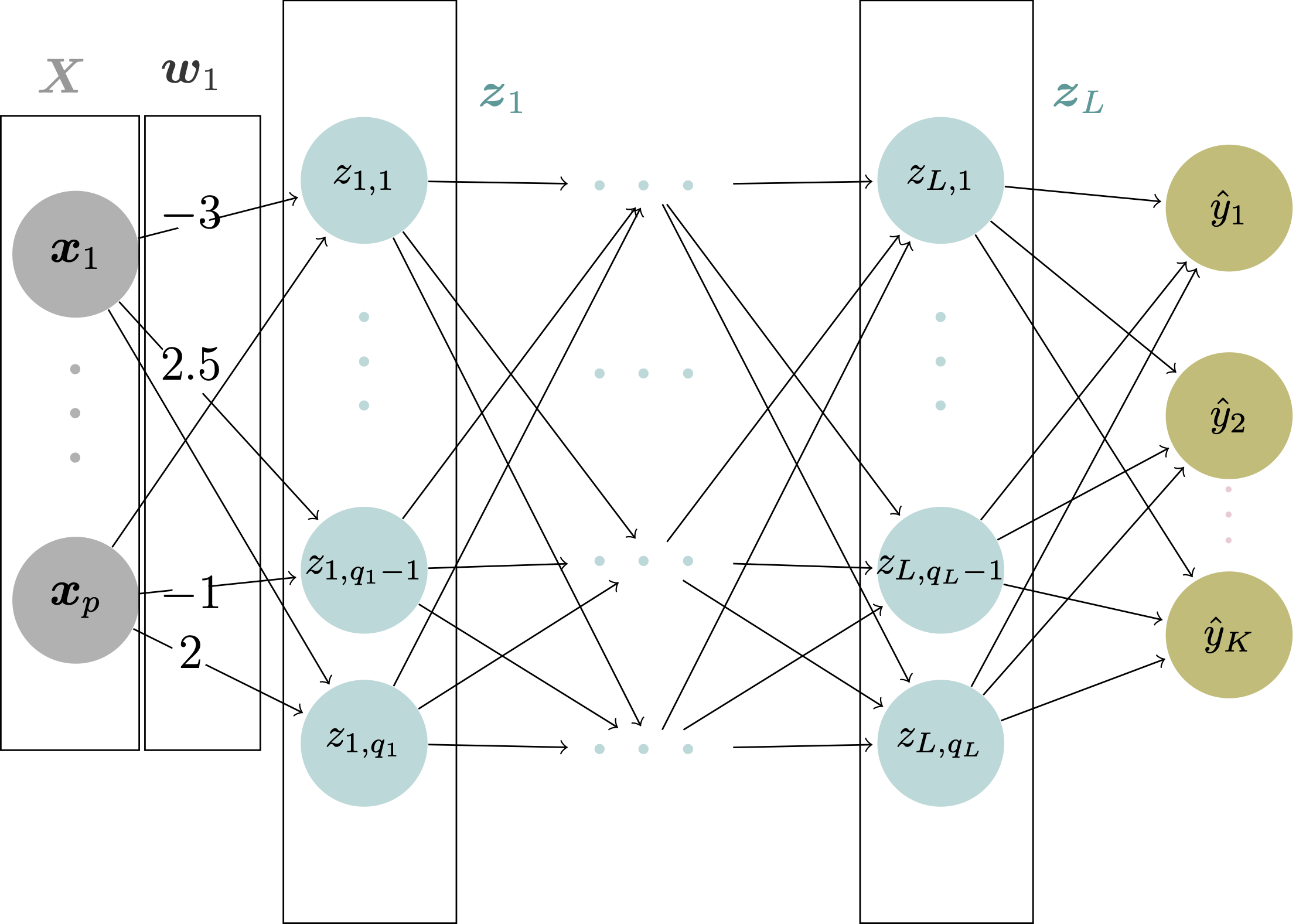
At each node in the hidden and output layers, the value \boldsymbol{z} is calculated as a weighted sum of the node outputs in the previous layer, plus a bias. In other words: \boldsymbol{z} = \boldsymbol{X}\boldsymbol{w} + \boldsymbol{b} where \boldsymbol{X} is a n \times p matrix representing the weights, \boldsymbol{w} is an p \times q matrix representing the weights (q representing the number of neurons in the current layer), and \boldsymbol{b} is an n \times q matrix representing the biases. n represents the number of observations and p represents the dimension of the input.
Example: Calculate the Neuron Values in the First Hidden Layer
If \boldsymbol{X} is a 2\times 3 matrix, what does this say about the neural network’s architecture? What about a 3\times2 matrix?
Activation Functions
The result of \boldsymbol{z} = \boldsymbol{X}\boldsymbol{w} + \boldsymbol{b} will be in the range (-\infty, \infty). However, sometimes we might want to constrain the values of \boldsymbol{z}. We apply an to \boldsymbol{z} to do this. Activation functions include:
Sigmoid: S(z_i) = \frac{1}{1 + \mathrm{e}^{-z_i}}, constrains each value in \boldsymbol{z} to (0, 1)
Tanh: \text{tanh}(z_i) = \frac{\mathrm{e}^{2z_i} - 1}{\mathrm{e}^{2z_i} + 1}, constrains each value in \boldsymbol{z} to (-1, 1).
ReLU: \text{ReLU}(z_i) = \max(0, z_i), only activates for a value of \boldsymbol{z} if it is positive.
Softmax: \sigma(z_i) = \frac{\mathrm{e}^{z_i}}{\Sigma_{j = 1}^{K}\mathrm{e}^{
z_j}}. This maps the values in \boldsymbol{z} so that each value is in [0,1] and the sum is equal to 1. This is useful for representing probabilities and is often used for the output layer.
Example: Applying Activation Functions
Given \boldsymbol{z} = \begin{pmatrix}
1 \\ 8
\end{pmatrix}, calculate the resulting vector \boldsymbol{a} = \text{activation}(\boldsymbol{z}) using the four activation functions above.
Given \boldsymbol{z} = \begin{pmatrix} 8 \\ 6\end{pmatrix}, calculate the resulting vector \boldsymbol{a} = \text{activation}(\boldsymbol{z}) using the four activation functions above.
Given \boldsymbol{z} = \begin{pmatrix} -8 \\ 9 \\ -3\end{pmatrix}, calculate the resulting vector \boldsymbol{a} = \text{activation}(\boldsymbol{z}) using the four activation functions above.
For extra practice, try calculating the vector \boldsymbol{a}, using the results of the exercises in section 1.
Final Output
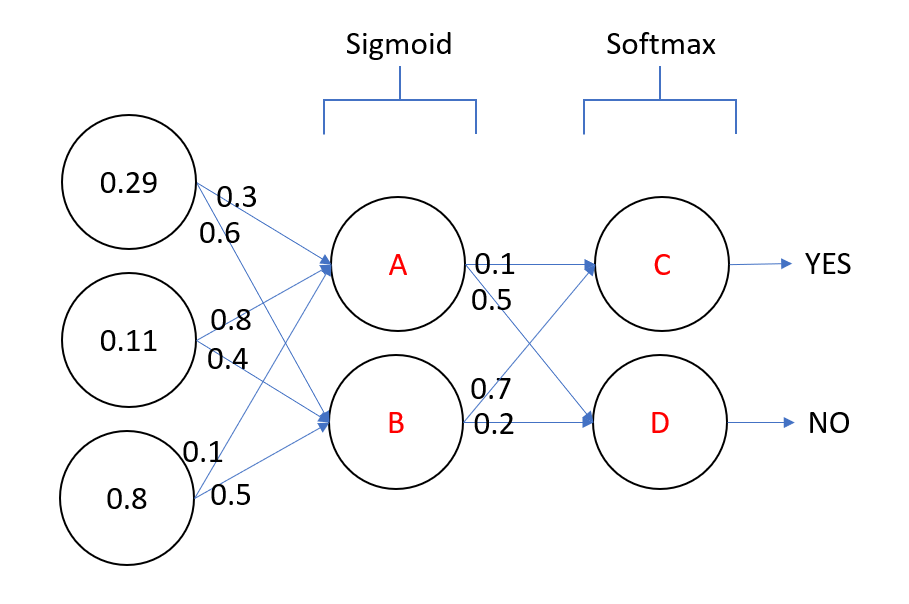
Example: Calculate the Final Output
With the activations, weights, and activation functions given in the above figure and a constant bias of 1 for each node, calculate the values of A, B, C, and D.
If the C node represents “YES” and the D node represents “NO”, what final value is predicted by the neural network?