Linear Regression Recap
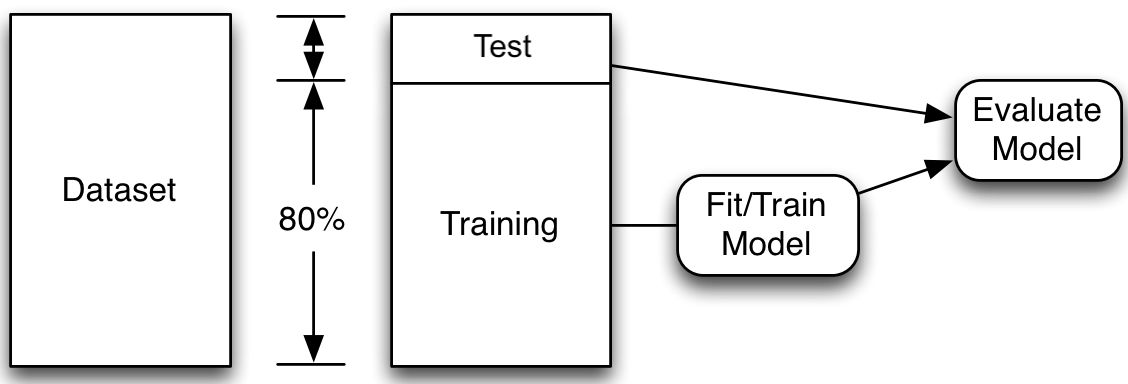
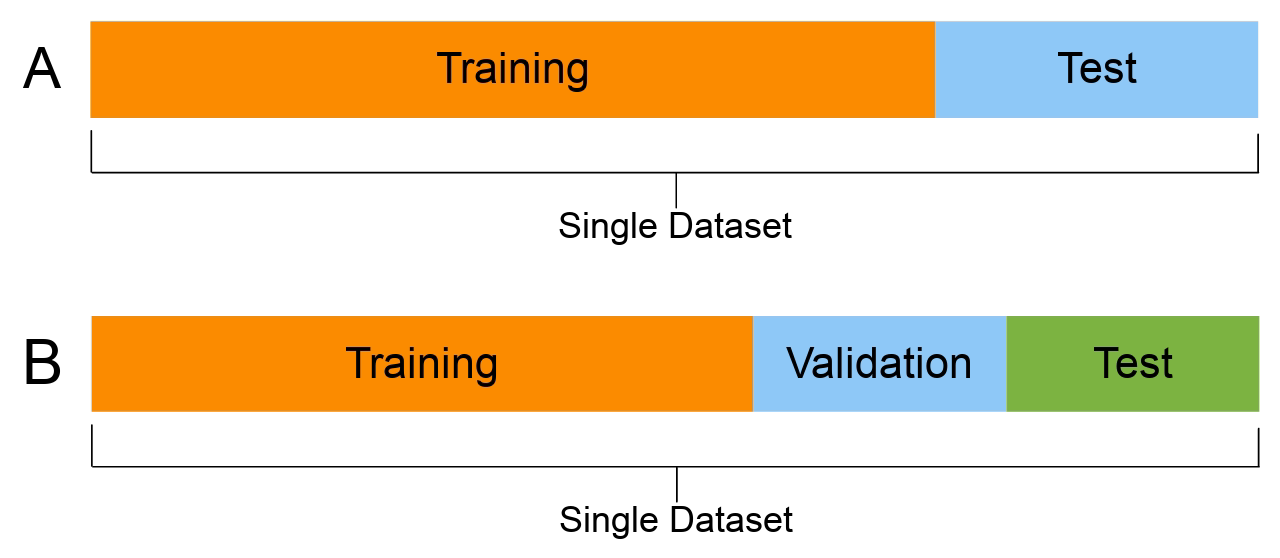
Machine Learning Workflow
Generalised Linear Models Recap
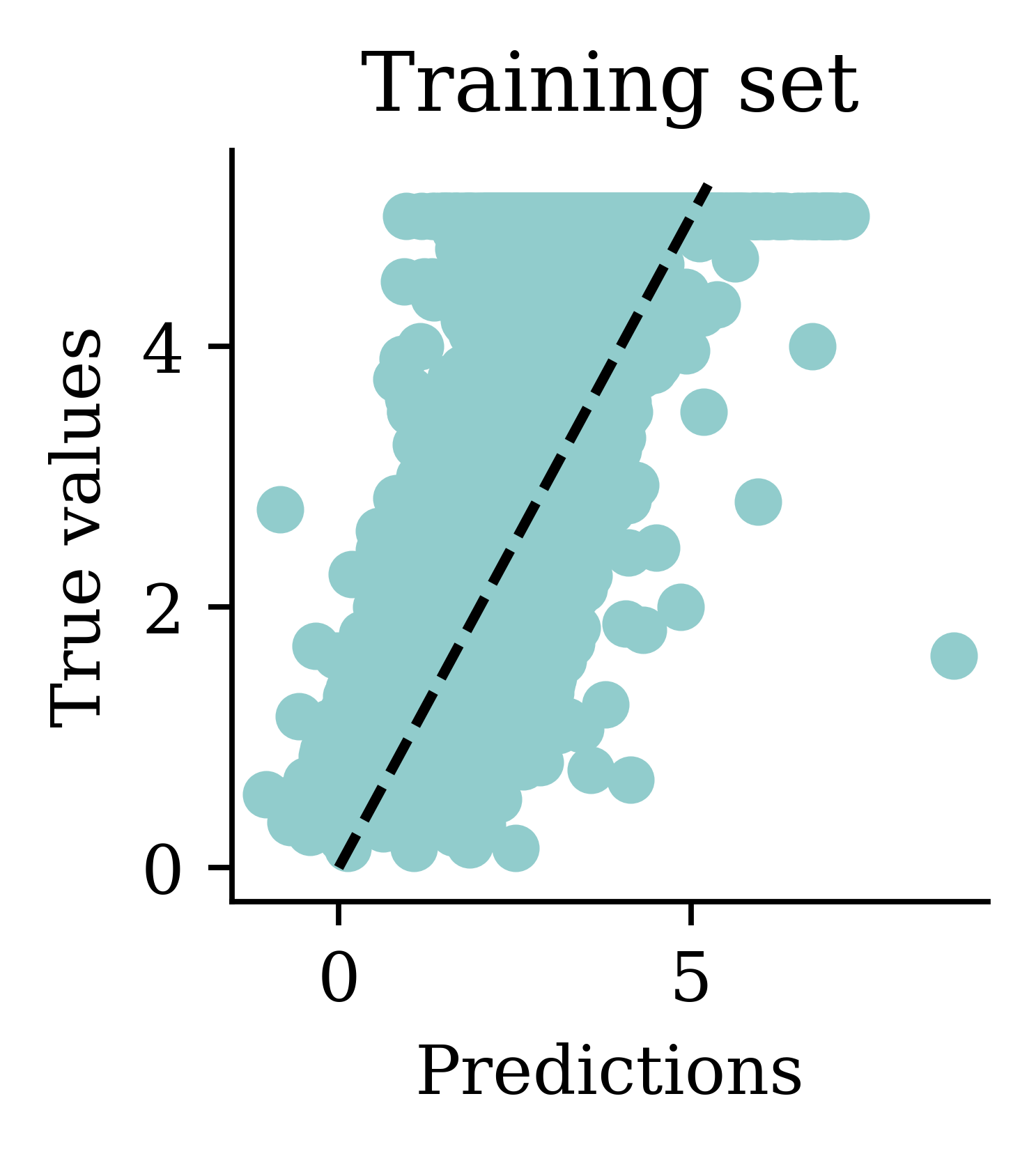
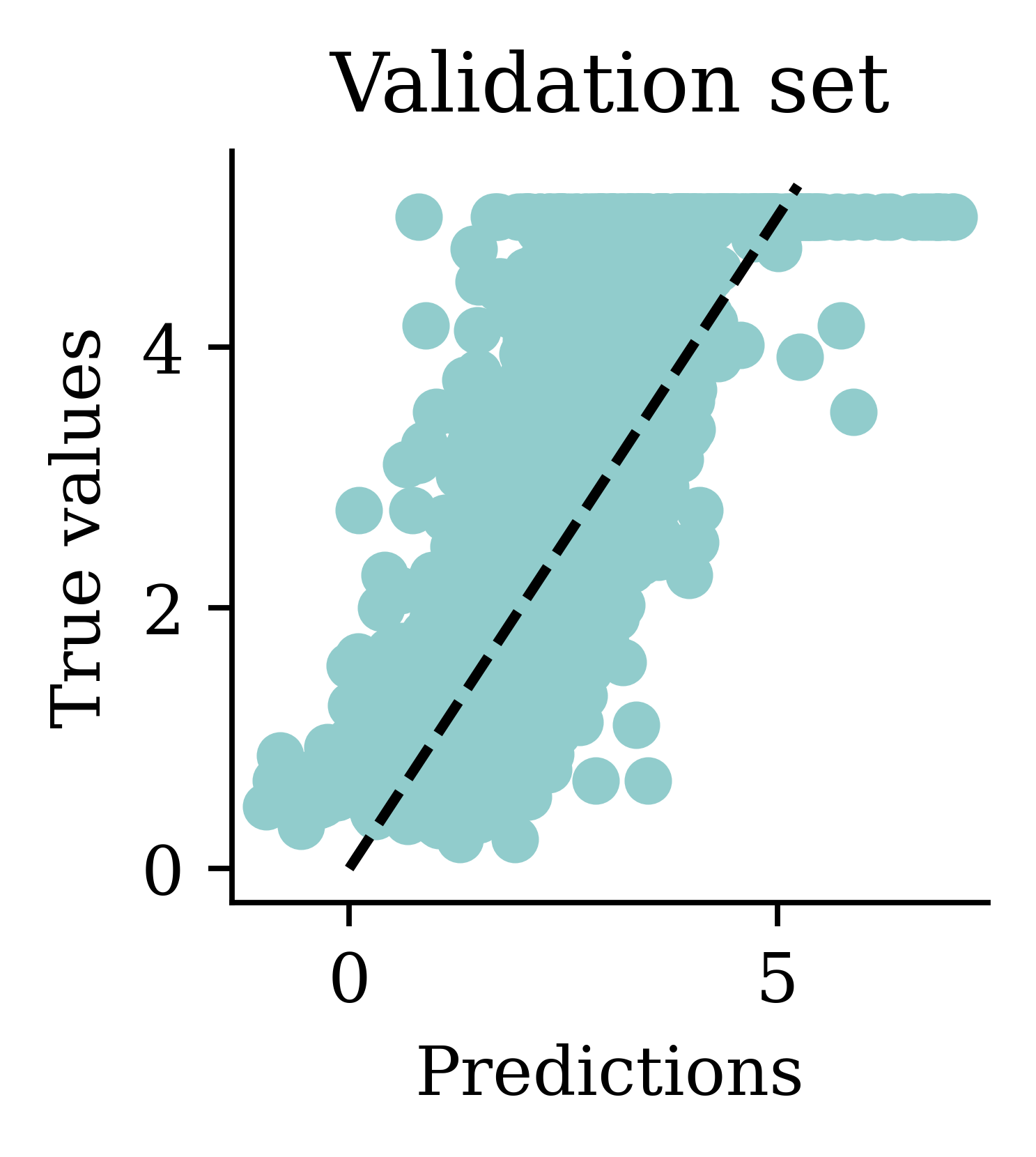
California House Price Prediction (Setup)
California House Price Prediction (Regression)
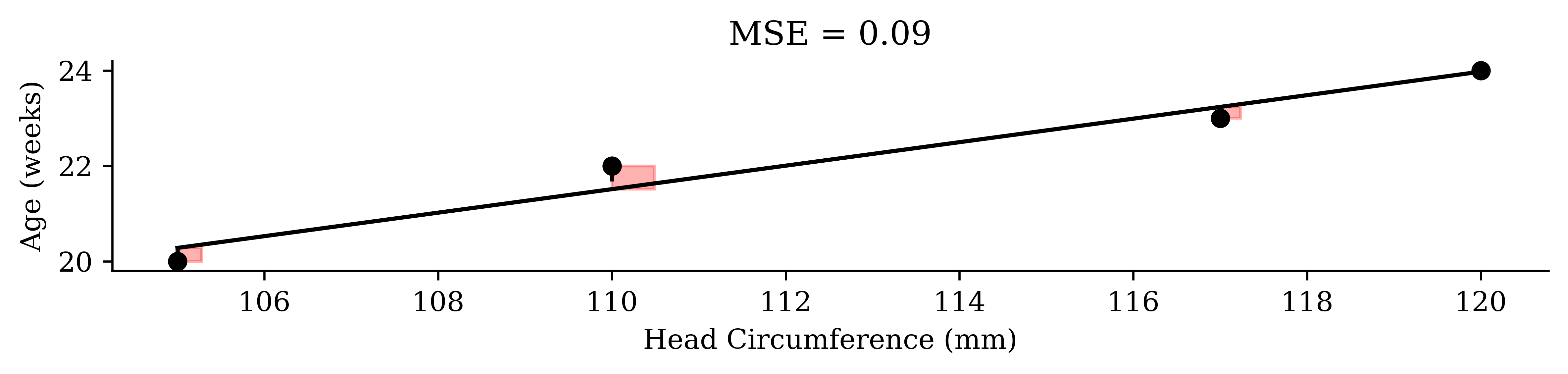
Single Linear Regression (SLR)
Scenario: use head circumference (mm) to predict age (weeks) of a fetal baby
\boldsymbol{x} = \begin{pmatrix}
105 \\
120 \\
110 \\
117 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
20 \\
24 \\
22 \\
23 \\
\end{pmatrix}, \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
20.3 \\
24.0 \\
21.5 \\
23.2 \\
\end{pmatrix}
\hat{y}(x) = \beta_0 + \beta_1 x
= pd.DataFrame({"circumference" : [105 , 120 , 110 , 117 ],"age" : [20 , 24 , 22 , 23 ],= babies[["circumference" ]]= babies["age" ]= LinearRegression()
array([20.28, 23.97, 21.51, 23.24])
Mean squared error
\boldsymbol{y} = \begin{pmatrix}
20 \\
24 \\
22 \\
23 \\
\end{pmatrix}, \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
20.3 \\
24.0 \\
21.5 \\
23.2 \\
\end{pmatrix}, \quad \boldsymbol{y} - \hat{\boldsymbol{y}} = \begin{pmatrix}
-0.3 \\
0 \\
0.5 \\
-0.2 \\
\end{pmatrix}.
Code
= model.predict(X)= babies["circumference" ].to_numpy()= babies["age" ].to_numpy()= predicted_age= np.abs(y - yhat)= np.mean(error ** 2 )= plt.subplots(figsize= (8 , 2 ), dpi= 300 )= "black" , zorder= 3 )= np.argsort(x)= "black" )for xi, yi, yhi, ei in zip (x, y, yhat, error):= "--" , color= "black" )= "red" , alpha= 0.3 ))"Head Circumference (mm)" )"Age (weeks)" )f"MSE = { round(mse, 2 )} " )
\text{MSE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 = \frac{1}{4} \Bigl[ (-0.3)^2 + 0^2 + 0.5^2 + (-0.2)^2 \Bigr] = 0.09.
MSE in sklearn
Rather than computing the formula by hand, use mean_squared_error from sklearn.metrics.
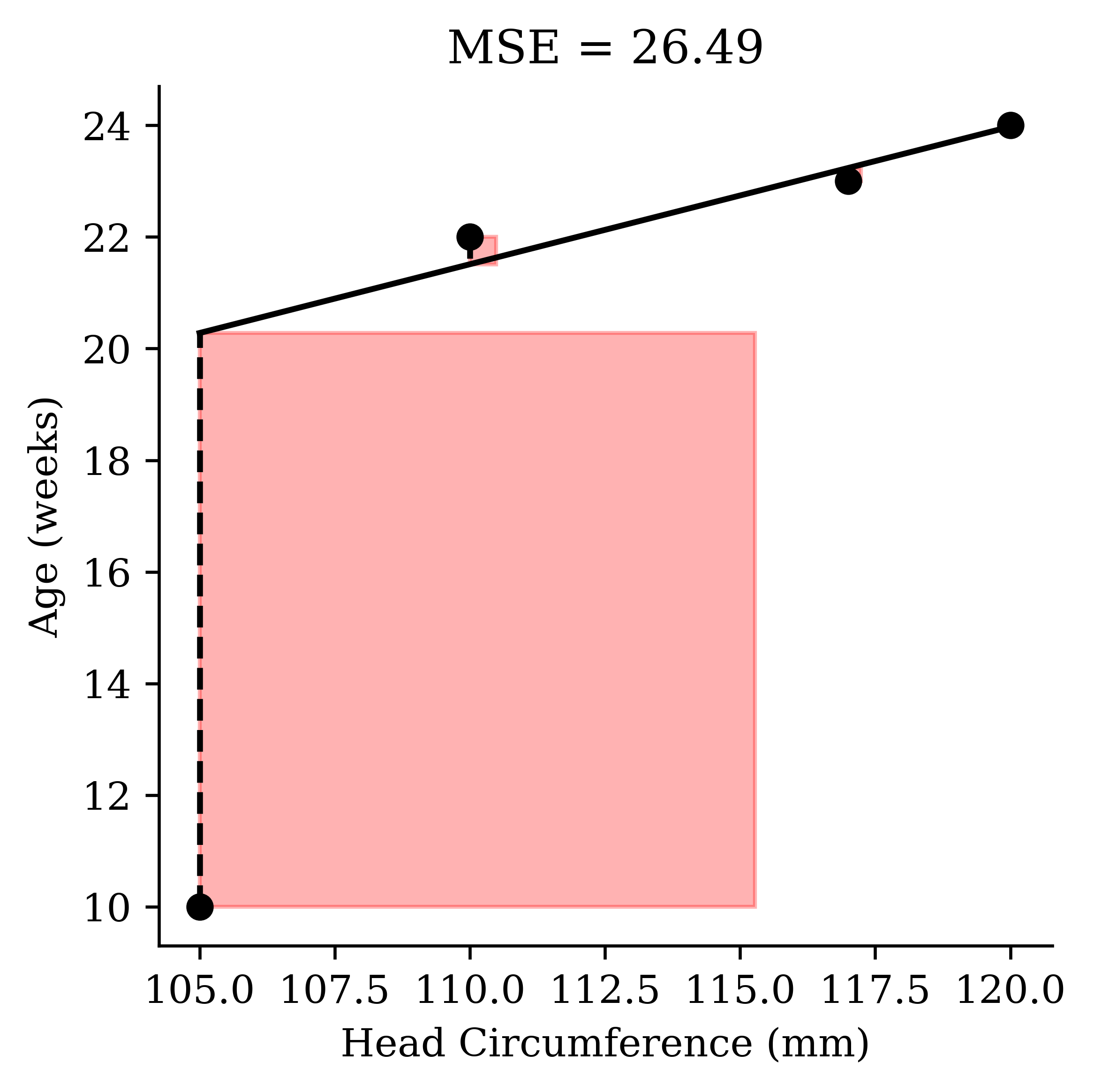
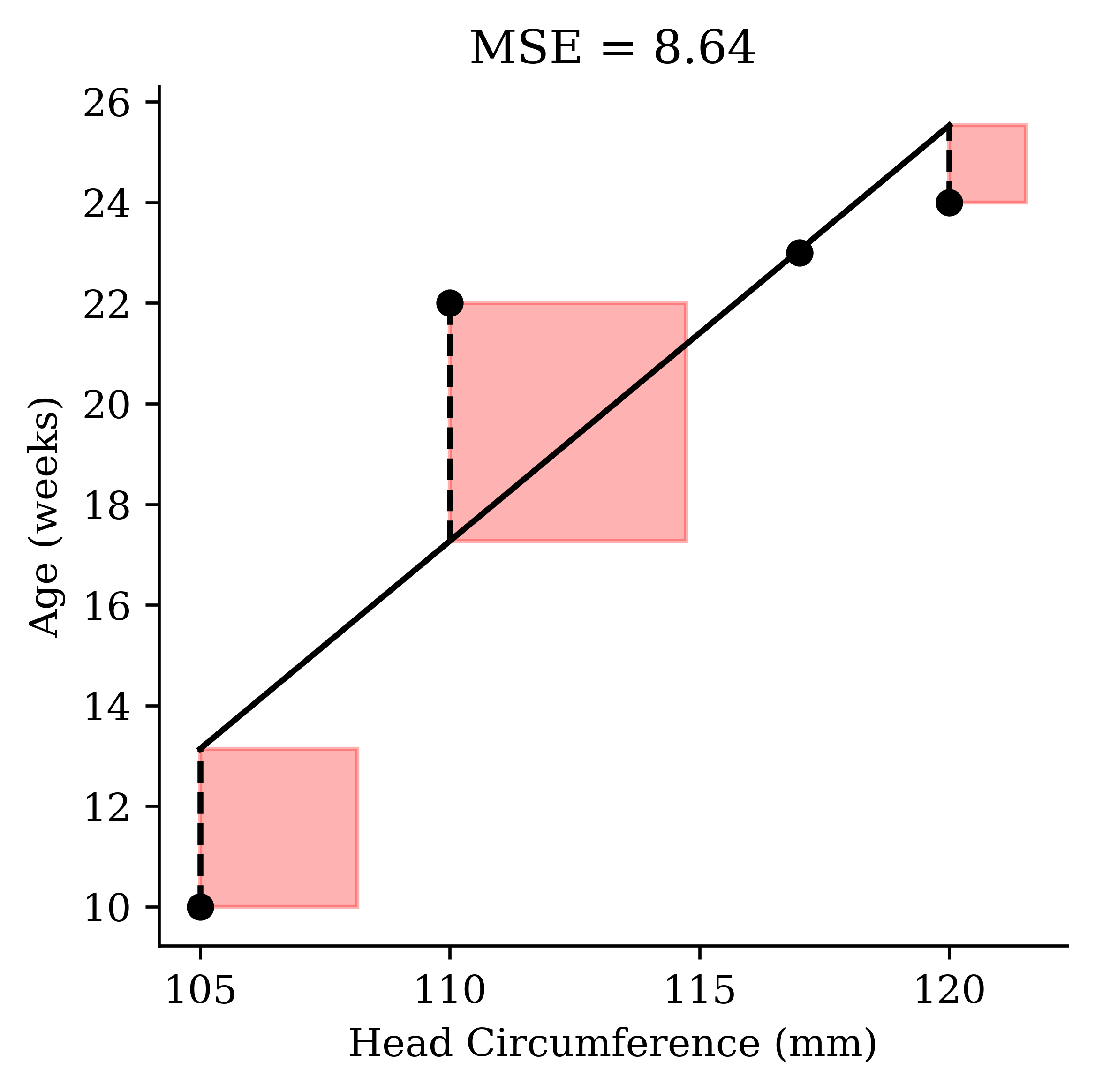
Sensitive to outliers
\text{If we instead had }
\boldsymbol{y} = \begin{pmatrix}
\textcolor{red}{10} & 24 & 22 & 23 \end{pmatrix}^\top.
Code
= pd.DataFrame({"circumference" : [105 , 120 , 110 , 117 ],"age" : [10 , 24 , 22 , 23 ],= babies_outlier[["circumference" ]]= babies_outlier["age" ]# Predictions from the *original* model (before retraining) = model.predict(X)= babies_outlier["circumference" ].to_numpy()= babies_outlier["age" ].to_numpy()= predicted_age= np.abs(y - yhat)= np.mean(error ** 2 )= plt.subplots(figsize= (4 , 4 ), dpi= 300 )= "black" , zorder= 3 )= np.argsort(x)= "black" )for xi, yi, yhi, ei in zip (x, y, yhat, error):= "--" , color= "black" )= "red" , alpha= 0.3 ))"Head Circumference (mm)" )"Age (weeks)" )f"MSE = { round(mse, 2 )} " )
Code
= LinearRegression()= new_model.predict(X)= babies_outlier["circumference" ].to_numpy()= babies_outlier["age" ].to_numpy()= predicted_age= np.abs(y - yhat)= np.mean(error ** 2 )= plt.subplots(figsize= (4 , 4 ), dpi= 300 )= "black" , zorder= 3 )= np.argsort(x)= "black" )for xi, yi, yhi, ei in zip (x, y, yhat, error):= "--" , color= "black" )= "red" , alpha= 0.3 ))"Head Circumference (mm)" )"Age (weeks)" )f"MSE = { round(mse, 2 )} " )
Multiple Linear Regression (MLR)
Scenario: use temperature (^\circ C ) and humidity (%) to predict rainfall (mm)
\boldsymbol{X} = \begin{pmatrix}
27 & 80 \\
32 & 70 \\
28 & 72 \\
22 & 86 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
6 \\
7 \\
6 \\
4 \\
\end{pmatrix}, \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
5.7 \\
7.2 \\
5.9 \\
4.2 \\
\end{pmatrix}
\hat{y}(\boldsymbol{x}) = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \dots + \beta_p x_p = \beta_0 + \left \langle \boldsymbol{\beta}, \boldsymbol{x} \right \rangle
= pd.DataFrame({"temperature" : [27 , 32 , 28 , 22 ],"humidity" : [80 , 70 , 72 , 86 ],"rainfall" : [6 , 7 , 6 , 4 ]= df[["temperature" , "humidity" ]]= df["rainfall" ]= LinearRegression()
array([5.74, 7.2 , 5.88, 4.18])
Predict by hand
The intercept \beta_0 is in model.intercept_ and the slopes \beta_1, \dots, \beta_p are in model.coef_.
model.predict(X) gives us:
array([5.74, 7.2 , 5.88, 4.18])
We can reproduce the first entry with a for loop:
= model.intercept_for beta_j, x_0j in zip (model.coef_, X.iloc[0 ]):+= beta_j * x_0j
np.float64(5.739526411657559)
MLR’s design matrix
Scenario: use temperature (^\circ C ) and humidity (%) to predict rainfall (mm)
\boldsymbol{X} = \begin{pmatrix}
\textcolor{grey}{1} & 27 & 80 \\
\textcolor{grey}{1} & 32 & 70 \\
\textcolor{grey}{1} & 28 & 72 \\
\textcolor{grey}{1} & 22 & 86 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
6 \\
7 \\
6 \\
4 \\
\end{pmatrix}, \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
5.7 \\
7.2 \\
5.9 \\
4.2 \\
\end{pmatrix}
\hat{y}(\boldsymbol{x}) = \beta_0 x_0 + \beta_1 x_1 + \beta_2 x_2 + \dots + \beta_p x_p = \langle \boldsymbol{\beta}, \boldsymbol{x} \rangle
[[27 80]
[32 70]
[28 72]
[22 86]]
= np.column_stack([np.ones(len (X)), X.to_numpy()])print (X_des)
[[ 1. 27. 80.]
[ 1. 32. 70.]
[ 1. 28. 72.]
[ 1. 22. 86.]]
MLR is just matrix equations
\boldsymbol{\beta} = (\boldsymbol{X}^\top\boldsymbol{X})^{-1} \boldsymbol{X}^\top \boldsymbol{y}
= LinearRegression()print (model.intercept_, model.coef_)
-5.5100182149362436 [0.34 0.03]
= np.linalg.solve(@ X_des, X_des.T @ y)
array([-5.51, 0.34, 0.03])
\hat{\boldsymbol{y}} = \boldsymbol{X} \boldsymbol{\beta}.
array([5.74, 7.2 , 5.88, 4.18])
array([5.74, 7.2 , 5.88, 4.18])
Note, you should just use the left column. The right column’s version is for pedagogical purposes (I’ll do this kind of thing again in the upcoming slides).
Changing the base case
Scenario: use property type to predict its sale price ($)
\boldsymbol{x} = \begin{pmatrix}
\textcolor{red}{\text{Unit}} \\
\textcolor{green}{\text{TownHouse}} \\
\textcolor{green}{\text{TownHouse}} \\
\textcolor{blue}{\text{House}} \\
\end{pmatrix} \longrightarrow \boldsymbol{X} = \begin{pmatrix}
\textcolor{grey}{1} & 0 & 0 \\
\textcolor{grey}{1} & 1 & 0 \\
\textcolor{grey}{1} & 1 & 0 \\
\textcolor{grey}{1} & 0 & 1 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
300000 \\
500000 \\
510000 \\
700000 \\
\end{pmatrix}, \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
300000 \\
505000 \\
505000 \\
700000 \\
\end{pmatrix}
\hat{y}(x) = \beta_0 + \beta_1 \underbrace{I(x = \textcolor{green}{\text{TownHouse}})}_{=: x_1} + \beta_2 \underbrace{I(x = \textcolor{blue}{\text{House}})}_{=: x_2} = \beta_0 + \beta_1 x_1 + \beta_2 x_2
"type" ] = df["type" ].cat.reorder_categories(["Unit" , "TownHouse" , "House" ])= pd.get_dummies(df["type" ], drop_first= True , dtype= int )= LinearRegression()print (model.intercept_, model.coef_, model.predict(X))
299999.99999999994 [205000. 400000.] [300000. 505000. 505000. 700000.]
Changing the target’s units
Scenario: use property type to predict its sale price ($000,000’s)
\boldsymbol{x} = \begin{pmatrix}
\textcolor{red}{\text{Unit}} \\
\textcolor{green}{\text{TownHouse}} \\
\textcolor{green}{\text{TownHouse}} \\
\textcolor{blue}{\text{House}} \\
\end{pmatrix} \longrightarrow \boldsymbol{X} = \begin{pmatrix}
\textcolor{grey}{1} & 0 & 0 \\
\textcolor{grey}{1} & 1 & 0 \\
\textcolor{grey}{1} & 1 & 0 \\
\textcolor{grey}{1} & 0 & 1 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
0.3 \\
0.5 \\
0.51 \\
0.7 \\
\end{pmatrix}, \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
0.3 \\
0.505 \\
0.505 \\
0.7 \\
\end{pmatrix}
\hat{y}(x) = \beta_0 + \beta_1 \underbrace{I(x = \textcolor{green}{\text{TownHouse}})}_{=: x_1} + \beta_2 \underbrace{I(x = \textcolor{blue}{\text{House}})}_{=: x_2} = \beta_0 + \beta_1 x_1 + \beta_2 x_2
"price" ] /= 1e6 = df["price" ]= LinearRegression()print (model.intercept_, model.coef_, model.predict(X))
0.2999999999999999 [0.21 0.4 ] [0.3 0.51 0.51 0.7 ]
Generalised Linear Models Recap
Machine Learning Workflow
Generalised Linear Models Recap
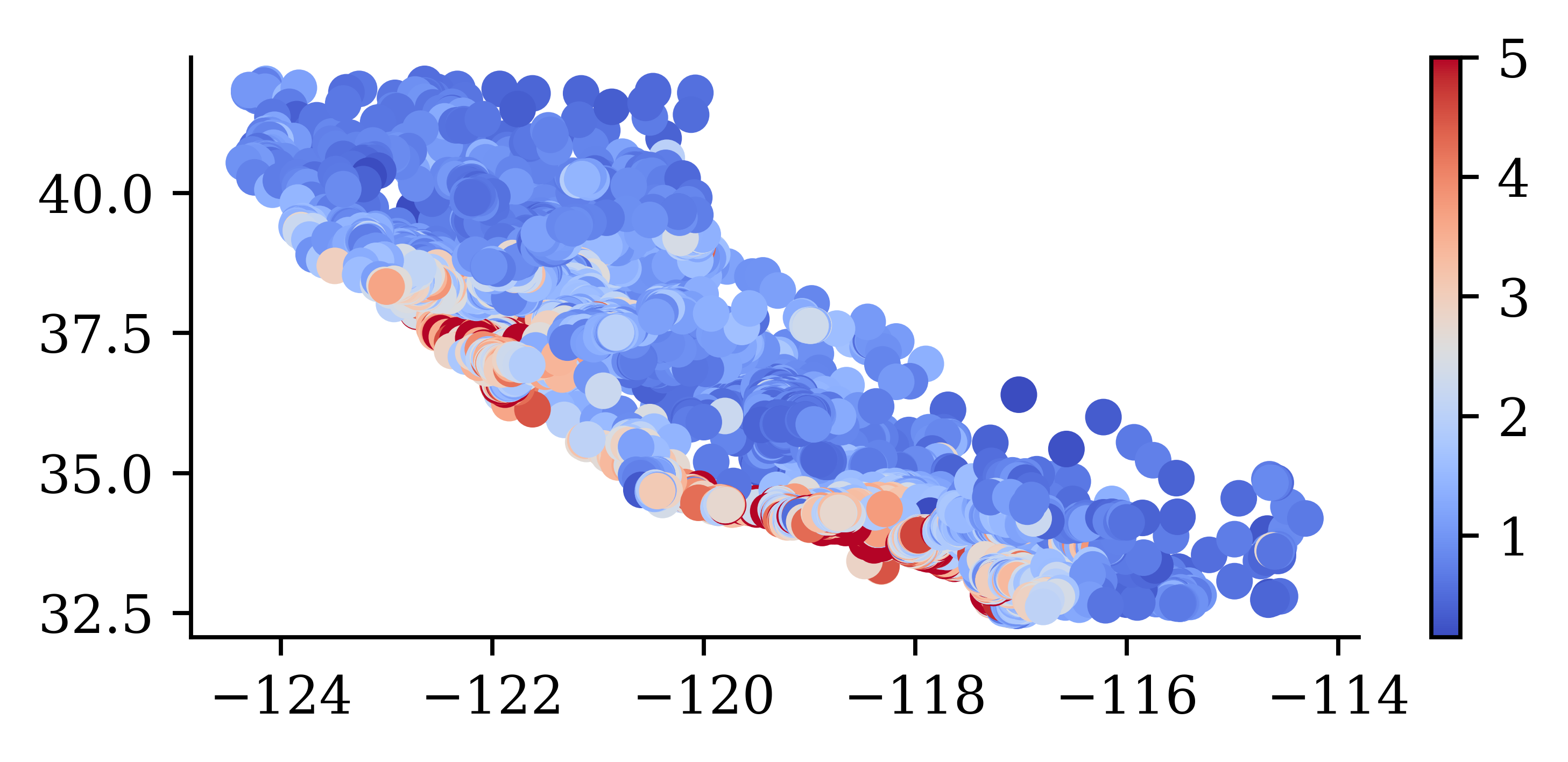
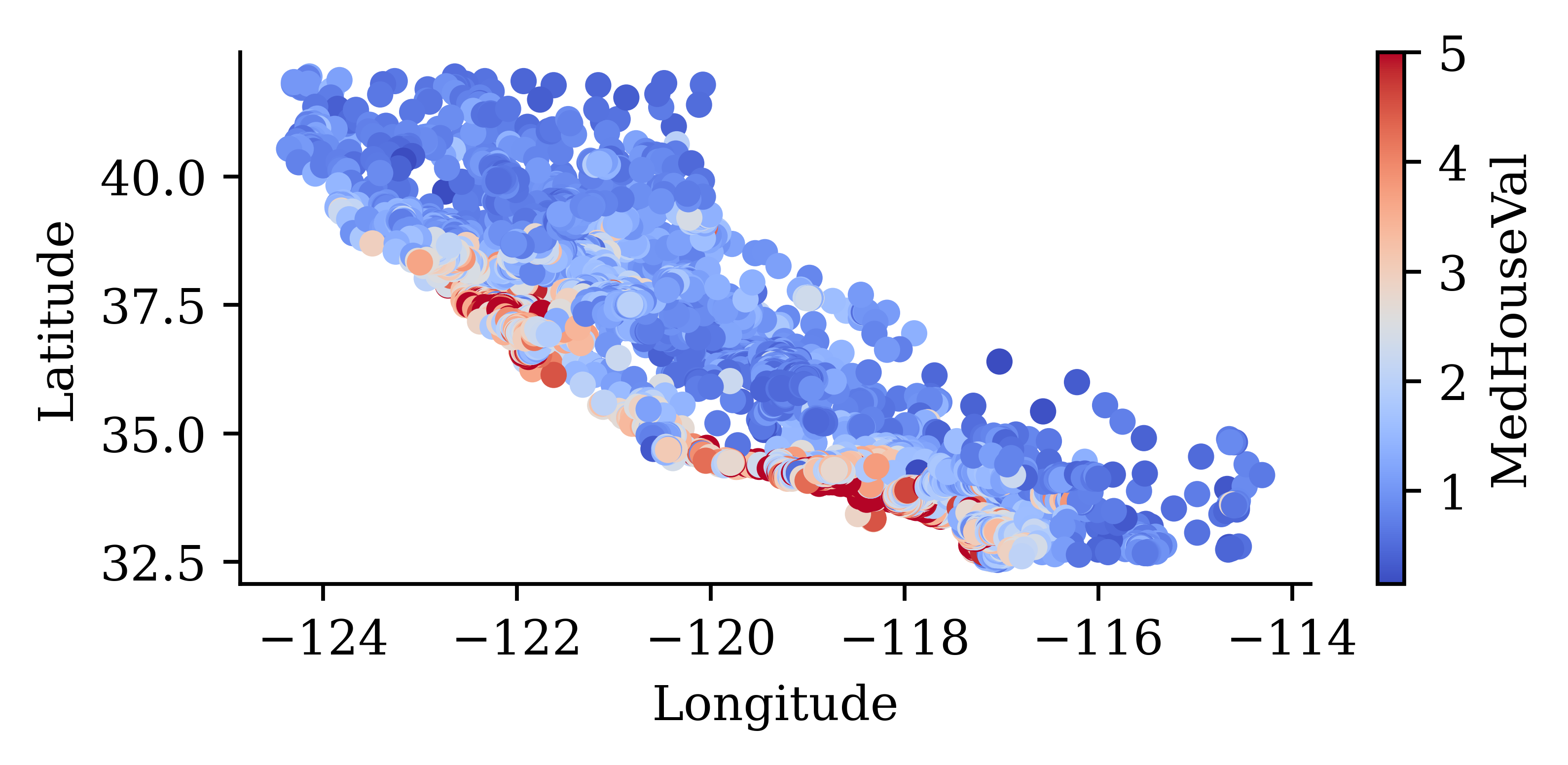
California House Price Prediction (Setup)
California House Price Prediction (Regression)
MLR with categorical targets
Scenario: use tumour radius (mm) and ages (years) to predict benign or malignant
\boldsymbol{X} = \begin{pmatrix}
\textcolor{grey}{1} & 14.8 & 48 \\
\textcolor{grey}{1} & 16.4 & 49 \\
\textcolor{grey}{1} & 15.5 & 47 \\
\textcolor{grey}{1} & 14.2 & 46 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
\text{Benign} \\
\text{Malignant} \\
\text{Benign} \\
\text{Malignant} \\
\end{pmatrix}, \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
? \\
? \\
? \\
? \\
\end{pmatrix}
Step 1: Make a linear prediction \beta_0 + \beta_1 x_1 + \dots + \beta_p x_p , \quad \text{a.k.a.} \quad \langle \boldsymbol{\beta}, \boldsymbol{x} \rangle.
Step 2: Shove it through some function to make it a probability \sigma(\langle \boldsymbol{\beta}, \boldsymbol{x} \rangle) Interpret that as being the probability of the positive class.
Step 3: Make a decision based on that probability. E.g., if the probability is greater than 0.5, predict the positive class.
Binomial regression with sklearn
Scenario: use tumour radius (mm) and ages (years) to predict benign or malignant
\boldsymbol{y} = \begin{pmatrix}
\text{Benign} \\
\textbf{\text{Malignant}} \\
\text{Benign} \\
\textbf{\text{Malignant}} \\
\end{pmatrix}, \quad \sigma( \boldsymbol{X} \boldsymbol{\beta} ) = \begin{pmatrix}
39\% \\
55\% \\
59\% \\
48\% \\
\end{pmatrix} , \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
\text{Benign} \\
\text{Malignant} \\
\text{Malignant} \\
\text{Benign} \\
\end{pmatrix}
Load the data, fit a GLM, make predictions:
= pd.DataFrame({"radius" : [14.8 , 16.4 , 15.5 , 14.2 ],"age" : [48 , 49 , 47 , 46 ],"tumour" : ["Benign" , "Malignant" , "Benign" , "Malignant" ],= patients[["radius" , "age" ]]= patients["tumour" ]= LogisticRegression(C= np.inf)
array(['Benign', 'Malignant', 'Malignant', 'Benign'], dtype=object)
Binomial regression I
Scenario: use tumour radius (mm) and ages (years) to predict benign or malignant
\boldsymbol{X} = \begin{pmatrix}
\textcolor{grey}{1} & 14.8 & 48 \\
\textcolor{grey}{1} & 16.4 & 49 \\
\textcolor{grey}{1} & 15.5 & 47 \\
\textcolor{grey}{1} & 14.2 & 46 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
\text{Benign} \\
\textbf{\text{Malignant}} \\
\text{Benign} \\
\textbf{\text{Malignant}} \\
\end{pmatrix}, \quad \boldsymbol{X} \boldsymbol{\beta} = \begin{pmatrix}
-0.46 \\
0.18 \\
0.37 \\
-0.09 \\
\end{pmatrix}
= LogisticRegression(C= np.inf);
Step 1: Make a linear prediction
= model.decision_function(X)
array([-0.46, 0.18, 0.37, -0.09])
= np.column_stack([np.ones(len (X)), X.to_numpy()])= np.concatenate([model.intercept_, model.coef_.flatten()])@ beta
array([-0.46, 0.18, 0.37, -0.09])
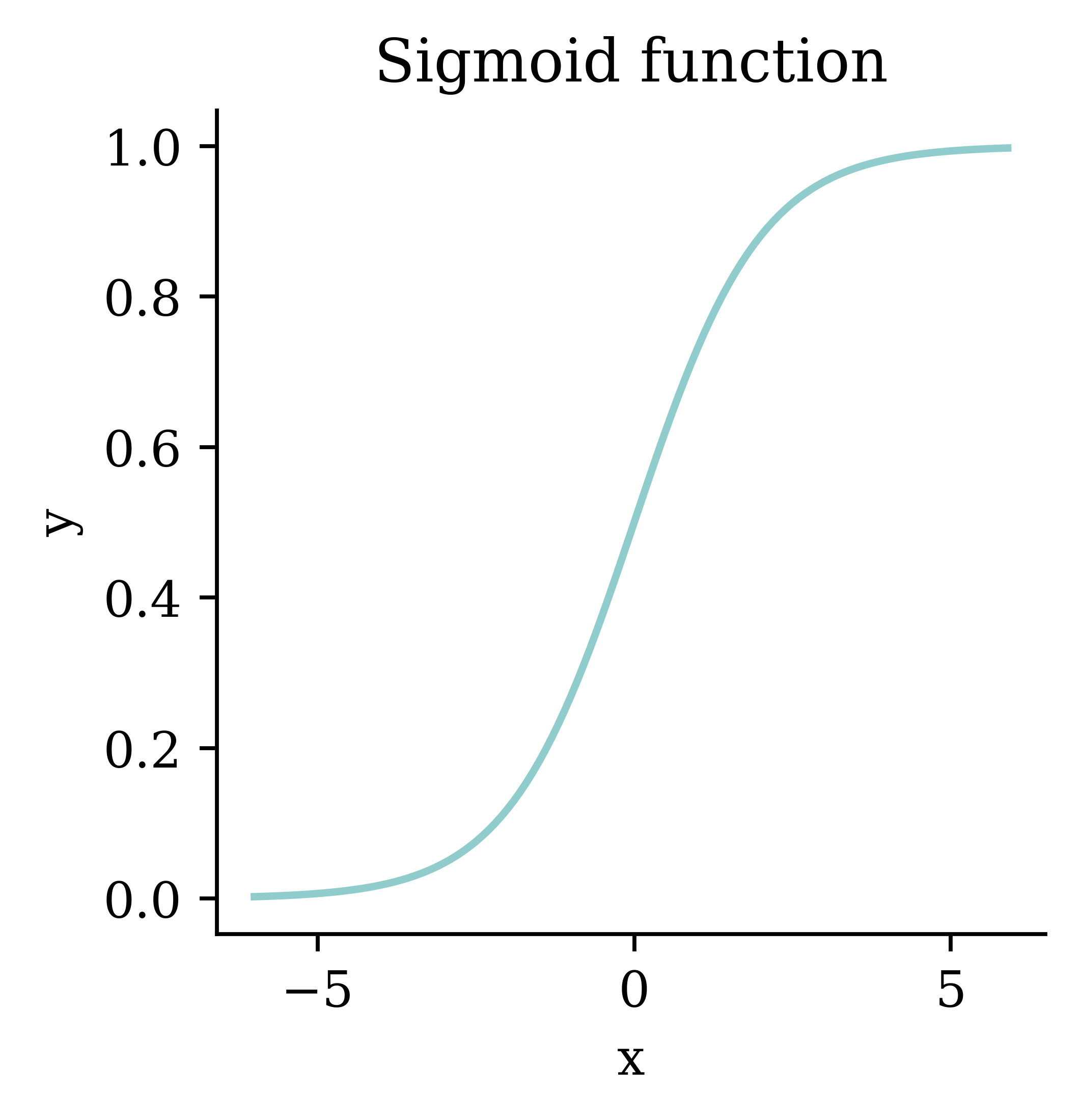
Logistic regression and probit regression
Code
def sigmoid(x):return 1 / (1 + np.exp(- x))= np.arange(- 6 , 6 , 0.1 )= sigmoid(xs)= plt.subplots(figsize= (3 , 3 ))= 1.5 )"x" )"y" )"Sigmoid function" )
This give you logistic regression .
Code
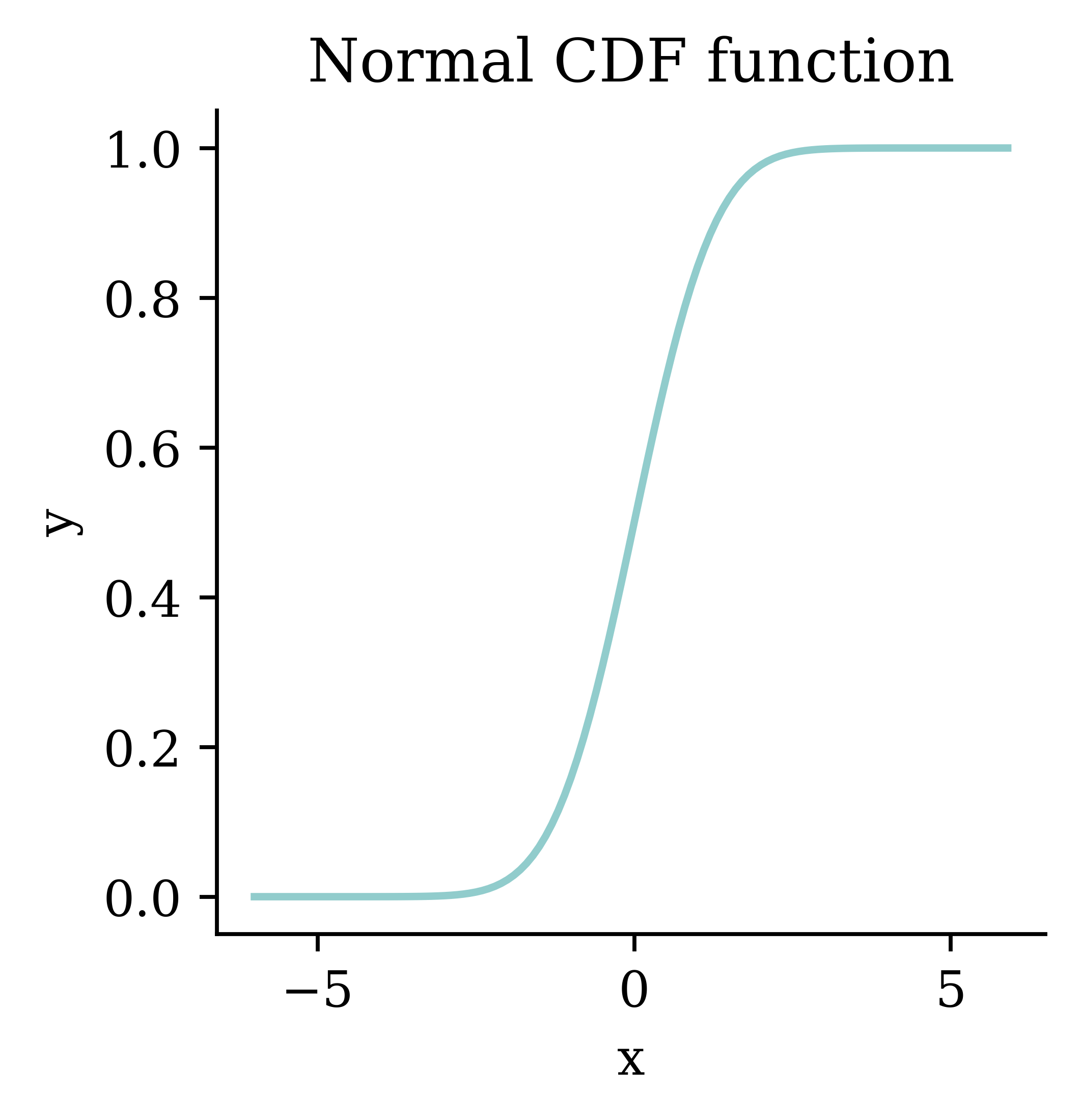
from scipy.stats import norm= np.arange(- 6 , 6 , 0.1 )= norm.cdf(xs)= plt.subplots(figsize= (3 , 3 ))= 1.5 )"x" )"y" )"Normal CDF function" )
This gives you probit regression .
Logistic Regression
Scenario: use tumour radius (mm) and ages (years) to predict benign or malignant
\boldsymbol{y} = \begin{pmatrix}
\text{Benign} \\
\textbf{\text{Malignant}} \\
\text{Benign} \\
\textbf{\text{Malignant}} \\
\end{pmatrix}, \quad \boldsymbol{X} \boldsymbol{\beta} = \begin{pmatrix}
-0.46 \\
0.18 \\
0.37 \\
-0.09 \\
\end{pmatrix}, \quad \sigma( \boldsymbol{X} \boldsymbol{\beta} ) = \begin{pmatrix}
39\% \\
55\% \\
59\% \\
48\% \\
\end{pmatrix}
= LogisticRegression(C= np.inf)= model.decision_function(X)
Step 2: Shove it through some function to make it a probability
array([0.39, 0.55, 0.59, 0.48])
1 ] # Probability of the positive class (Malignant)
array([0.39, 0.55, 0.59, 0.48])
Predicting categories
Scenario: use tumour radius (mm) and ages (years) to predict benign or malignant
\boldsymbol{y} = \begin{pmatrix}
\text{Benign} \\
\textbf{\text{Malignant}} \\
\text{Benign} \\
\textbf{\text{Malignant}} \\
\end{pmatrix}, \quad \sigma( \boldsymbol{X} \boldsymbol{\beta} ) = \begin{pmatrix}
39\% \\
55\% \\
59\% \\
48\% \\
\end{pmatrix} , \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
\text{Benign} \\
\text{Malignant} \\
\text{Malignant} \\
\text{Benign} \\
\end{pmatrix}
= LogisticRegression(C= np.inf);
= model.predict_proba(X)[:, 1 ]= 0.5 = np.where(predict_probs > cutoff, "Malignant" , "Benign" )print (predicted_tumours)
['Benign' 'Malignant' 'Malignant' 'Benign']
Assessing accuracy in classification problems
Scenario: use tumour radius (mm) and ages (years) to predict benign or malignant
\boldsymbol{y} = \begin{pmatrix}
\textcolor{Green}{\text{Benign}} \\
\textcolor{Green}{\text{Malignant}} \\
\textcolor{Red}{\text{Benign}} \\
\textcolor{Red}{\text{Malignant}} \\
\end{pmatrix}, \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
\textcolor{Green}{\text{Benign}} \\
\textcolor{Green}{\text{Malignant}} \\
\textcolor{Red}{\text{Malignant}} \\
\textcolor{Red}{\text{Benign}} \\
\end{pmatrix}
Accuracy: \frac{1}{n}\sum_{i=1}^n I(y_i = \hat{y}_i)
Error rate: \frac{1}{n}\sum_{i=1}^n I(y_i \neq \hat{y}_i)
The word “accuracy” is used often used loosely when discussing models, particularly regression models. In the context of classification it has this specific meaning.
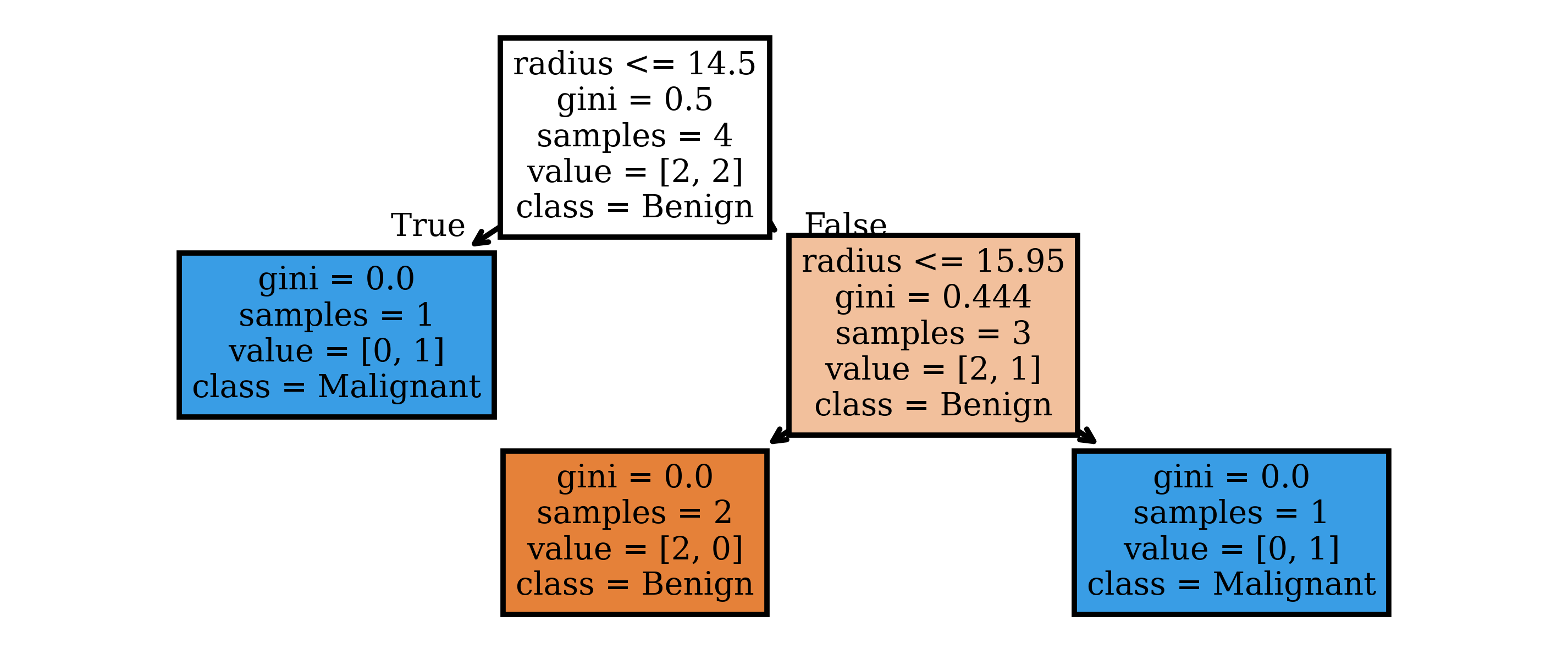
Decision Tree
= DecisionTreeClassifier(min_samples_split= 2 )= list (X.columns), class_names= model.classes_, filled= True );
Poisson regression
Scenario: use population density to predict the daily count of gun violence incidents
\boldsymbol{X} = \begin{pmatrix}
\textcolor{grey}{1} & 10 \\
\textcolor{grey}{1} & 15 \\
\textcolor{grey}{1} & 12 \\
\textcolor{grey}{1} & 18 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
155 \\
208 \\
116 \\
301 \\
\end{pmatrix}, \quad \hat{\boldsymbol{y}} = \begin{pmatrix}
? \\
? \\
? \\
? \\
\end{pmatrix}
Step 1: Make a linear prediction \beta_0 + \beta_1 x_1 + \dots + \beta_p x_p , \quad \text{a.k.a.} \quad \langle \boldsymbol{\beta}, \boldsymbol{x} \rangle.
Step 2: Shove it through some function to make it positive \exp(\langle \boldsymbol{\beta}, \boldsymbol{x} \rangle) Interpret that as being the expected count.
Predict the mean of a Poisson distribution I
Scenario: use population density to predict the daily count of gun violence incidents
\boldsymbol{X} = \begin{pmatrix}
\textcolor{grey}{1} & 10 \\
\textcolor{grey}{1} & 15 \\
\textcolor{grey}{1} & 12 \\
\textcolor{grey}{1} & 18 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
155 \\
208 \\
116 \\
301 \\
\end{pmatrix}, \quad \boldsymbol{X} \boldsymbol{\beta} = \begin{pmatrix}
4.82 \\
5.35 \\
5.03 \\
5.67 \\
\end{pmatrix}, \quad \hat{\boldsymbol{\mu}} = \begin{pmatrix}
125.1 \\
211.3 \\
154.3 \\
289.4 \\
\end{pmatrix}
Load the data, fit the model, and make a prediction.
= pd.DataFrame({"density" : [10 , 15 , 12 , 18 ],"incidents" : [155 , 208 , 116 , 301 ],= guns[["density" ]]= guns["incidents" ]= PoissonRegressor(alpha= 0 )print (model.predict(X))
[125.08 211.28 154.26 289.38]
Predict the mean of a Poisson distribution II
Scenario: use population density to predict the daily count of gun violence incidents
\boldsymbol{X} = \begin{pmatrix}
\textcolor{grey}{1} & 10 \\
\textcolor{grey}{1} & 15 \\
\textcolor{grey}{1} & 12 \\
\textcolor{grey}{1} & 18 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
155 \\
208 \\
116 \\
301 \\
\end{pmatrix}, \quad \boldsymbol{X} \boldsymbol{\beta} = \begin{pmatrix}
4.82 \\
5.35 \\
5.03 \\
5.67 \\
\end{pmatrix}, \quad \hat{\boldsymbol{\mu}} = \begin{pmatrix}
125.1 \\
211.3 \\
154.3 \\
289.4 \\
\end{pmatrix}
These are the linear coefficients:
print (model.intercept_, model.coef_)
Step 1: Make linear predictions
= np.column_stack([np.ones(len (X)), X.to_numpy()])= np.concatenate([[model.intercept_], model.coef_])= X_des @ betaprint (linear)
Predict the mean of a Poisson distribution III
Scenario: use population density to predict the daily count of gun violence incidents
\boldsymbol{X} = \begin{pmatrix}
\textcolor{grey}{1} & 10 \\
\textcolor{grey}{1} & 15 \\
\textcolor{grey}{1} & 12 \\
\textcolor{grey}{1} & 18 \\
\end{pmatrix}, \quad \boldsymbol{y} = \begin{pmatrix}
155 \\
208 \\
116 \\
301 \\
\end{pmatrix}, \quad \boldsymbol{X} \boldsymbol{\beta} = \begin{pmatrix}
4.82 \\
5.35 \\
5.03 \\
5.67 \\
\end{pmatrix}, \quad \hat{\boldsymbol{\mu}} = \begin{pmatrix}
125.1 \\
211.3 \\
154.3 \\
289.4 \\
\end{pmatrix}
Step 2: Exponentiate it
= X_des @ betaprint (np.exp(linear))
[125.08 211.28 154.26 289.38]
array([125.08, 211.28, 154.26, 289.38])






{kind=link}