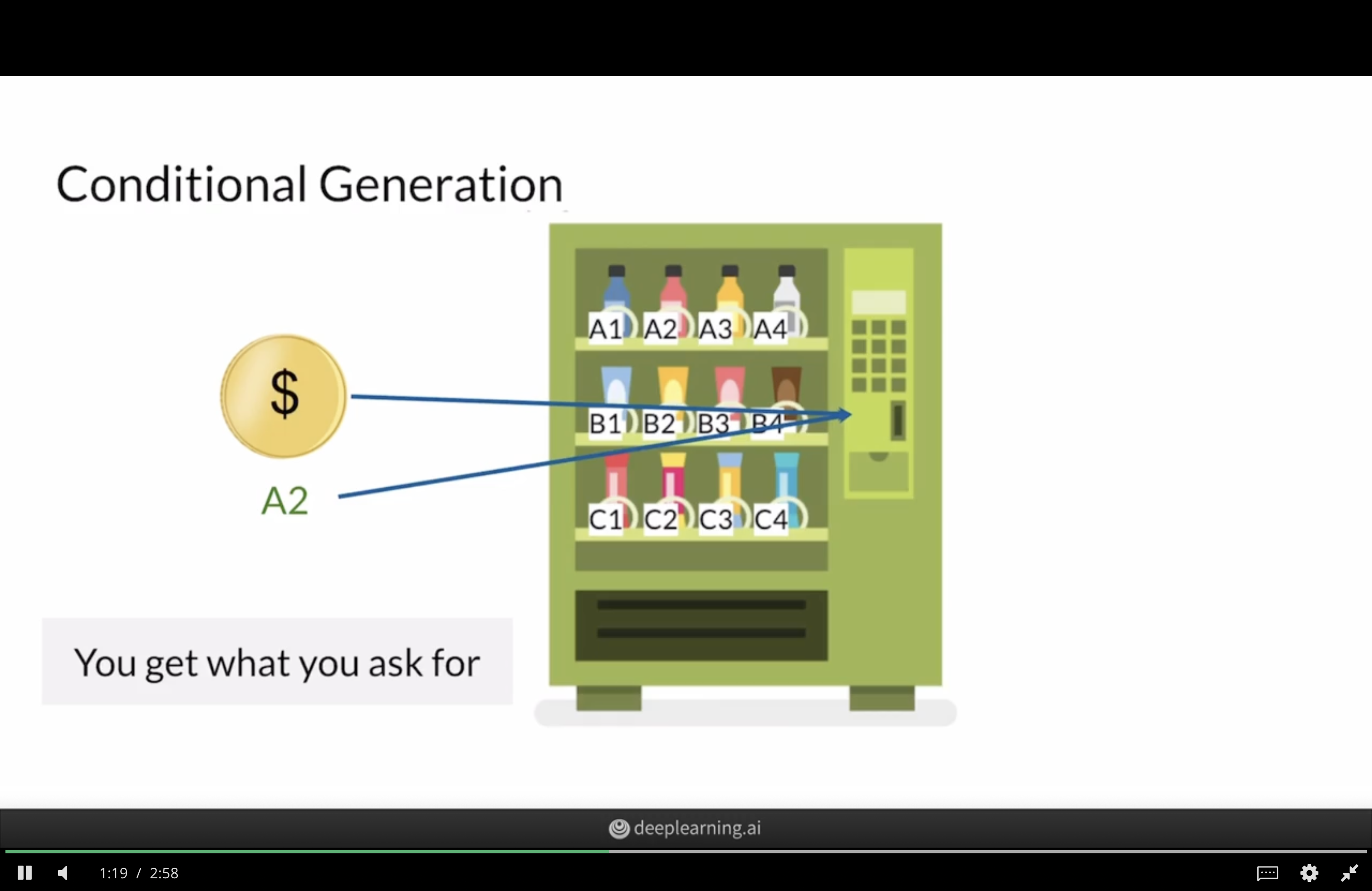
Analogy for a conditional GAN
Hurricane example data

Original data
Hurricane example

Initial fakes
Hurricane example (after 54s)

Fakes after 1 iteration
Hurricane example (after 21m)

Fakes after 100 kimg
Hurricane example (after 47m)

Fakes after 200 kimg
Hurricane example (after 4h10m)

Fakes after 1000 kimg
Hurricane example (after 14h41m)

Fakes after 3700 kimg
Example: Deoldify images #1

A deoldified version of the famous “Migrant Mother” photograph.
Example: Deoldify images #2

A deoldified Golden Gate Bridge under construction.
Example: Deoldify images #3


Generator can’t generate everything


Uncertain convergence
Converges to a Nash equilibrium.. if at all.
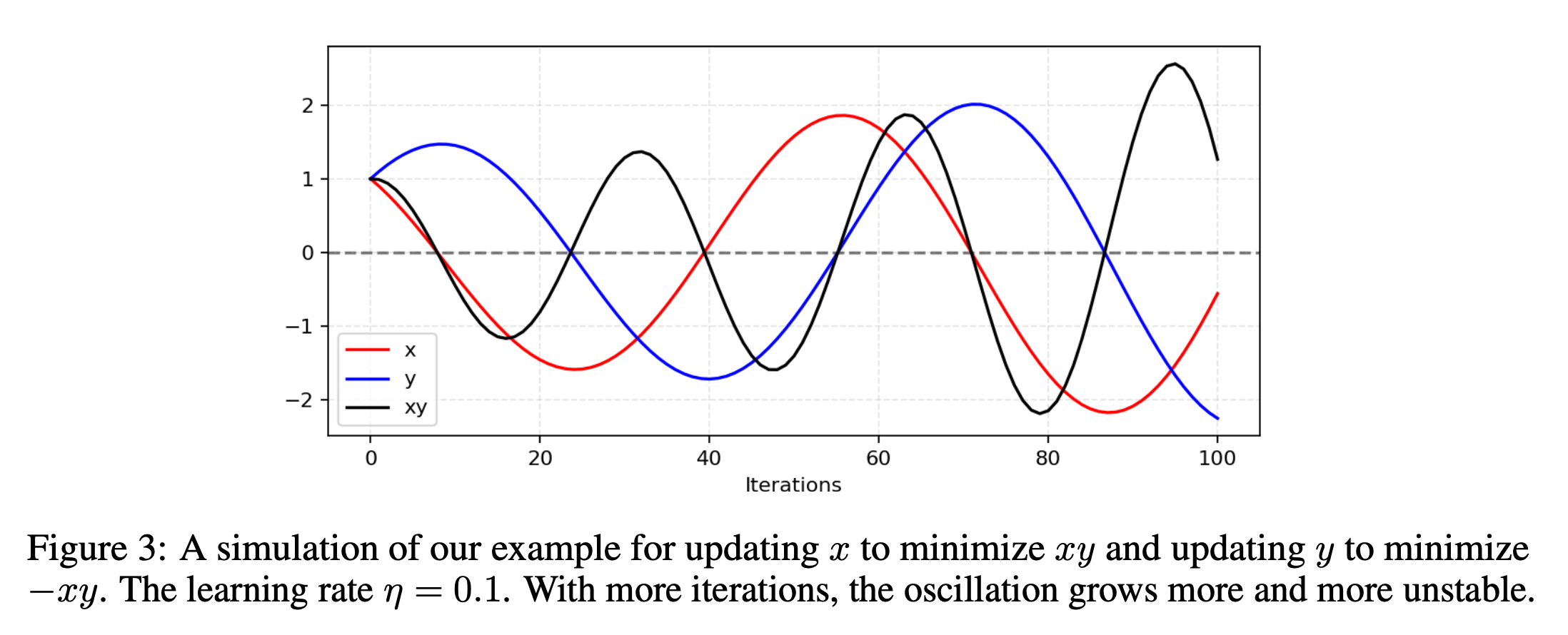
Analogy of minimax update failure.
Mode collapse


Generation is harder
A schematic of a generative adversarial network.
Advanced image layers
Conv2D
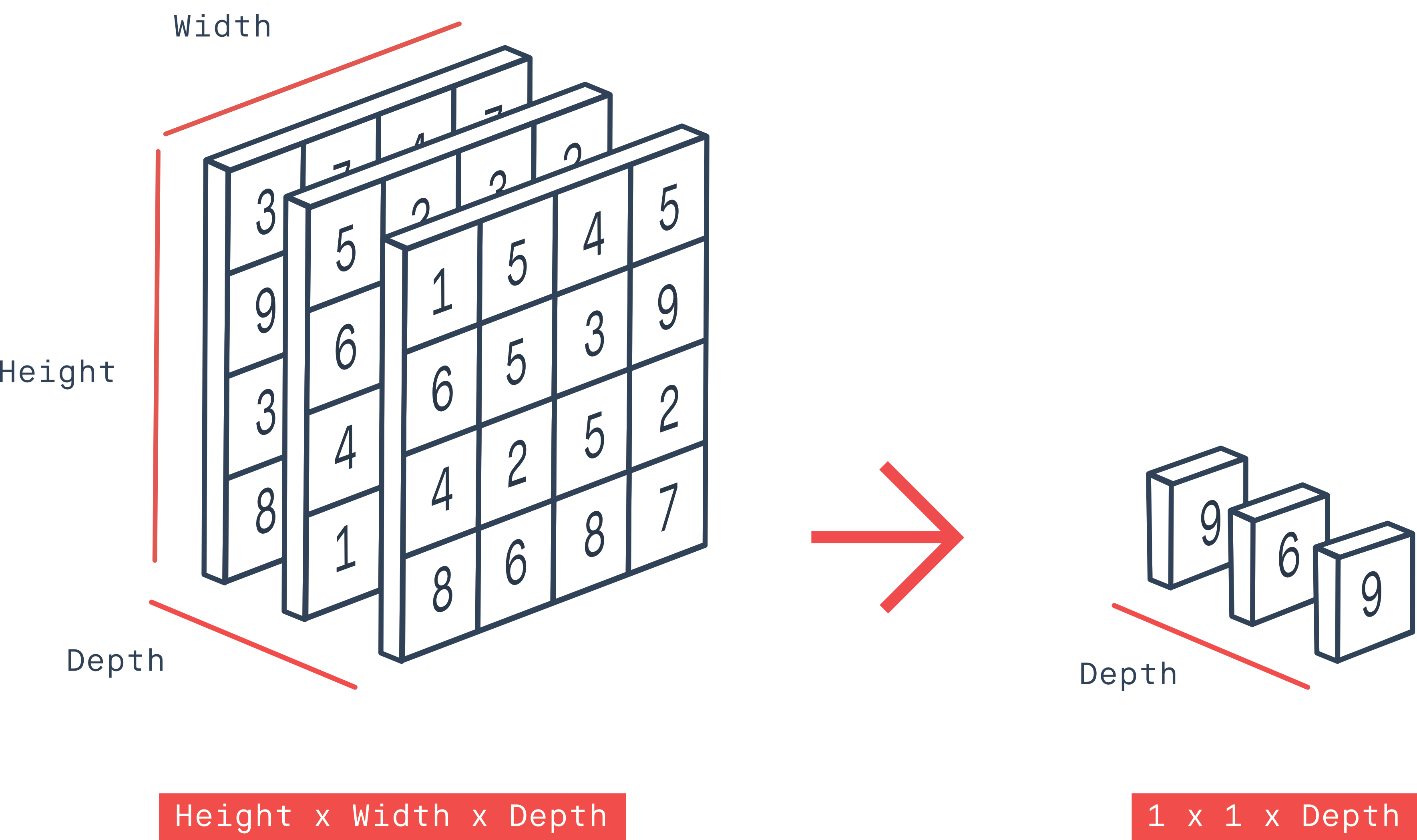
GlobalMaxPool2D
Conv2DTranspose
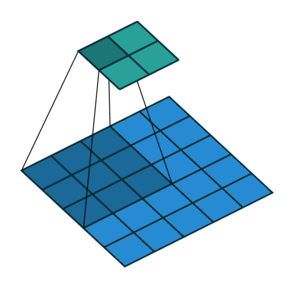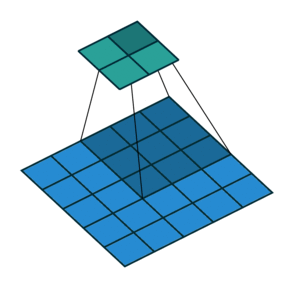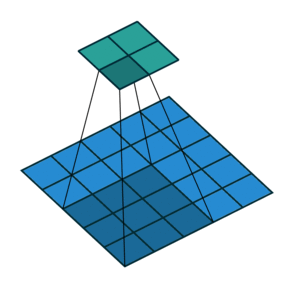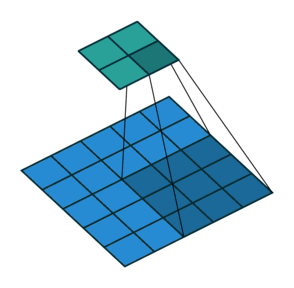
![]()
Vanishing gradients (I)
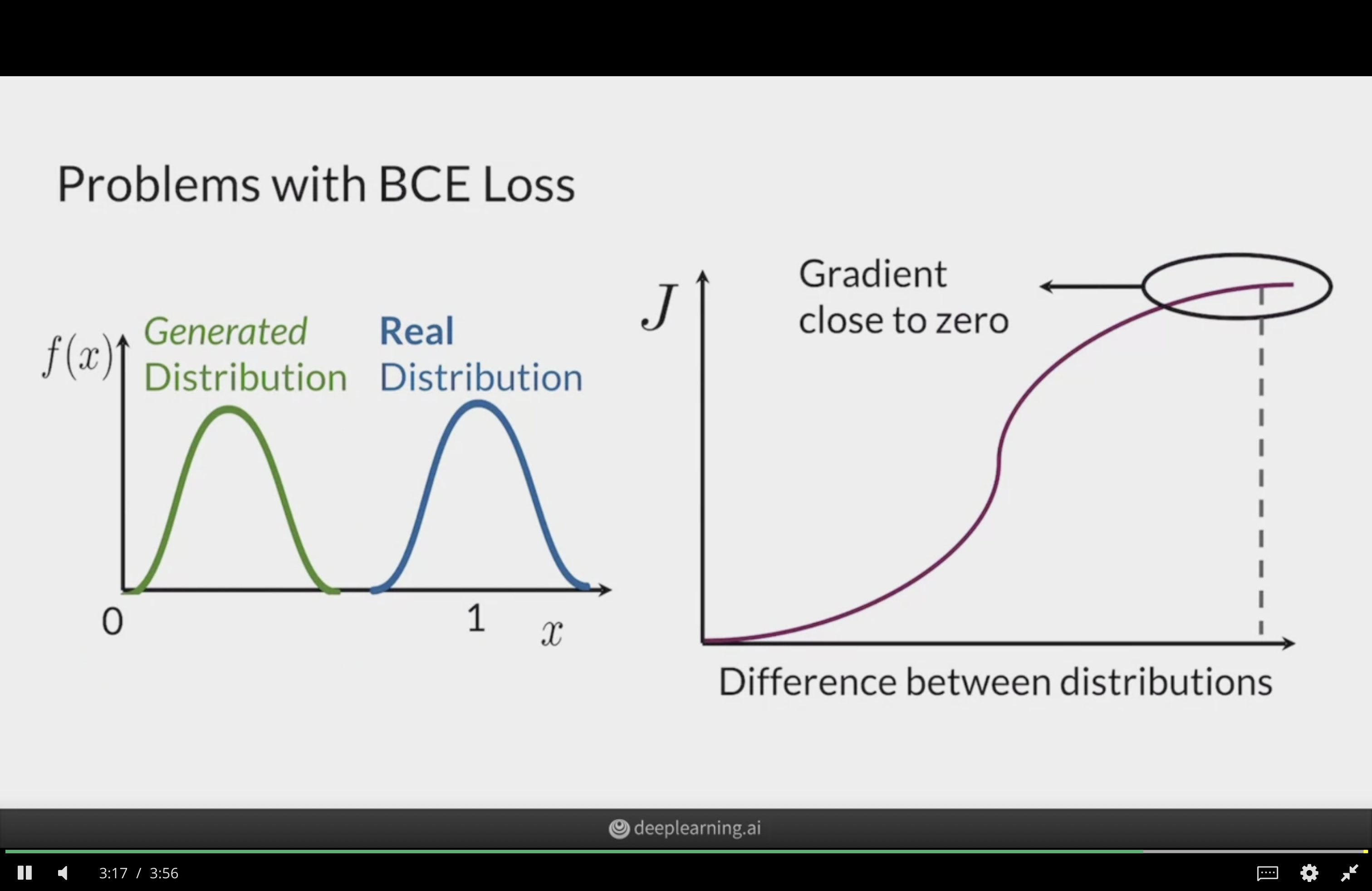
When the discriminator is too good, vanishing gradients
Vanishing gradients (II)

Vanishing gradients
Schematic
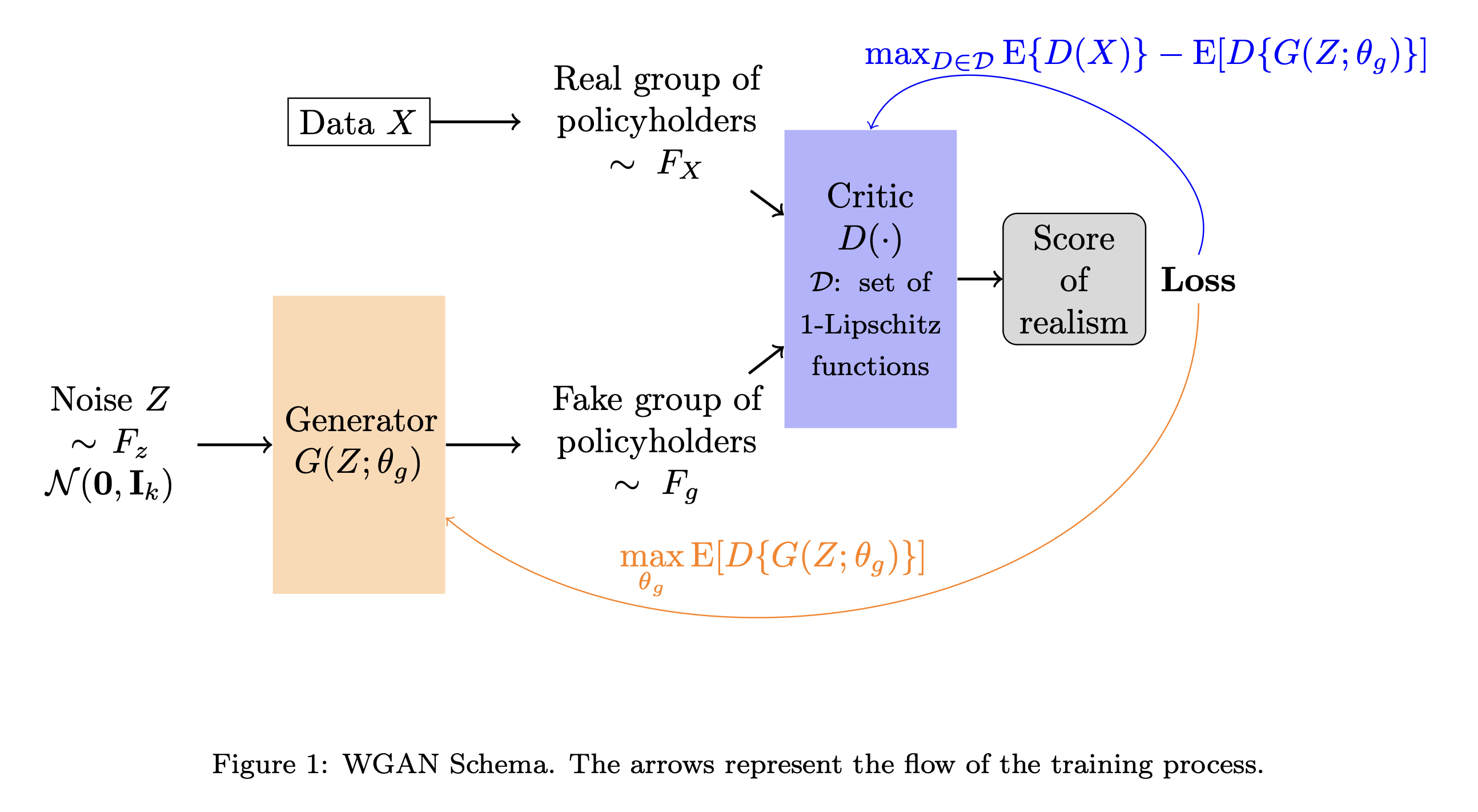
Wasserstein