We have a dataset \{ \boldsymbol{x}_i, y_i \}_{i=1}^n which we assume are i.i.d. observations.
Brand
Mileage
# Claims
BMW
101 km
1
Audi
432 km
0
Volvo
3 km
5
\vdots
\vdots
\vdots
The goal is to predict the y for some covariates \boldsymbol{x}.
Time series data
Have a sequence \{ \boldsymbol{x}_t, y_t \}_{t=1}^T of observations taken at regular time intervals.
Date
Humidity
Temp.
Jan 1
60%
20 °C
Jan 2
65%
22 °C
Jan 3
70%
21 °C
\vdots
\vdots
\vdots
The task is to forecast future values based on the past.
Attributes of time series data
Temporal ordering: The order of the observations matters.
Trend: The general direction of the data.
Noise: Random fluctuations in the data.
Seasonality: Patterns that repeat at regular intervals.
NoteQuestion
What will be the temperature in Berlin tomorrow? What information would you use to make a prediction?
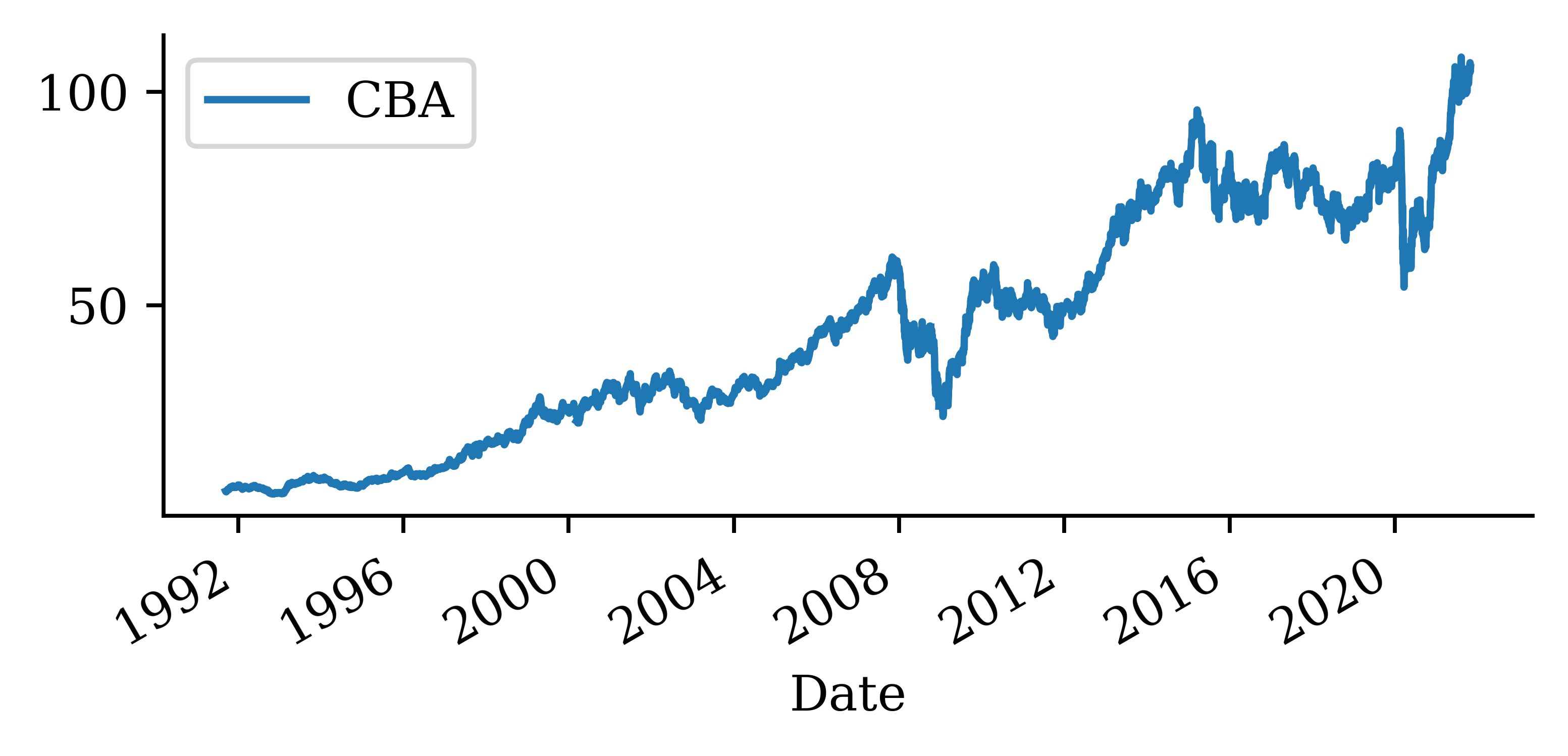
Australian financial stocks
# First, install yfinance if you haven't already:# pip install yfinanceimport yfinance as yfimport pandas as pdfrom datetime import date# 1. Define the ASX tickers (Yahoo uses “.AX” for Australian stocks# and “^AXJO” for the S&P/ASX 200 index)tickers = {"ANZ": "ANZ.AX","BOQ": "BOQ.AX","CBA": "CBA.AX","NAB": "NAB.AX","QBE": "QBE.AX","SUN": "SUN.AX","WBC": "WBC.AX","ASX200": "^AXJO"}# 2. Choose your date rangestart ="1999-01-01"end = date.today().isoformat() # e.g. "2025-06-29"# 3. Download the data# This returns a Panel-like DataFrame: columns are tickers, rows are trading dates.raw_data = yf.download( tickers=list(tickers.values()), start=start, end=end, progress=False)raw_data.to_csv("asx_raw_data.csv") # Optional: Save raw data for inspectiondata = raw_data["Close"]# 4. Rename columns to the simple namesdata.rename(columns={v: k for k, v in tickers.items()}, inplace=True)cols = ["ANZ", "ASX200", "BOQ", "CBA", "NAB", "QBE", "SUN", "WBC"]data = data[cols]# 5. (Optional) Inspect the first few rowsprint(data.head())# 6. Save to CSVoutput_path ="aus_fin_stocks.csv"data.to_csv(output_path)print(f"Saved daily close prices to {output_path}")
Australian financial stocks
stocks = pd.read_csv("aus_fin_stocks.csv")stocks
Date
ANZ
ASX200
BOQ
CBA
NAB
QBE
SUN
WBC
0
1999-01-01
8.413491
NaN
NaN
14.560169
NaN
NaN
7.965791
NaN
1
1999-01-04
8.476515
2732.199951
NaN
14.402927
12.995510
2.648447
7.965791
6.370629
2
1999-01-05
8.452881
2716.600098
NaN
14.409224
13.169948
2.564247
7.965791
6.485921
...
...
...
...
...
...
...
...
...
...
6742
2025-06-25
29.100000
8559.200195
7.86
191.399994
40.049999
23.480000
21.750000
34.540001
6743
2025-06-26
29.740000
8550.799805
7.86
190.710007
39.889999
23.330000
21.459999
34.570000
6744
2025-06-27
29.200001
8514.200195
7.77
185.360001
39.259998
23.219999
21.330000
33.900002
6745 rows × 9 columns
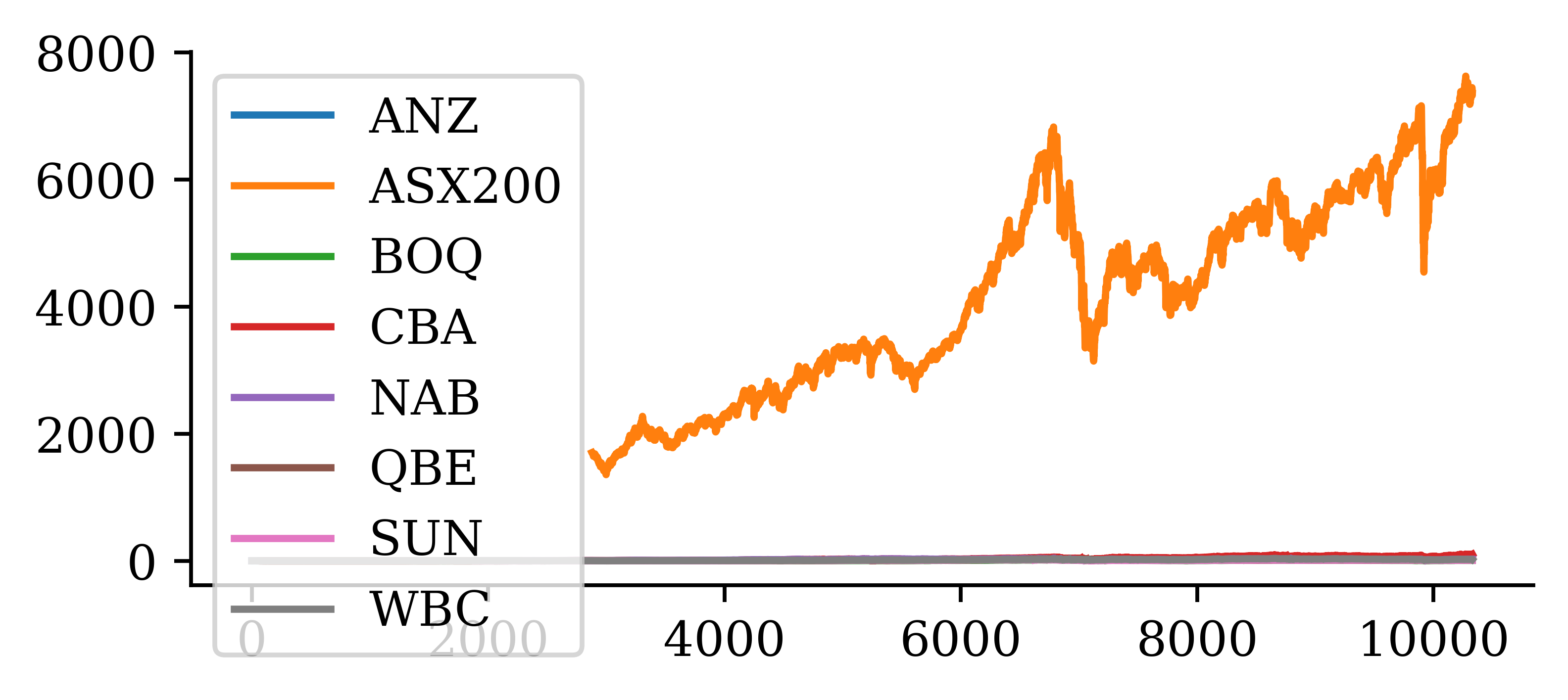
Plot
stocks.plot()
NoteQuestion
What is wrong with this plot?
Answer: The main issues are * x-axis is unclear: should show the date, not the observation number * The ASX200 has much larger value than the individual stocks; it should be plotted separately. * The legend shouldn’t be overlapping and hiding half of the plot.
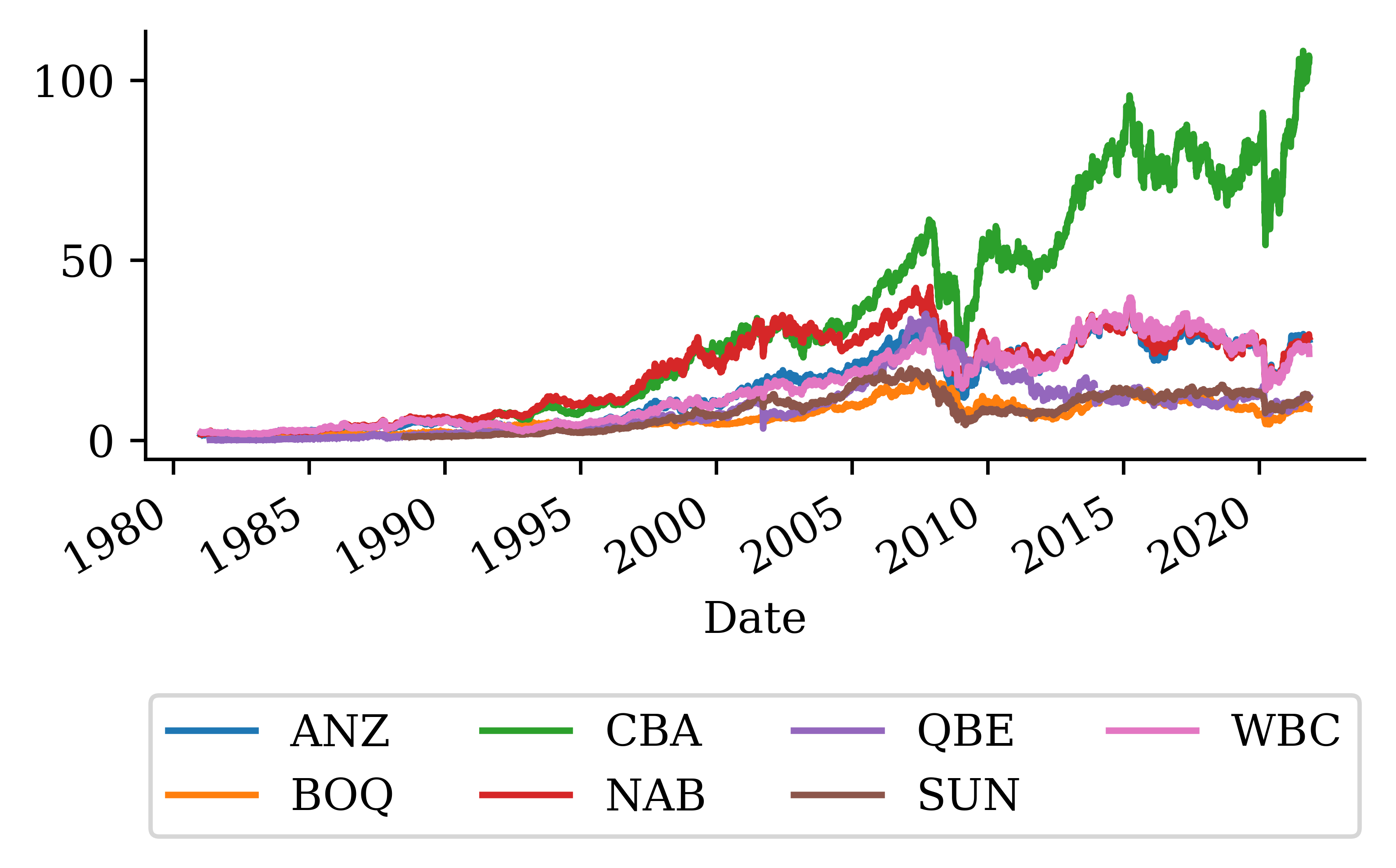
stocks["Date"] = pd.to_datetime(stocks["Date"])stocks = stocks.set_index("Date") # or `stocks.set_index("Date", inplace=True)`stocks
ANZ
BOQ
CBA
NAB
QBE
SUN
WBC
Date
1999-01-01
8.413491
NaN
14.560169
NaN
NaN
7.965791
NaN
1999-01-04
8.476515
NaN
14.402927
12.995510
2.648447
7.965791
6.370629
1999-01-05
8.452881
NaN
14.409224
13.169948
2.564247
7.965791
6.485921
...
...
...
...
...
...
...
...
2025-06-25
29.100000
7.86
191.399994
40.049999
23.480000
21.750000
34.540001
2025-06-26
29.740000
7.86
190.710007
39.889999
23.330000
21.459999
34.570000
2025-06-27
29.200001
7.77
185.360001
39.259998
23.219999
21.330000
33.900002
6745 rows × 7 columns
By setting the index to the date (and converting the date to a proper date format rather than a string), the plot of the stocks can be updated accordingly very easily.
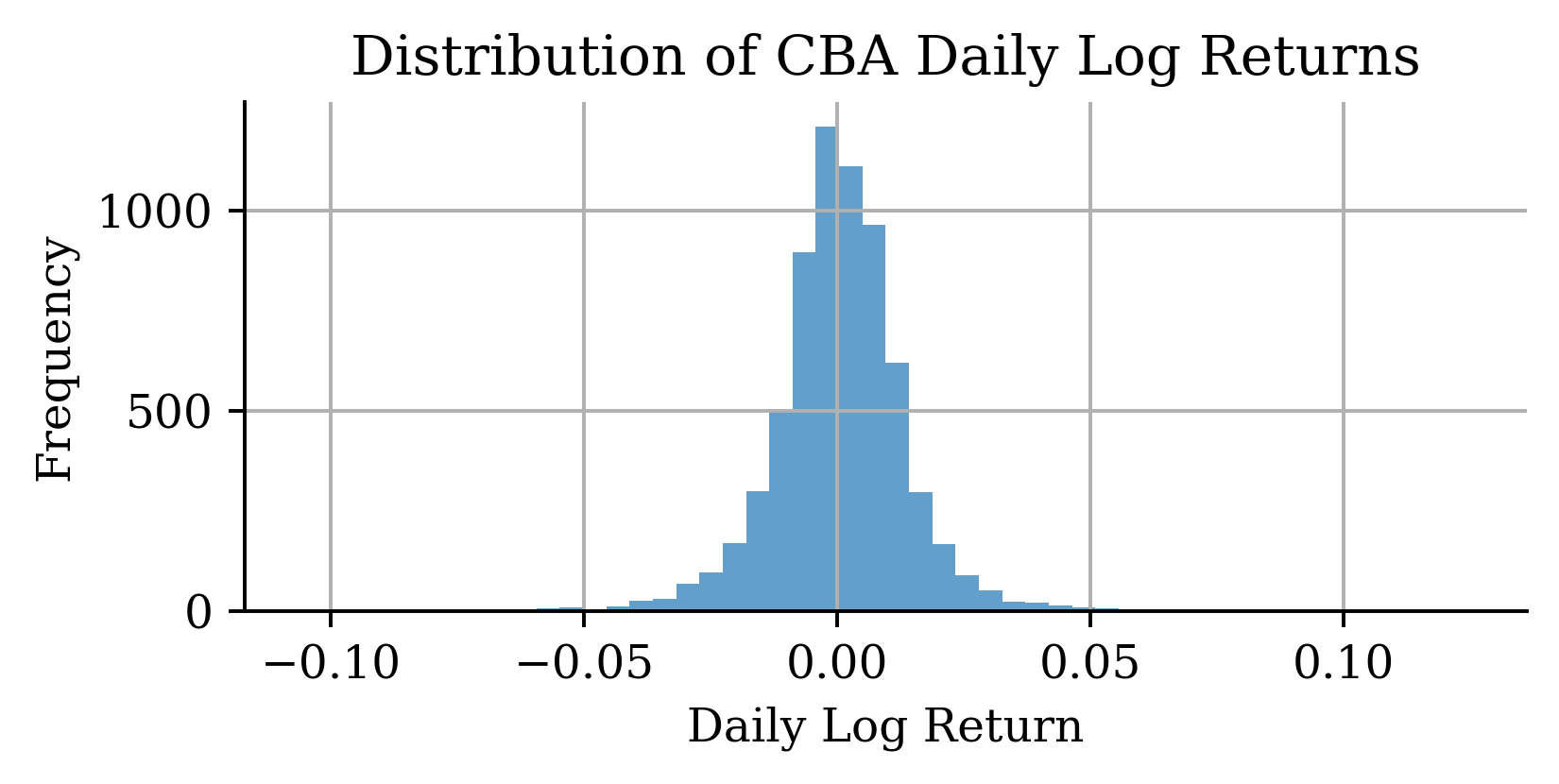
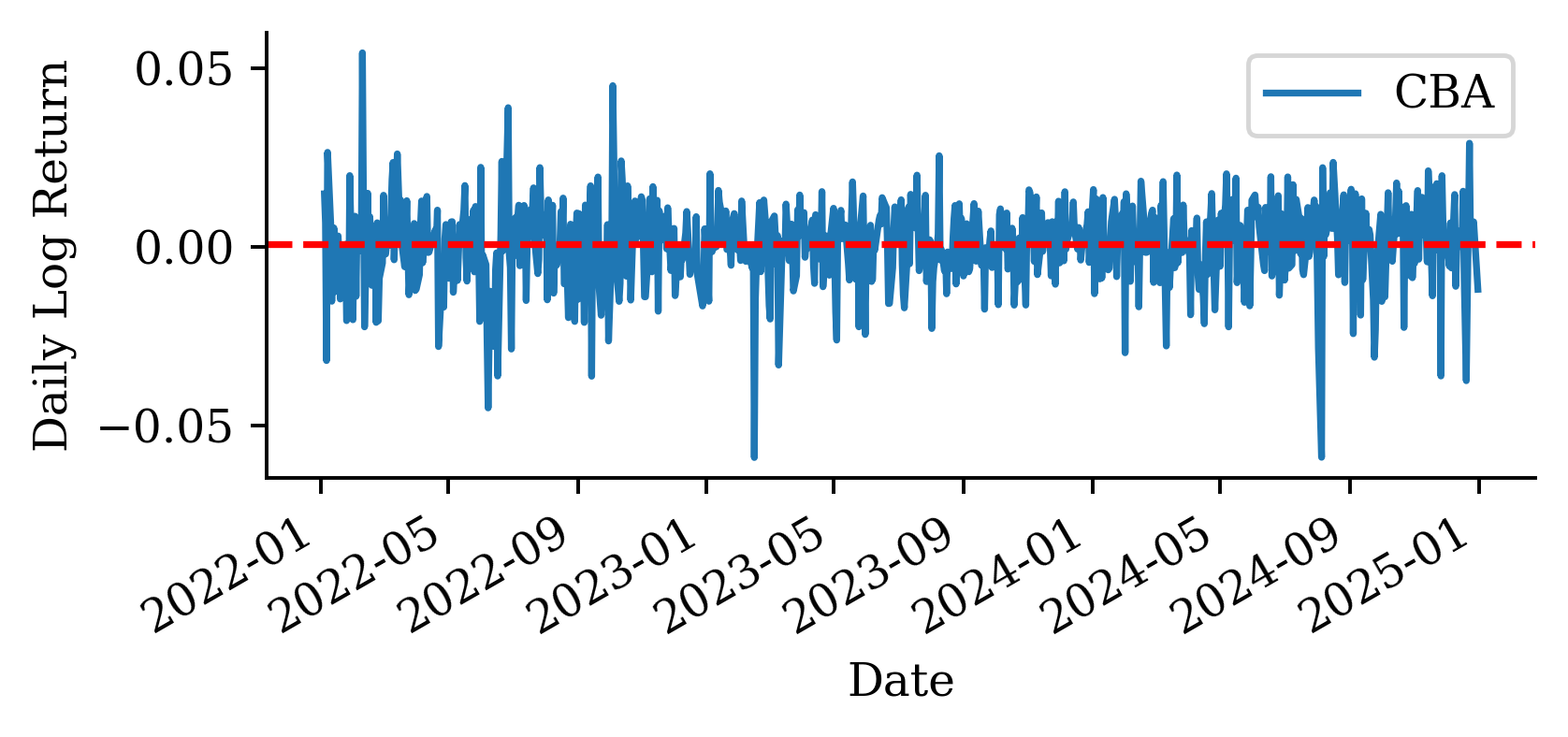
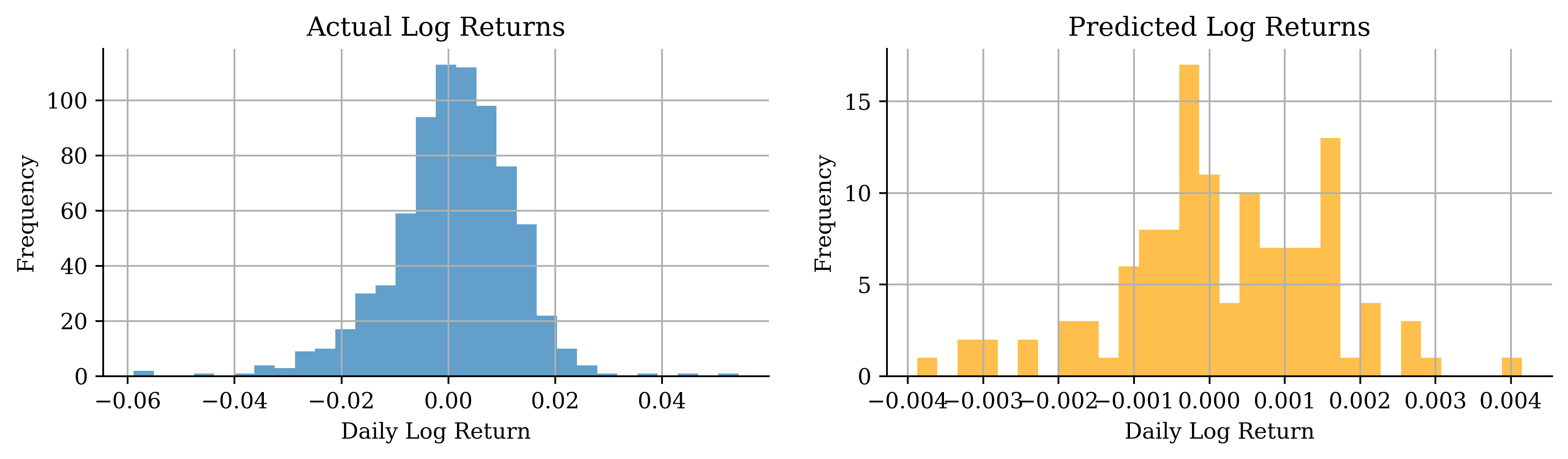
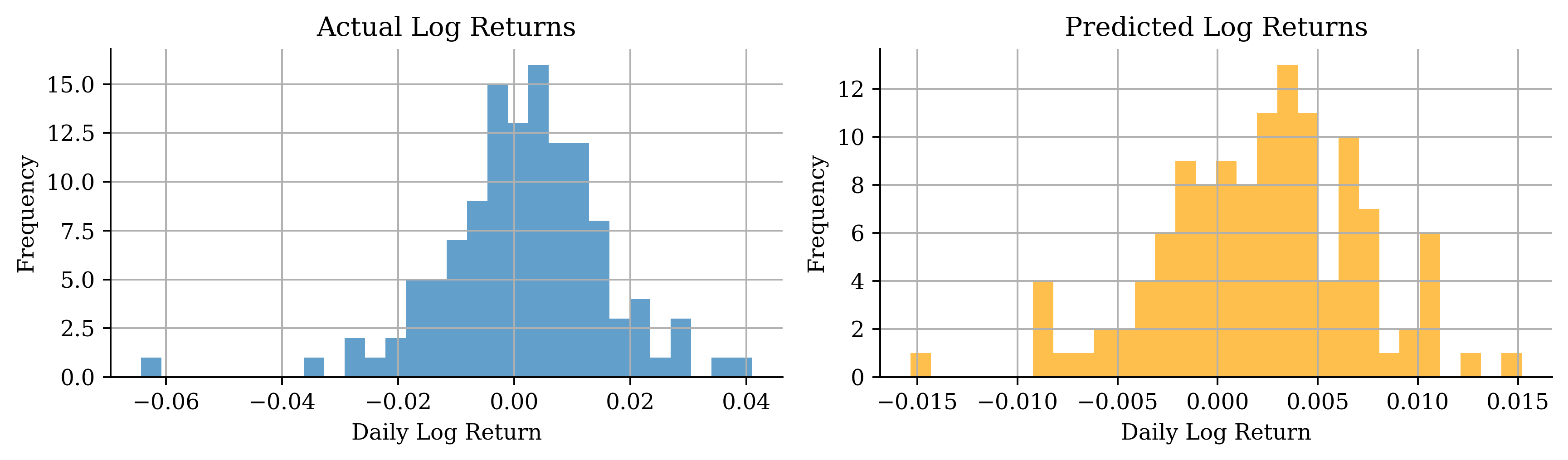
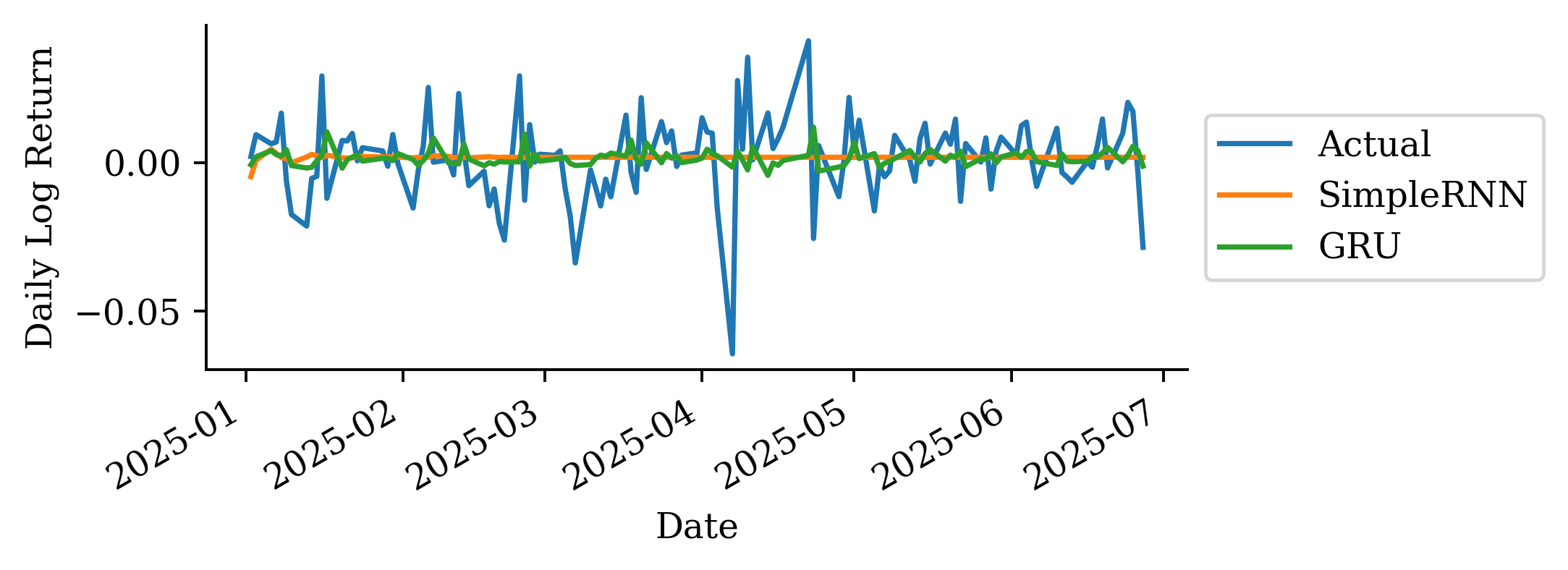
# Distribution of log returnsstock_log.hist(bins=50, alpha=0.7)plt.xlabel("Daily Log Return")plt.ylabel("Frequency")plt.title("Distribution of CBA Daily Log Returns");
Fill in the missing values
Some of the data has missing values. Here, we fill in the missing values by taking the value from the previous day. If the previous day also has missing value, then you do the same thing until all values are filled. This is called foward-filling.
def log_to_price(log_returns, initial_price):"""Convert log returns to raw prices given an initial price."""# Use cumulative sum of log returns for numerical stability# P_t = P_0 * exp(sum of log returns from 1 to t) cumulative_log_returns = log_returns.cumsum() prices = initial_price * np.exp(cumulative_log_returns)return pricesdef get_last_price(stock_df, cutoff_date):"""Get the last known price before the forecast period starts.""" last_known_date = stock_df.loc[:cutoff_date].index[-1]return stock_df.loc[last_known_date, "CBA"]
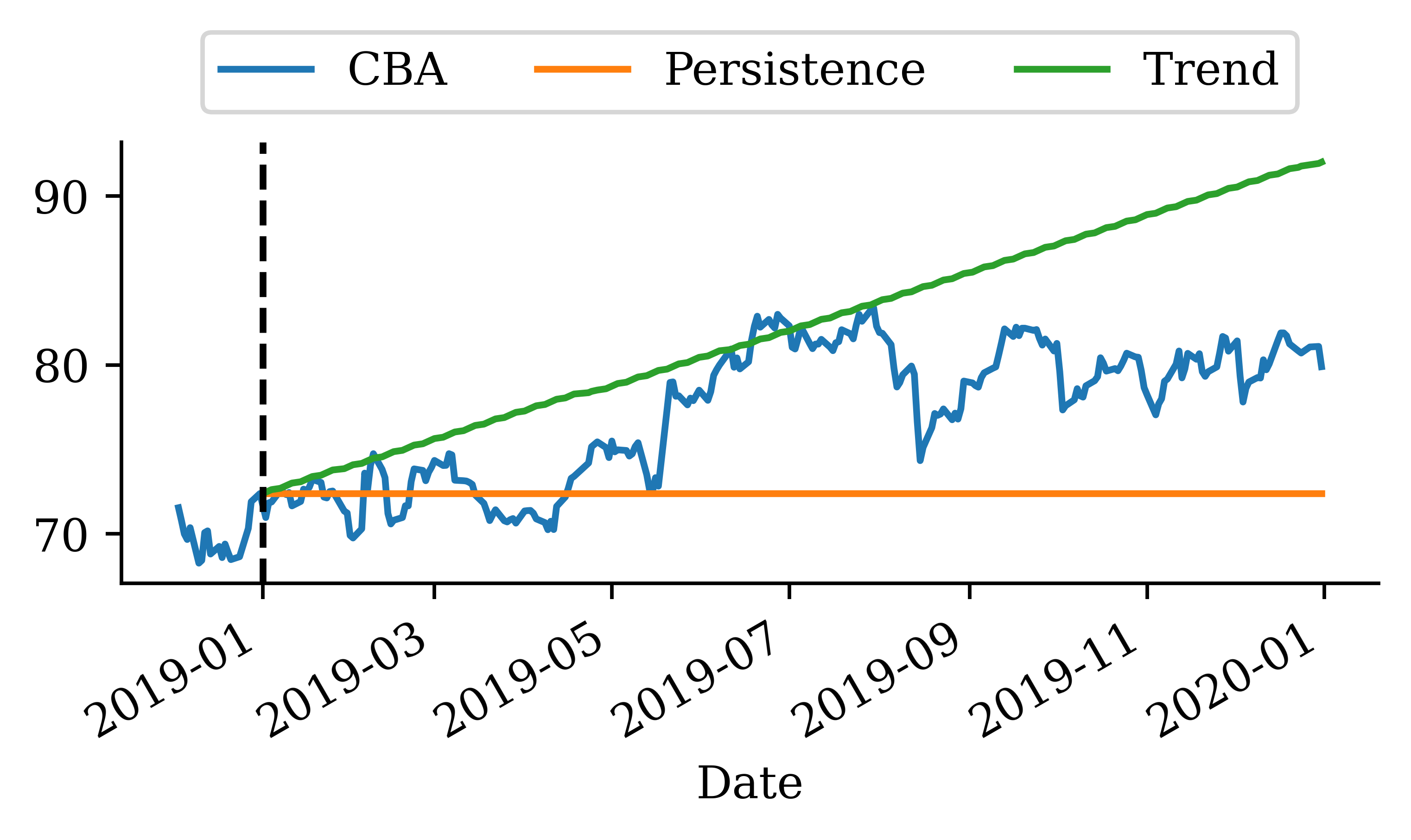
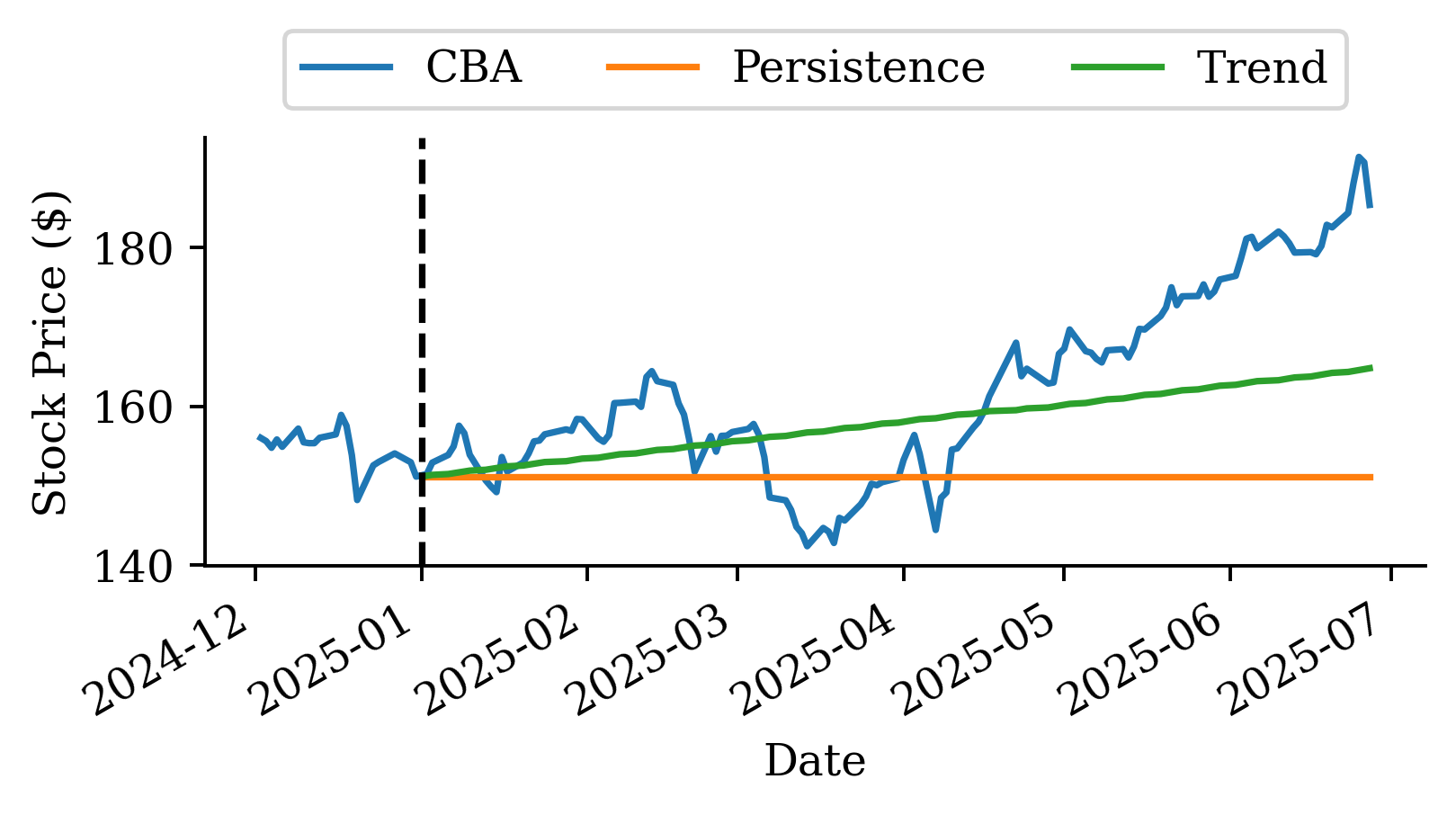
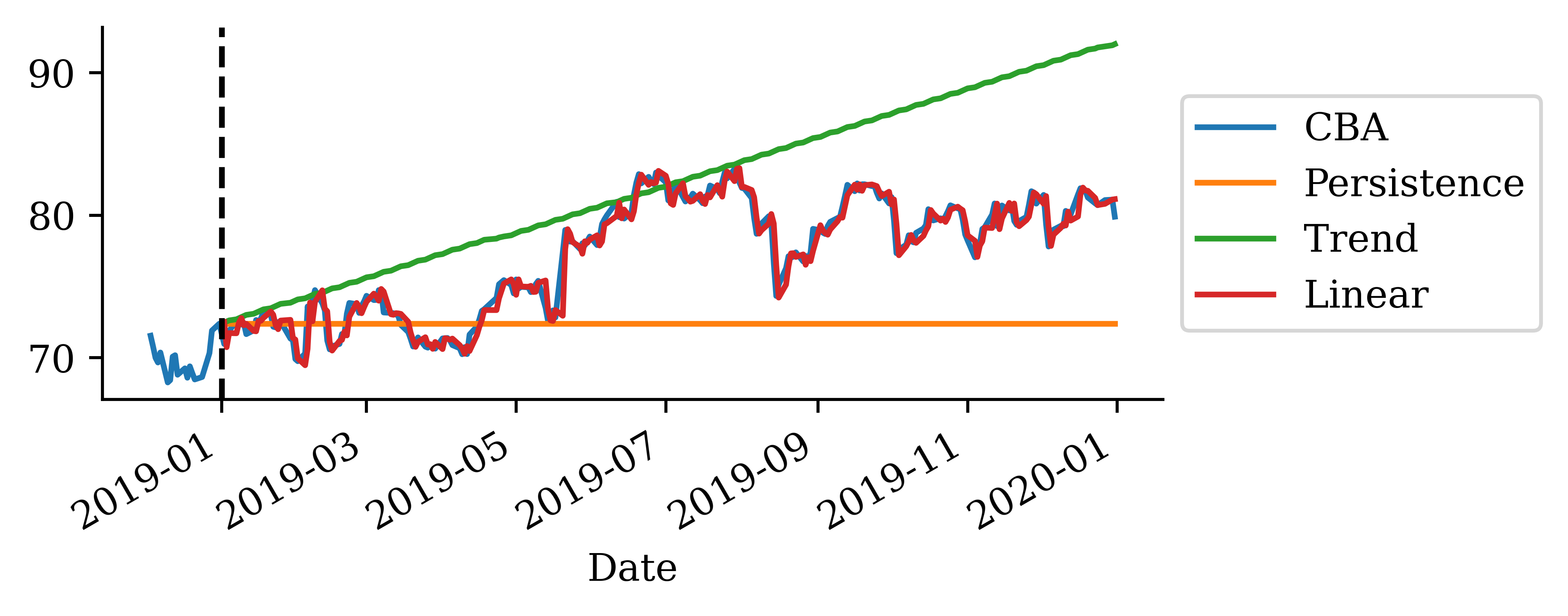
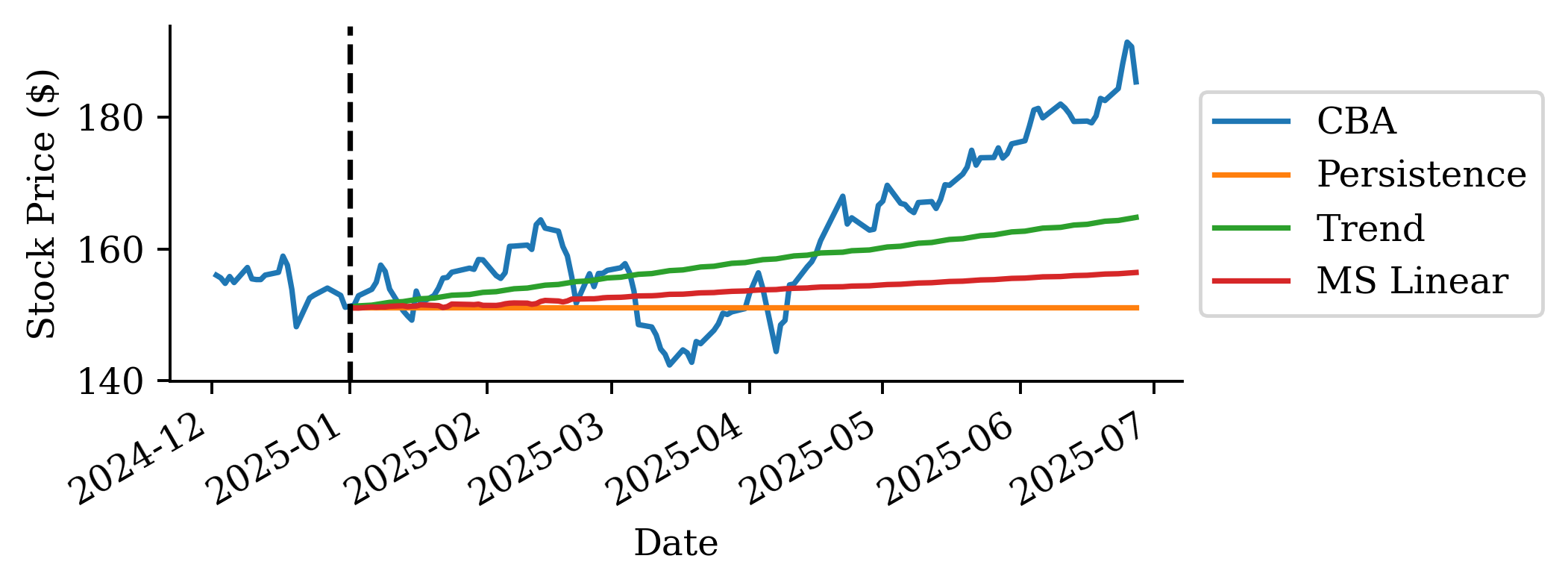
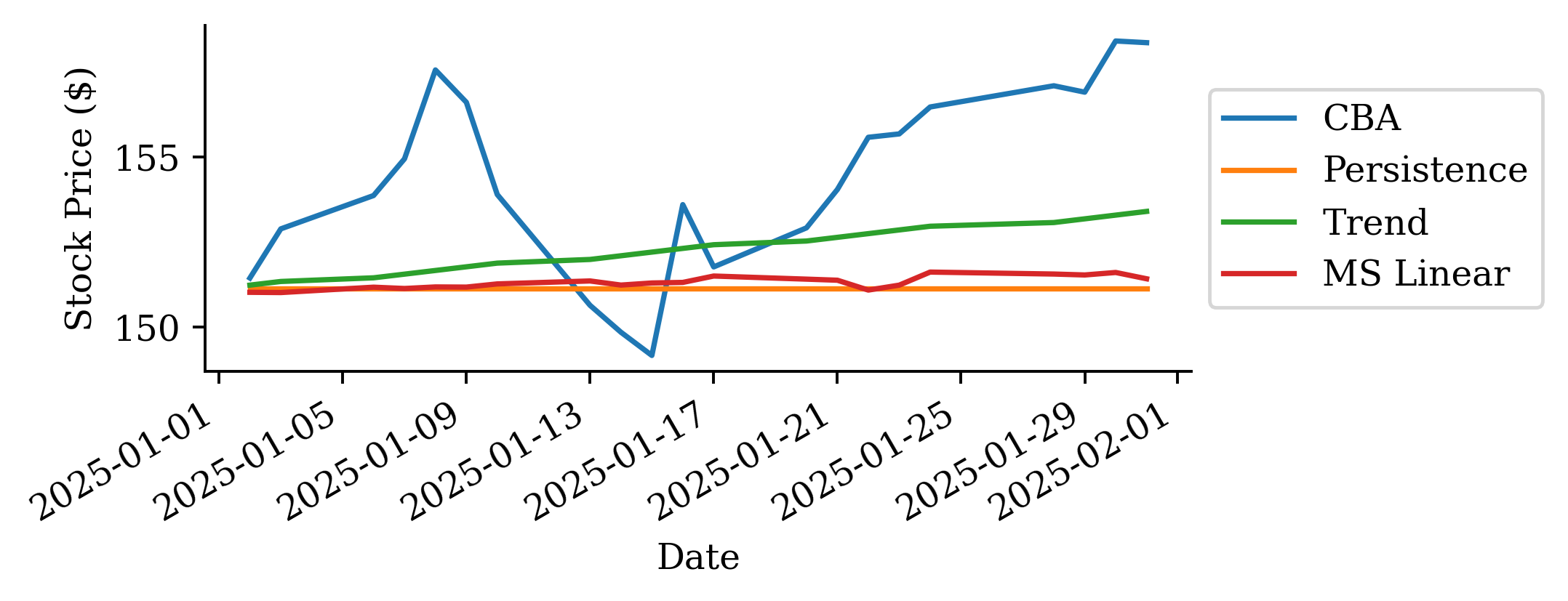
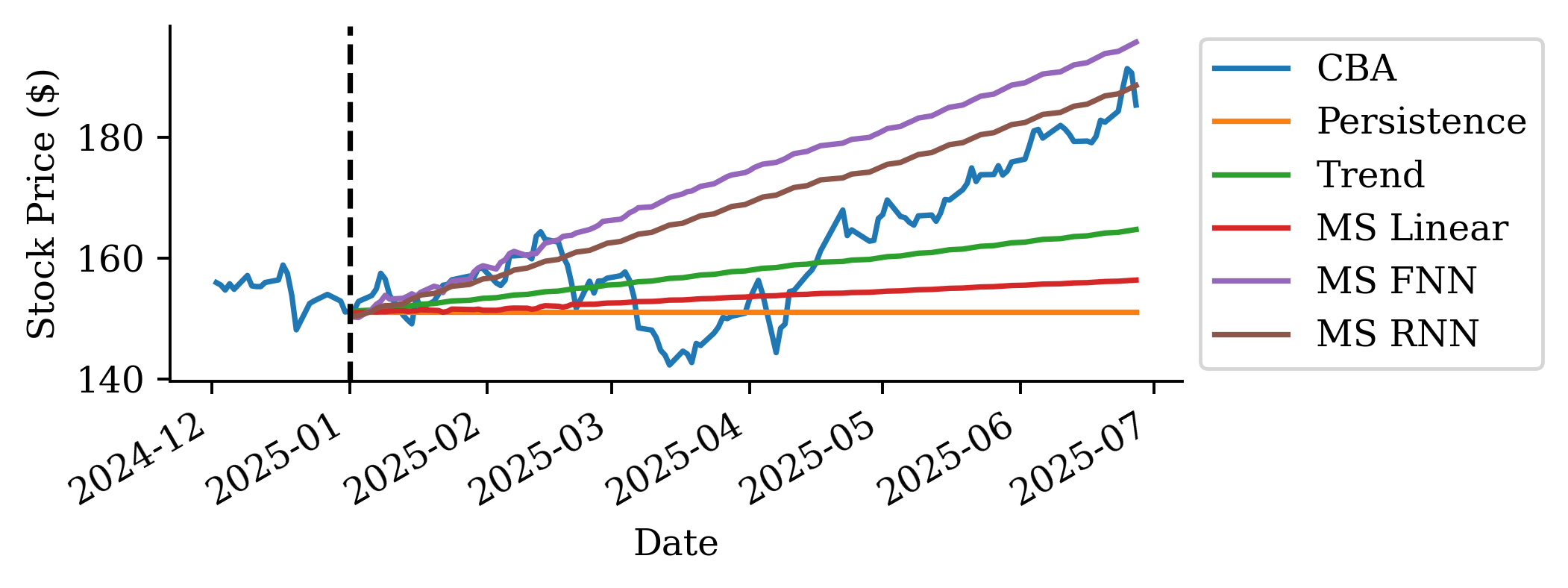
Persistence forecast
Predict the next value to be the same as the current value.
# Plot the trend line over the top of the 'recent_log_returns' datarecent_log_returns.plot()plt.axhline(trend_log, color="red", linestyle="--", label="Trend (mean log return)")plt.ylabel("Daily Log Return");
Trend fitted
# Create trend forecast for the recent period to show fitted trendrecent_trend_log = pd.Series(trend_log, index=recent_log_returns.index)trend_start_price = get_last_price(stock, cutoff_date=recent_log_returns.index[0].strftime('%Y-%m-%d'))recent_trend_prices = log_to_price(recent_trend_log, trend_start_price)
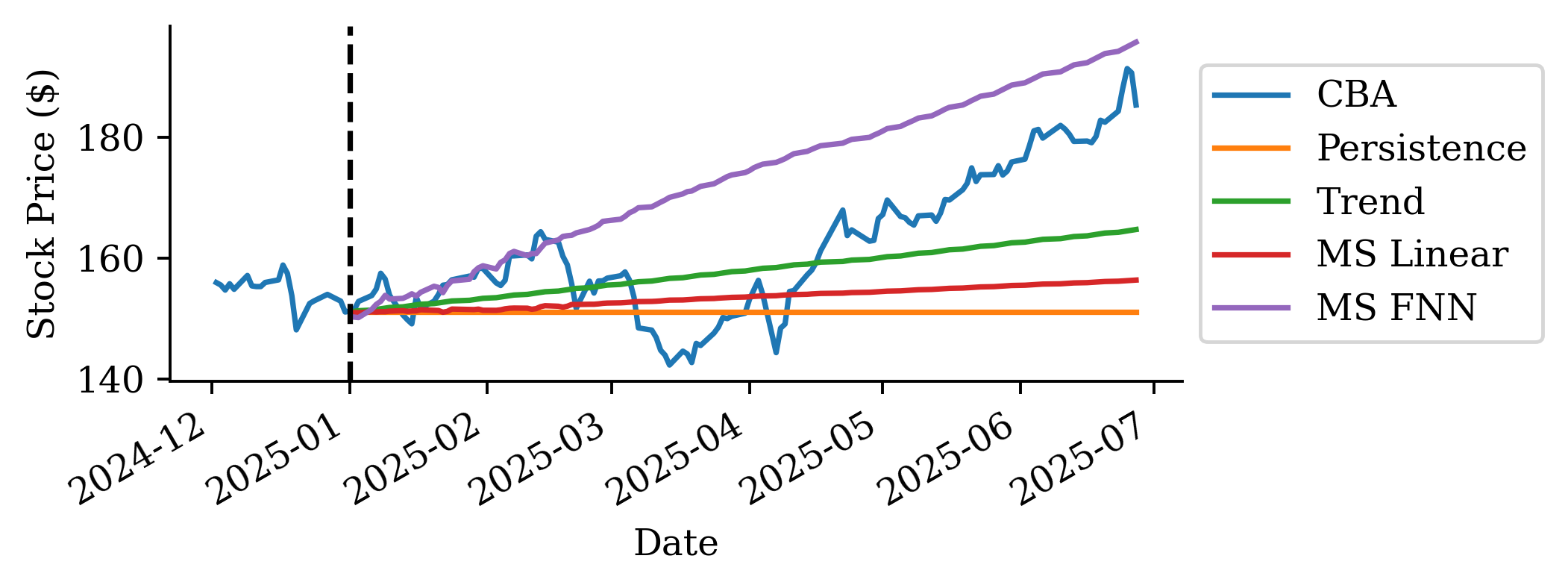
If we look at the mean squared error (MSE) of the two models:
# Calculate MSE using the actual forecasts we computedactual_prices = stock.loc["2025":, "CBA"]persistence_mse = mean_squared_error(actual_prices, persistence_prices)trend_mse = mean_squared_error(actual_prices, trend_prices)persistence_mse, trend_mse
(254.04075100411256, 99.28717915684173)
TipQuestion
What are the units of the calculated MSE?
Answer: Since the forecasts are in $, and we square the differences, the units are in squared $.
By taking the root MSE (RMSE), the unit is back in $ which is more interpretable.
Use the history
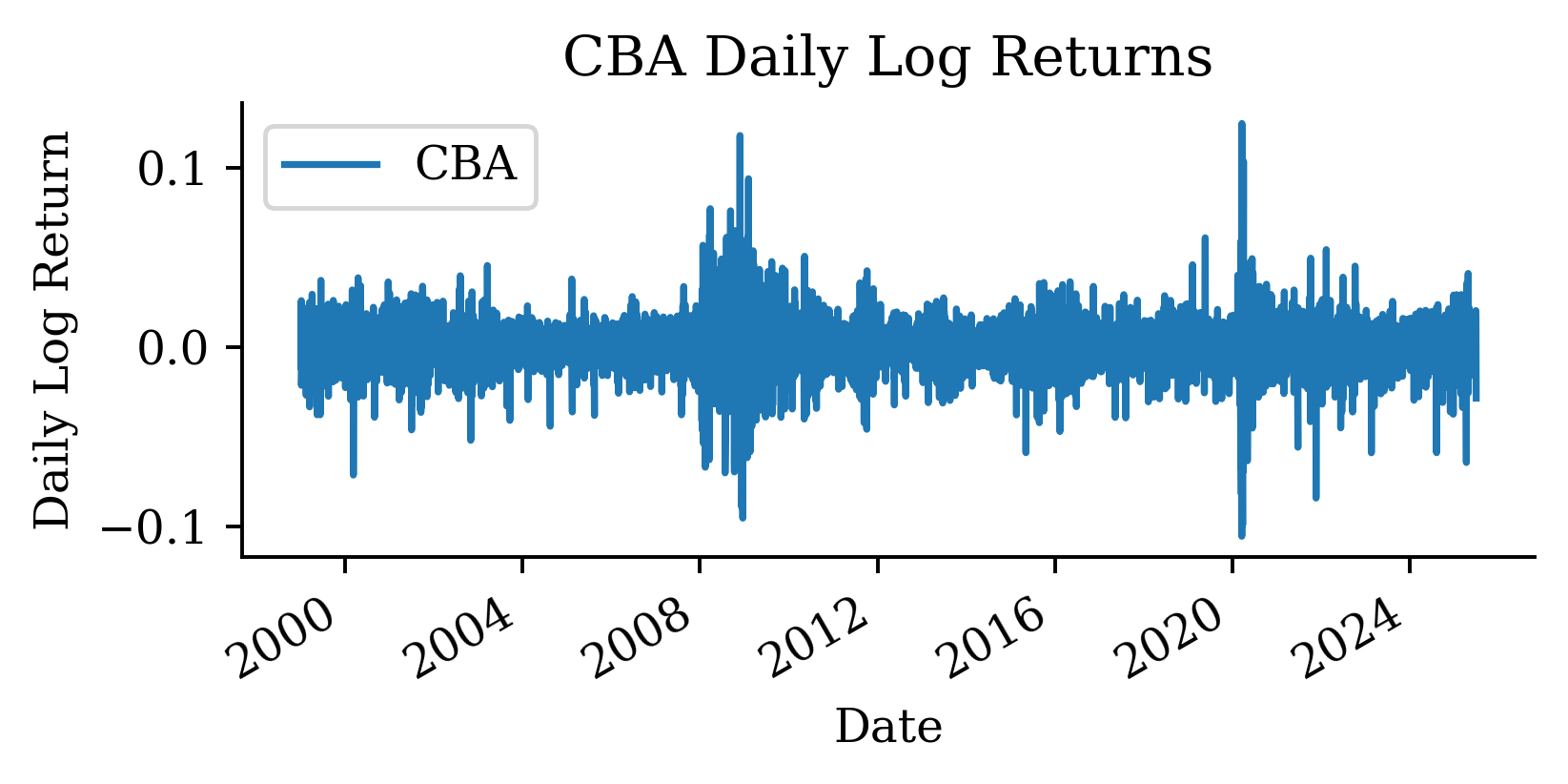
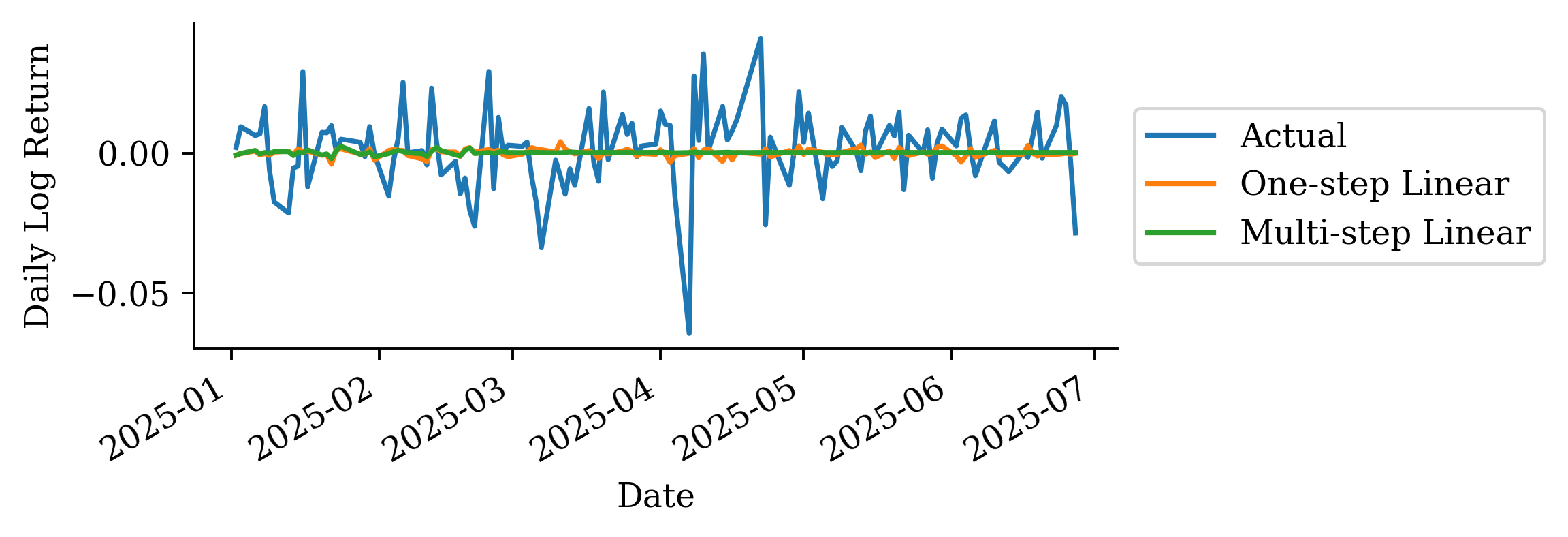
Now let’s work with log returns instead of raw prices to create lagged features:
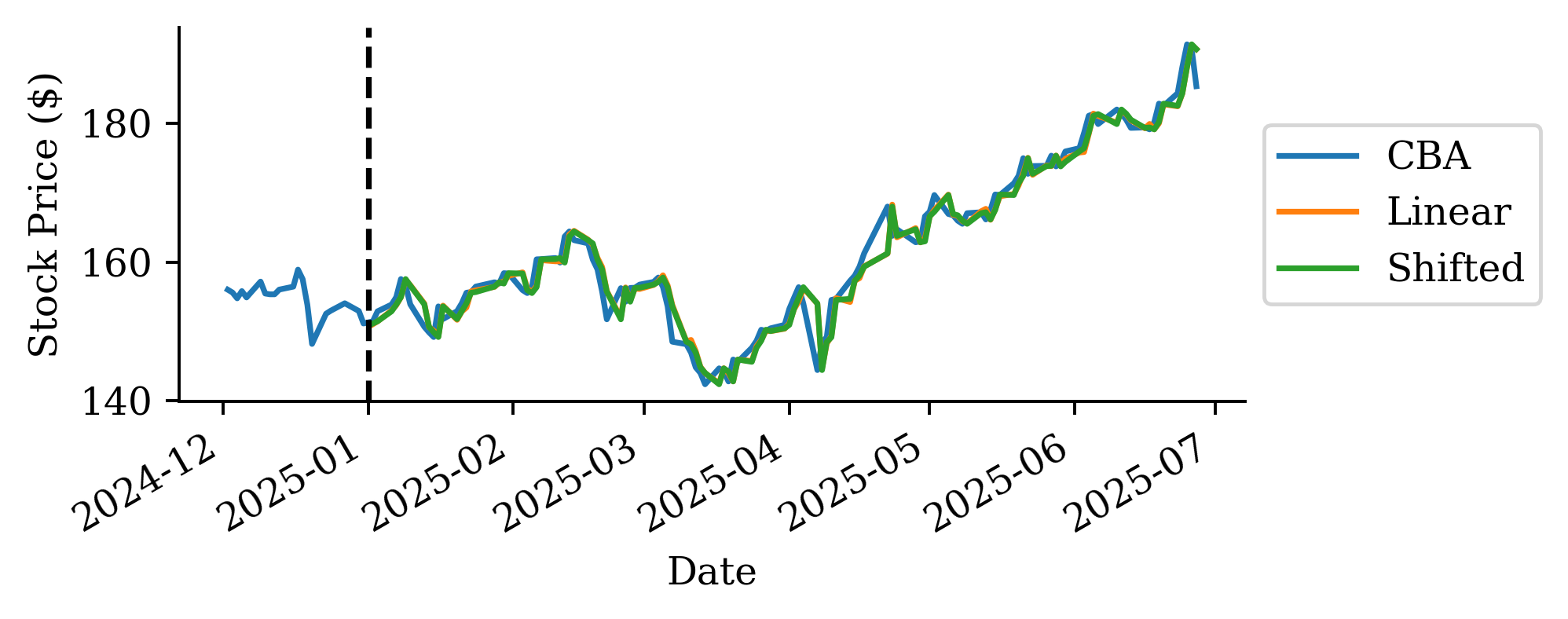
cba_log_shifted = stock_log["CBA"].head().shift(1) both = pd.concat([stock_log["CBA"].head(), cba_log_shifted], axis=1, keys=["Today", "Yesterday"]) both
Today
Yesterday
Date
1999-01-04
-0.010858
NaN
1999-01-05
0.000437
-0.010858
1999-01-06
0.008042
0.000437
1999-01-07
0.025859
0.008042
1999-01-08
-0.021323
0.025859
This code creates a new variable that is the log return from the previous day.
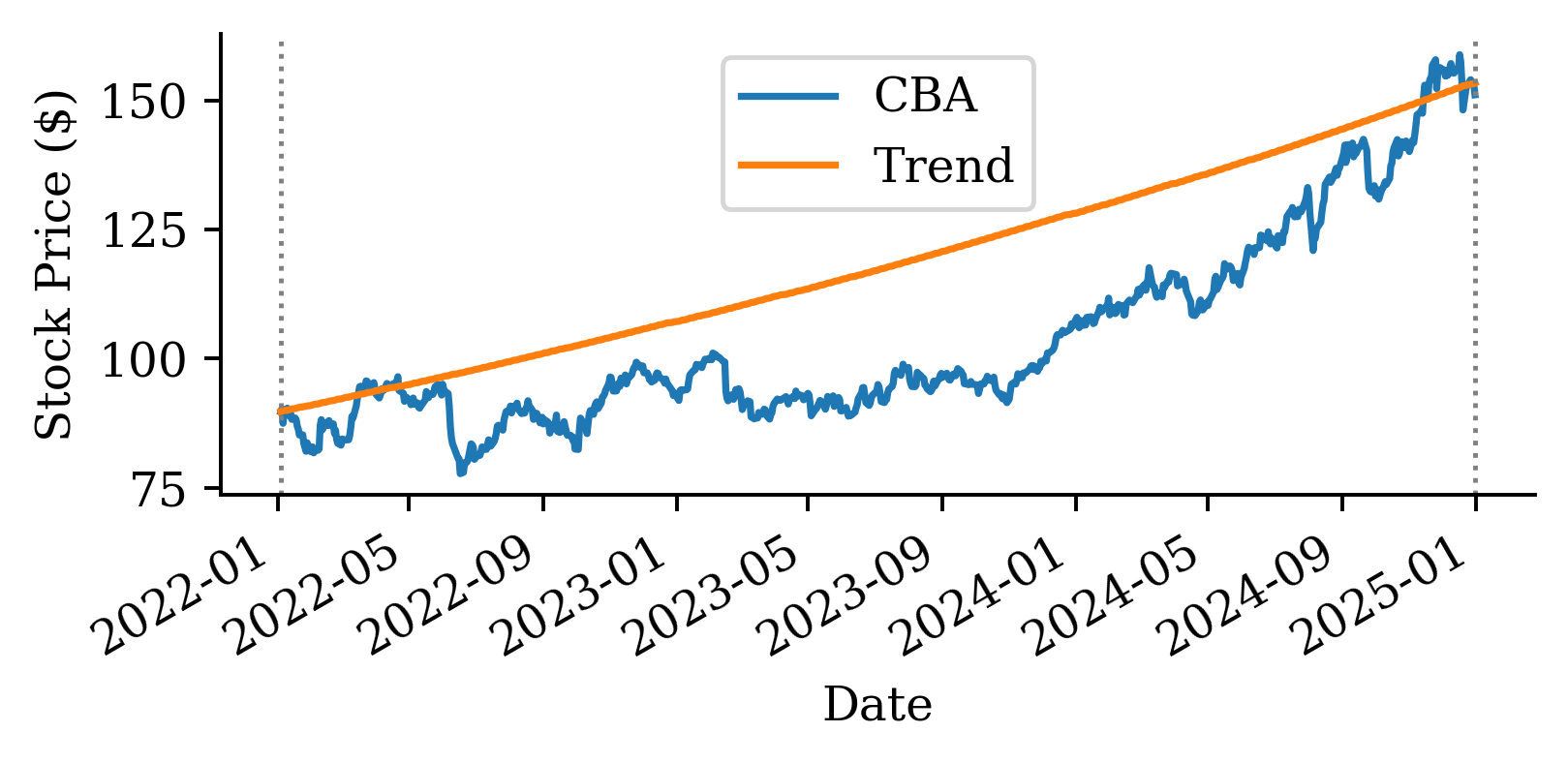
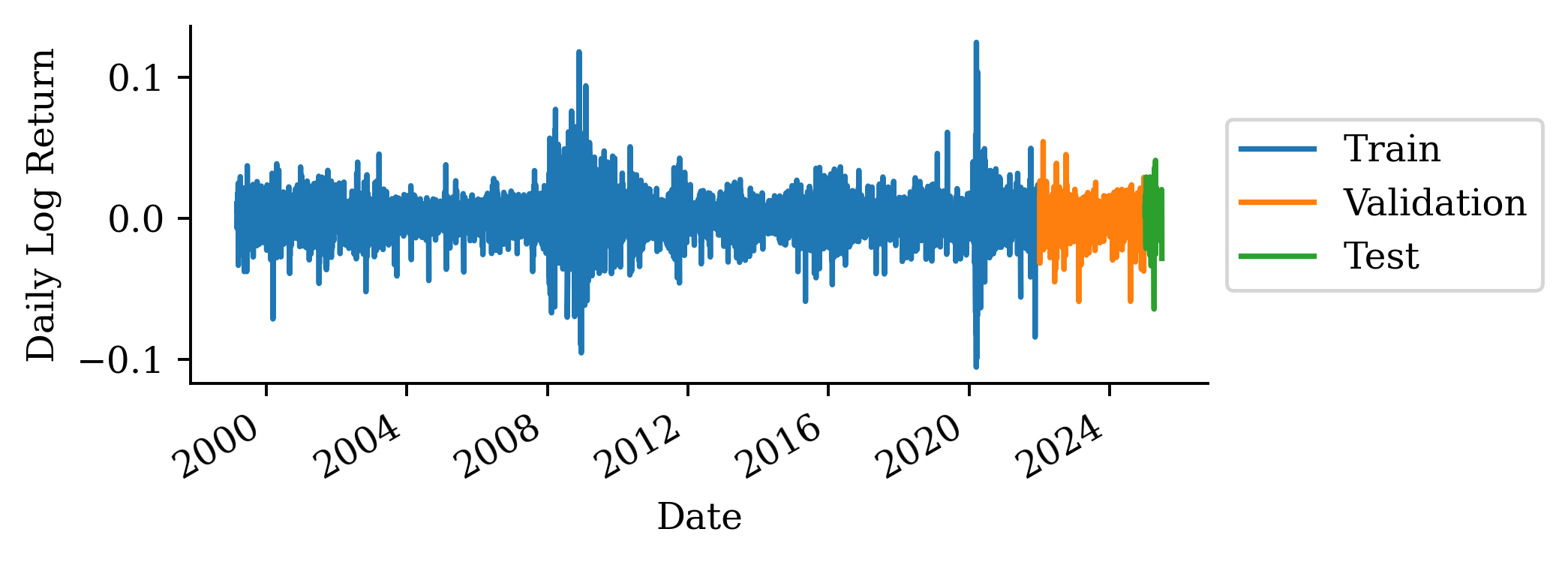
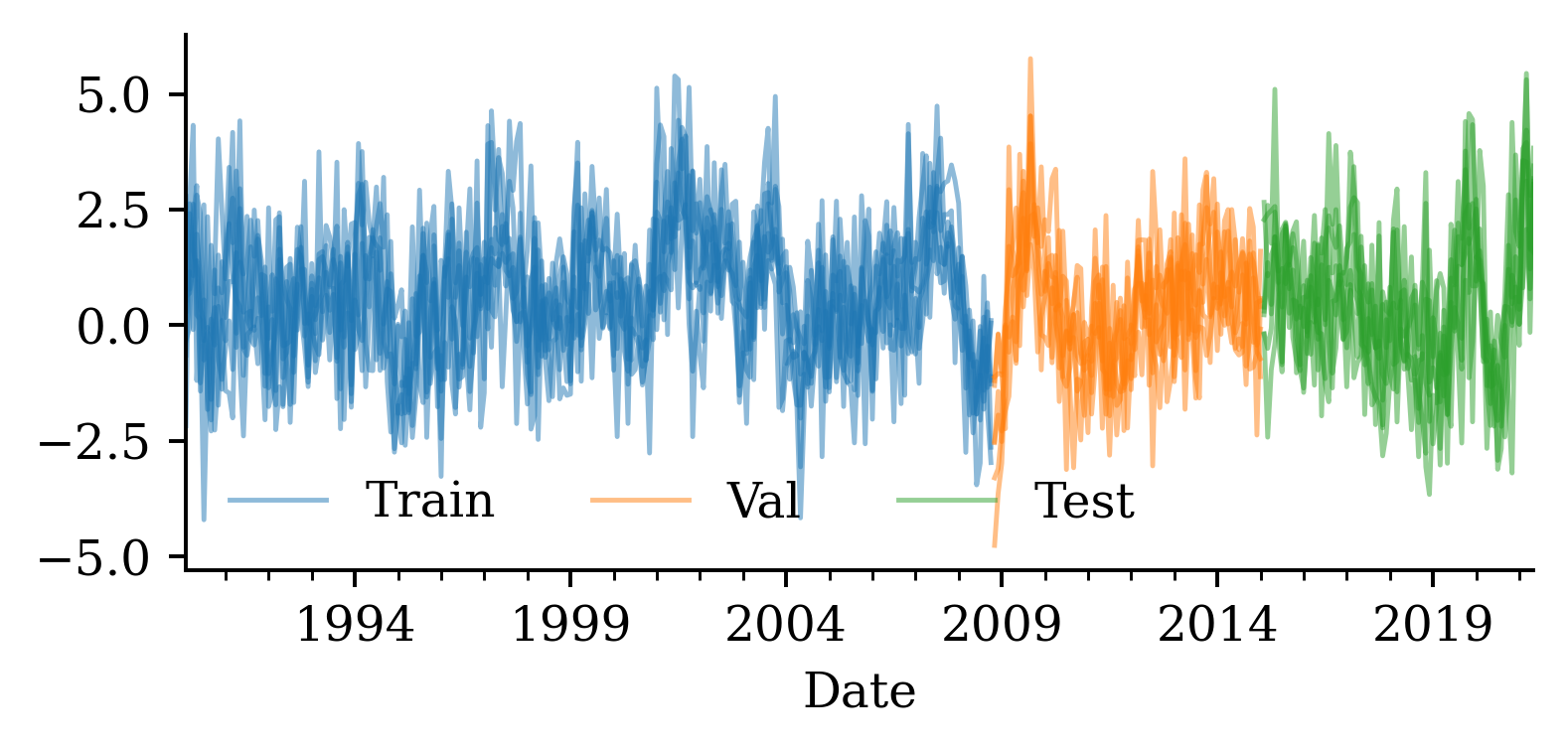
We can’t split the data randomly, as the timing of the data matters. We need to fit on older data and try to predict forward in time. Here we define:
Training data: up to 2021
Validation data: 2022-2024
Test data: 2025
# Split the data in timeX_train = df_lags.loc[:"2021"]X_val = df_lags.loc["2022-01":"2024-12"] # 2022-2024X_test = df_lags.loc["2025":] # 2025# Remove any with NAs and split into X and yX_train = X_train.dropna()X_val = X_val.dropna()X_test = X_test.dropna()y_train = X_train.pop("T")y_val = X_val.pop("T")y_test = X_test.pop("T")
We want to predict today’s stock price. We need to remove today’s stock price ("T") from the features and define it as the target.
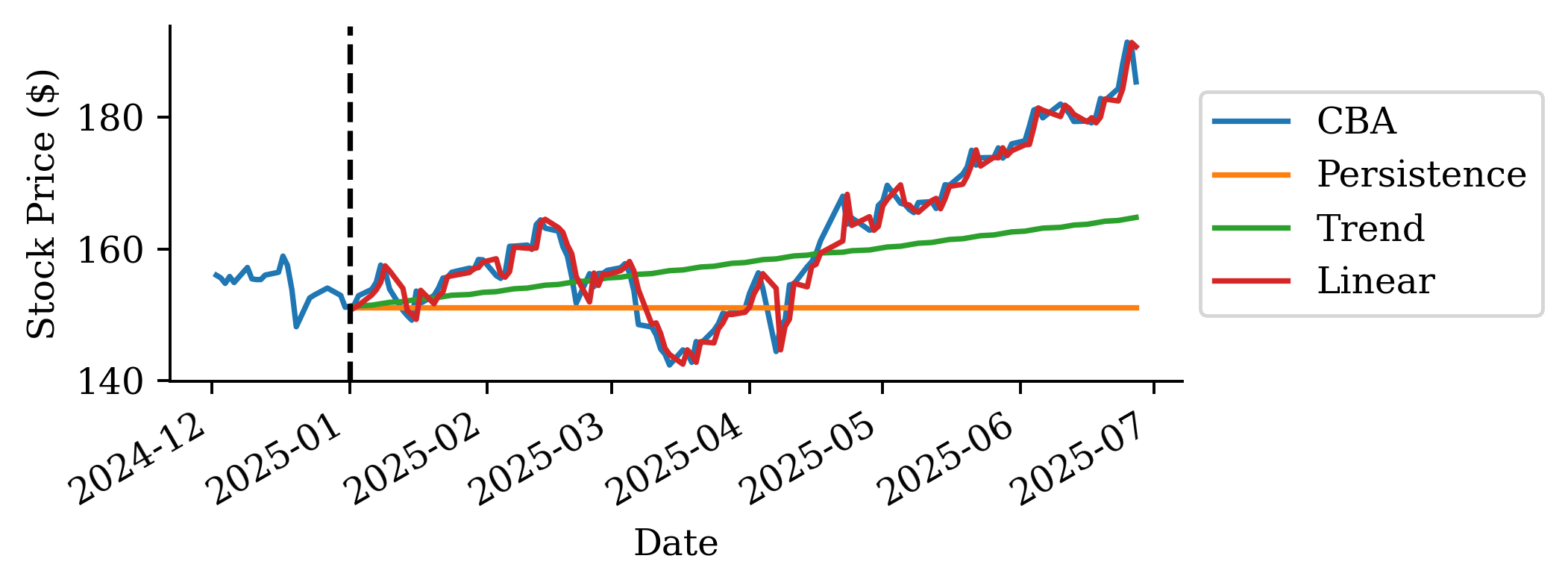
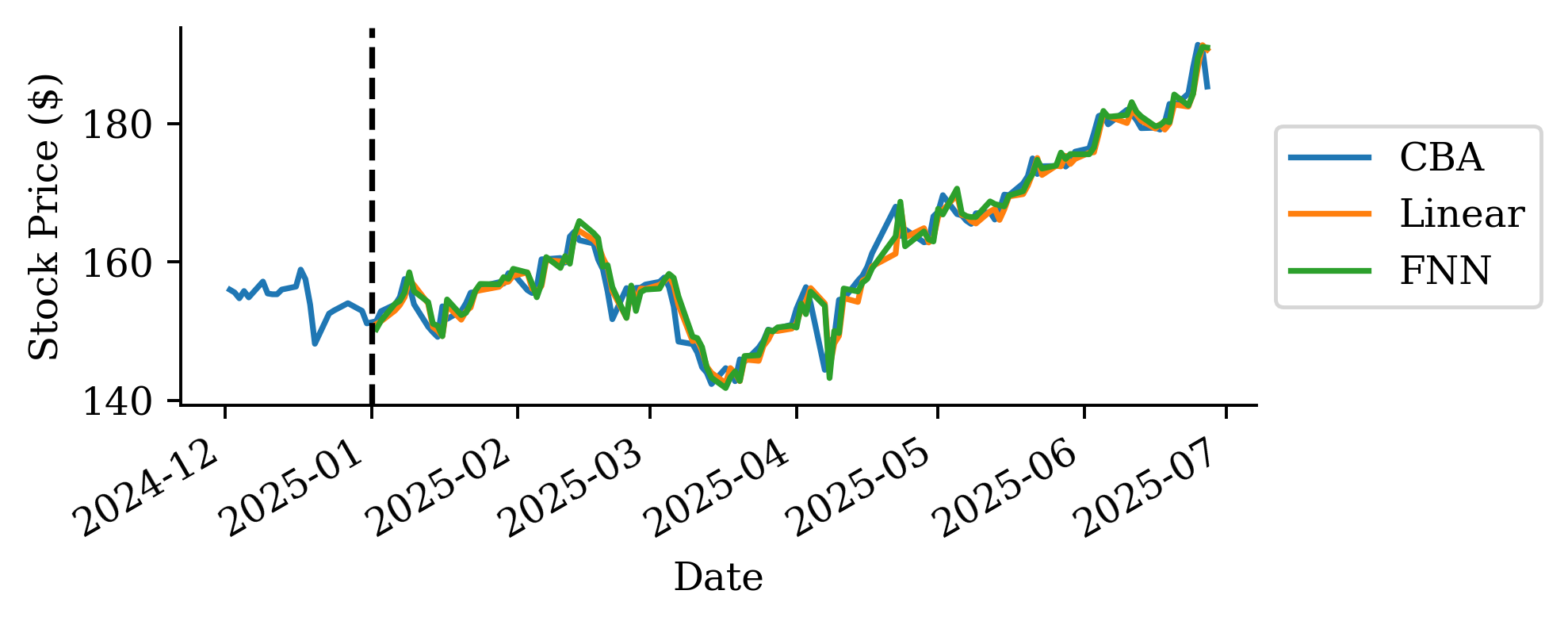
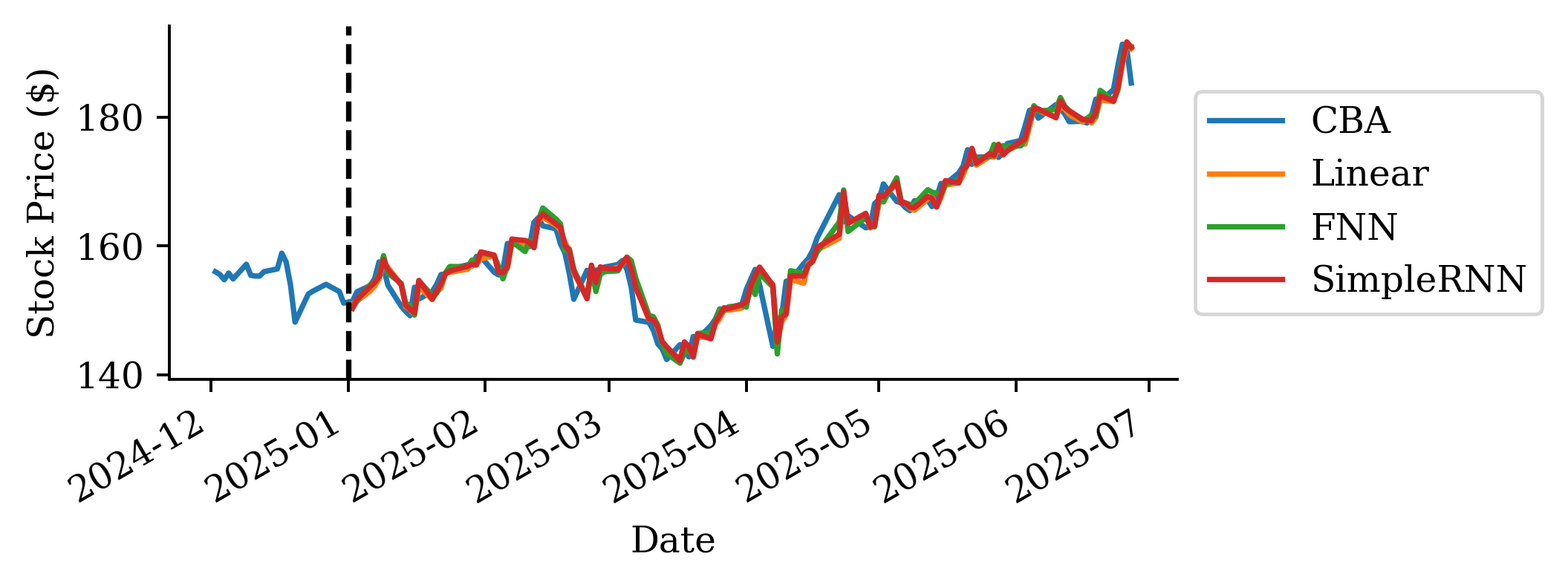
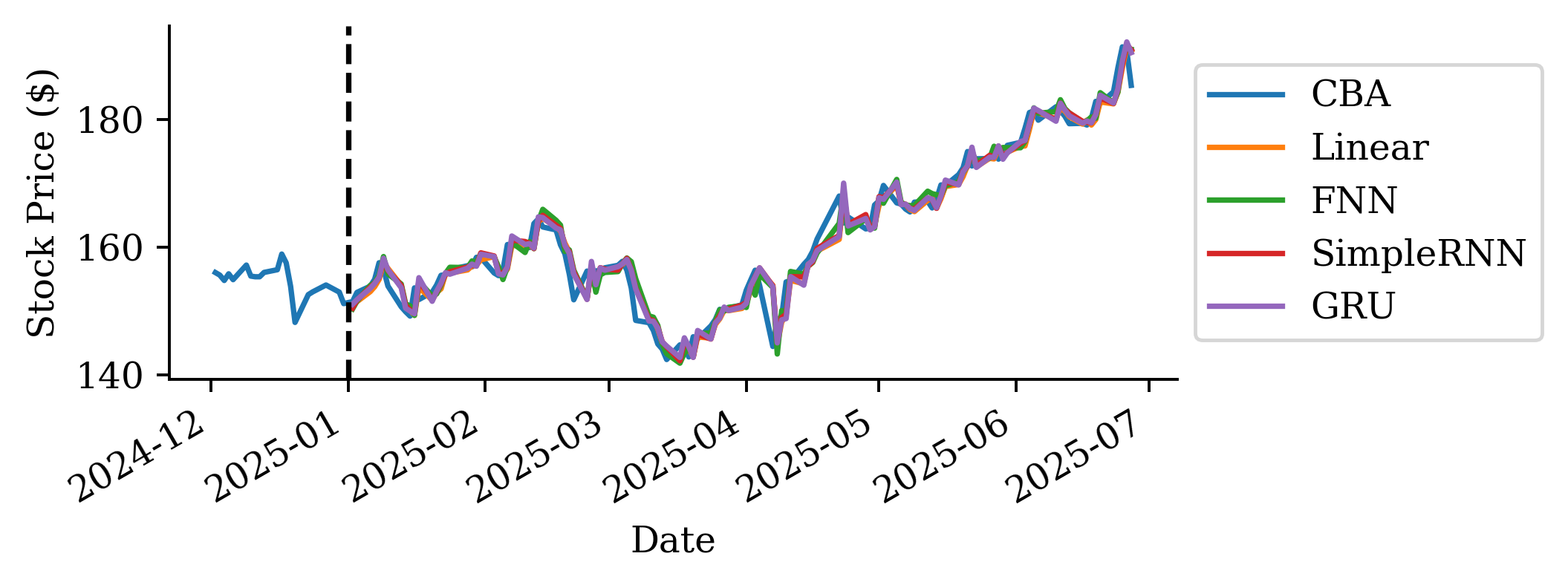
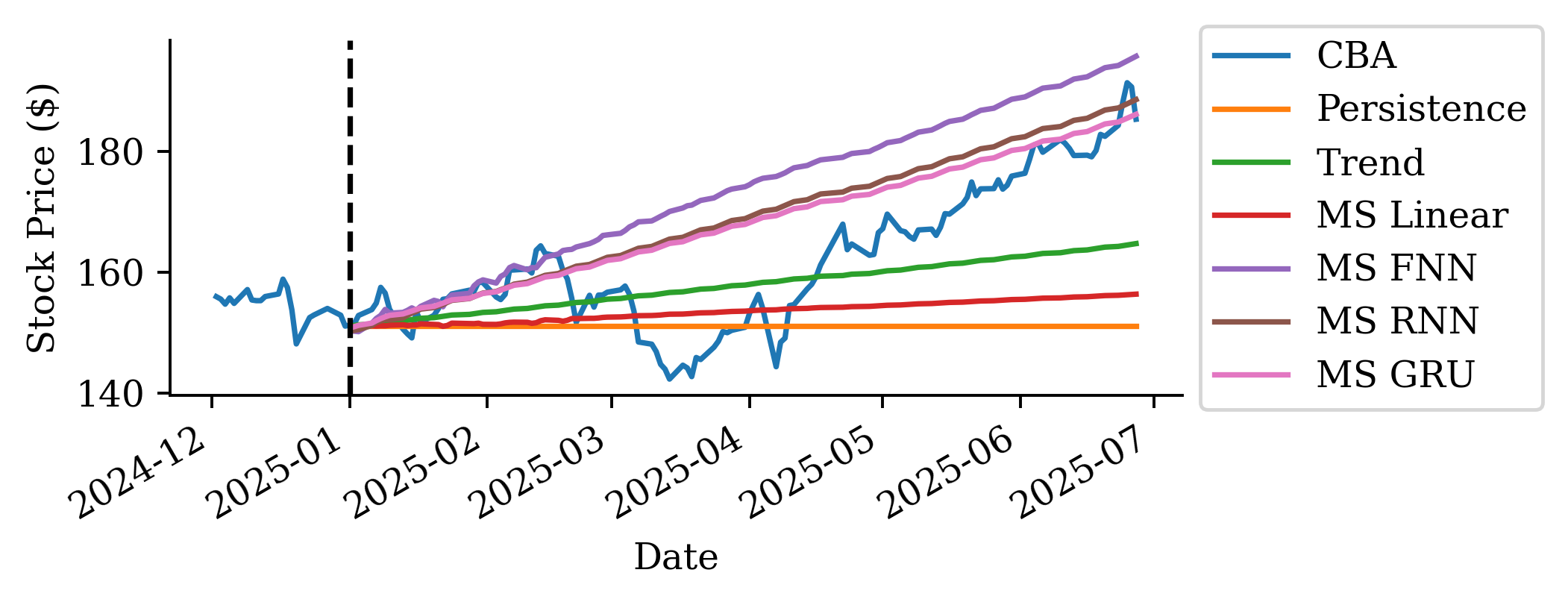
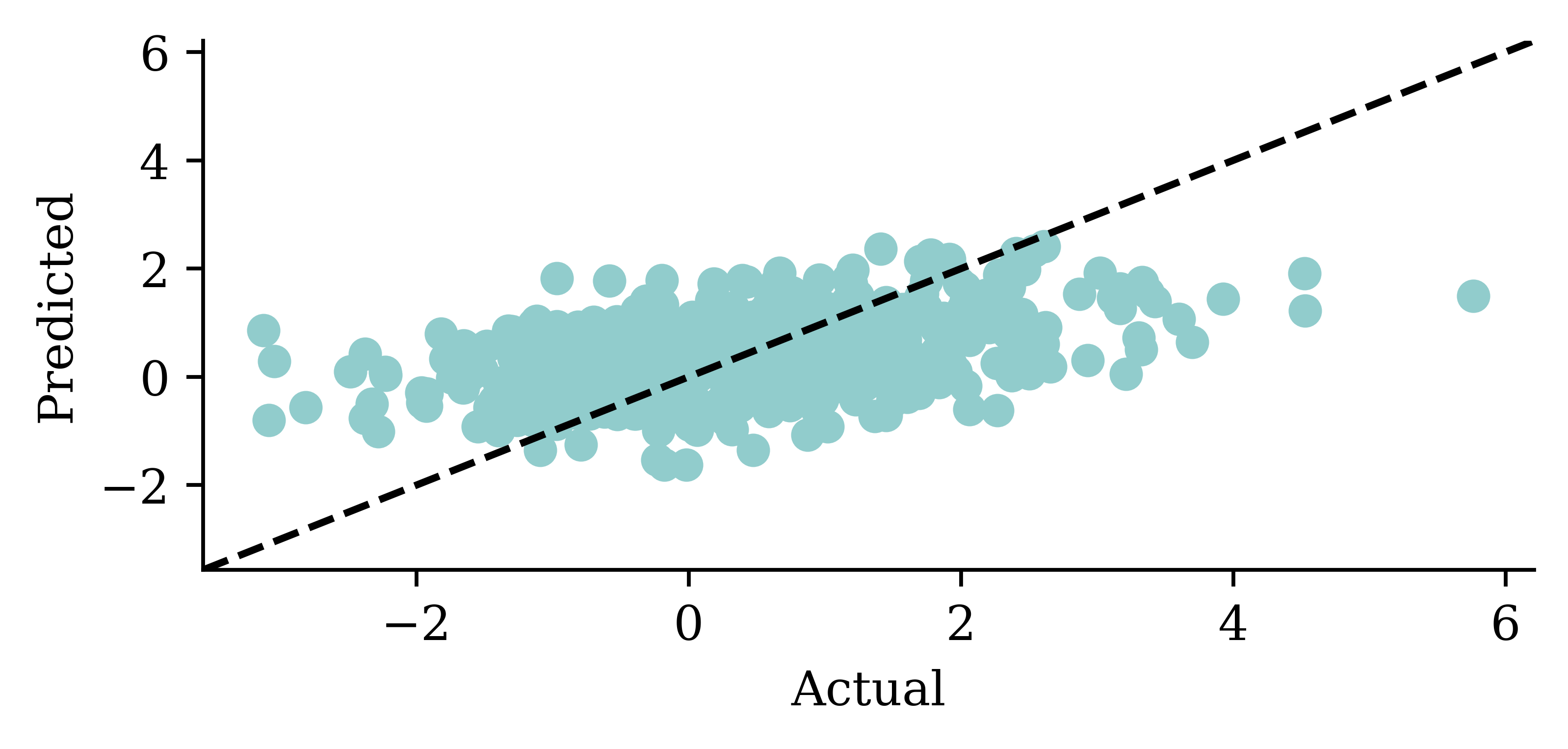
The raw prices from the linear regression are surprisingly accurate. Why is linear regression be so much better than the persistence and trend forecasts?
This is because the regression uses the last 40 days of log return data to make further predictions, unlike the persistence (assumes constant price) and trend (assume constant return) forecasts.
def autoregressive_forecast(model, X_val, suppress=False):""" Generate a multi-step forecast using the given model. """ multi_step = pd.Series(index=X_val.index, name="Multi Step")# Initialize the input data for forecasting input_data = X_val.iloc[0].values.reshape(1, -1)for i inrange(len(multi_step)):# Ensure input_data has the correct feature names input_df = pd.DataFrame(input_data, columns=X_val.columns)if suppress: next_value = model.predict(input_df, verbose=0)else: next_value = model.predict(input_df) multi_step.iloc[i] = next_value.flatten()[0]# Append that prediction to the input for the next forecastif i +1<len(multi_step): input_data = np.append(input_data[:, 1:], next_value).reshape(1, -1)return multi_step
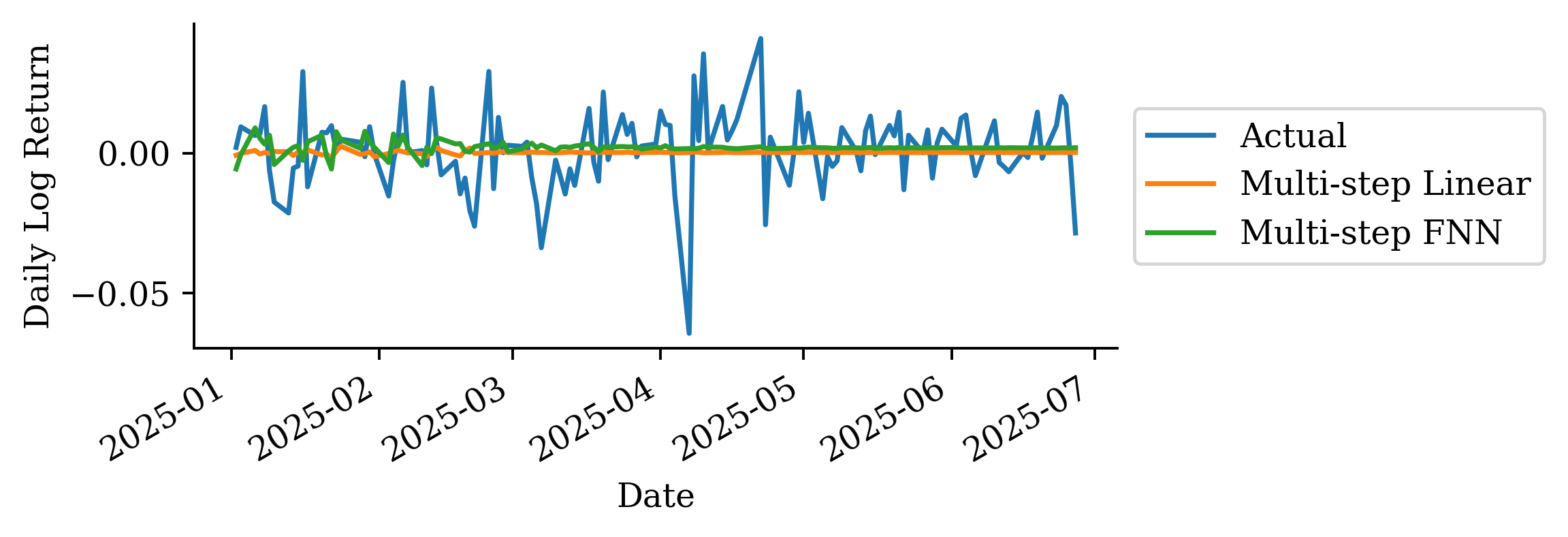
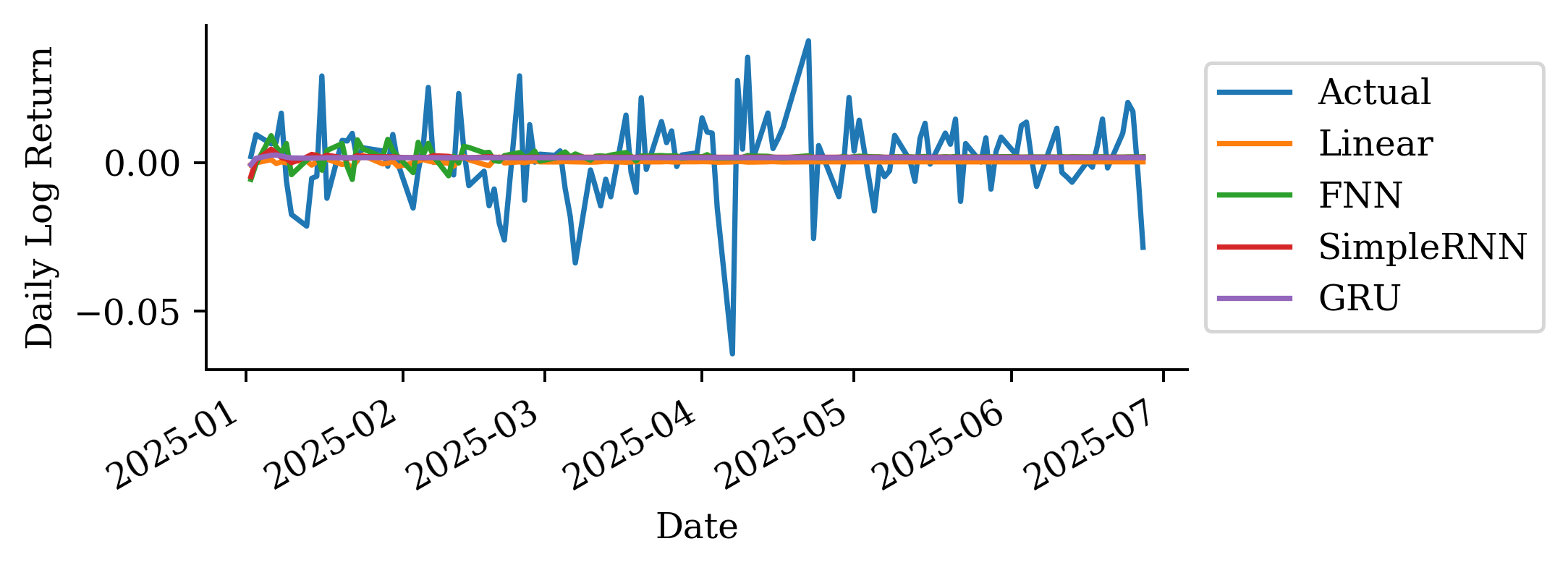
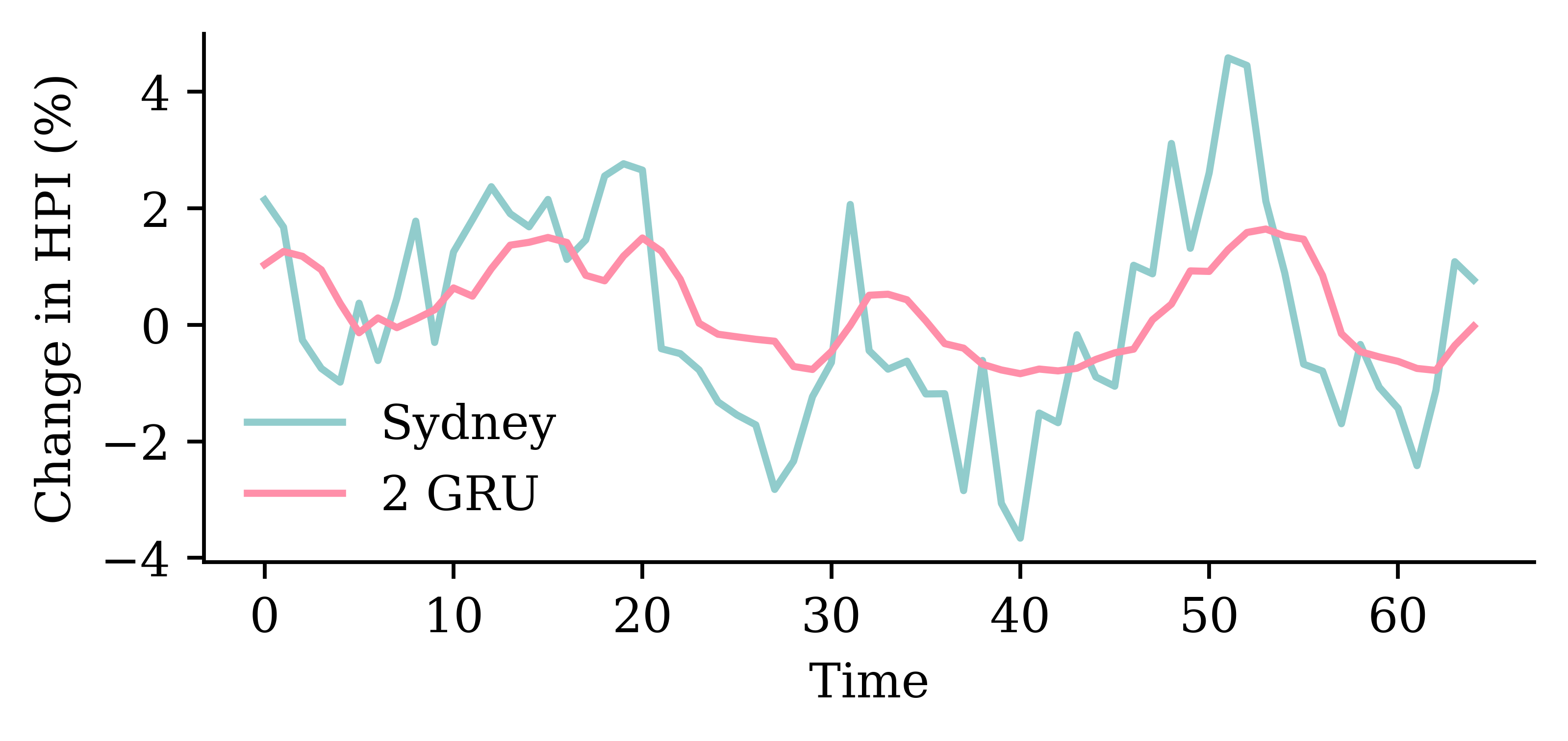
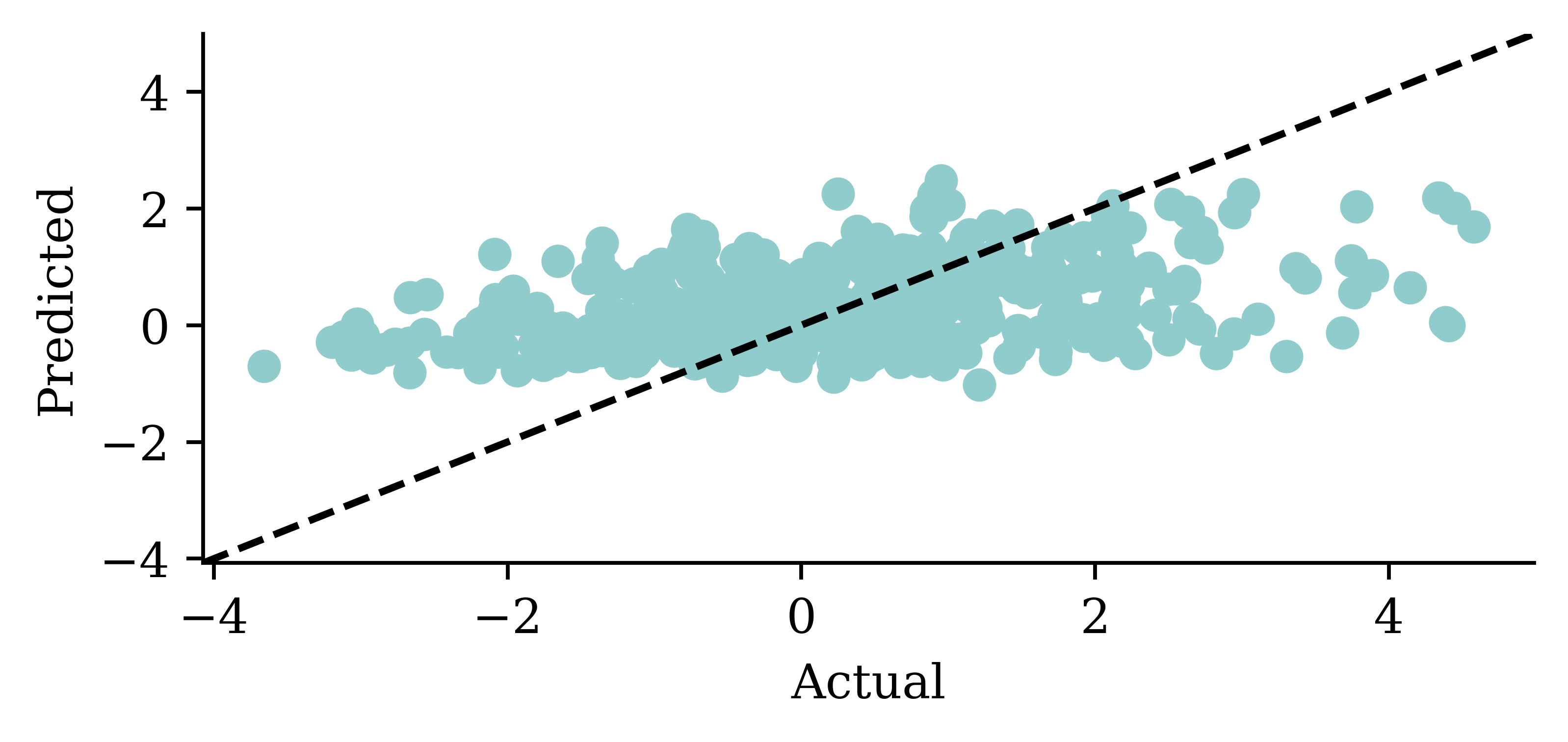
The variability in the one-step-ahead forecast is already small. The multi-step-ahead forecast reflects that and in fact the variance converges to 0 over time.
It’s best not to make predictions too far in the future. There is a lot of uncertainty, and that is evident in this plot and previous plots.
“It’s tough to make predictions, especially about the future.”
Neural network forecasts
Simple feedforward neural network
We can fit a simple feedforward NN. This is not much more complex than a linear model.
model = Sequential([ Rescaling(1/0.02), Dense(32, activation="leaky_relu"), Dense(1)]) # Linear activation for log returnsmodel.compile(optimizer="adam", loss="mean_absolute_error")
The above code does the following (NN architecture): 1. Rescale the data 2. Add one hidden layer with 32 neurons 3. Final output layer is 1 neuron 4. Compile the model with selected optimizer and loss function
if Path("aus_fin_fnn_model.keras").exists(): model = keras.models.load_model("aus_fin_fnn_model.keras")else: es = EarlyStopping(patience=15, restore_best_weights=True) model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=500, callbacks=[es], verbose=0) model.save("aus_fin_fnn_model.keras")model.summary()
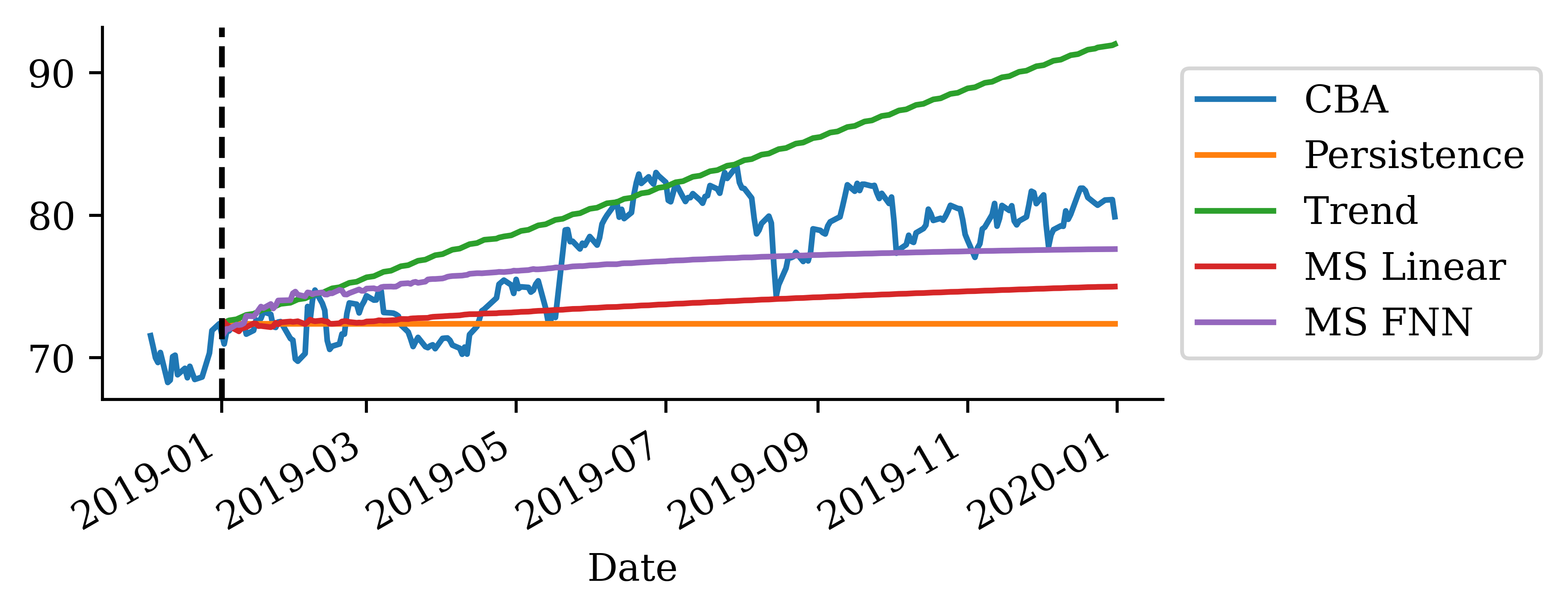
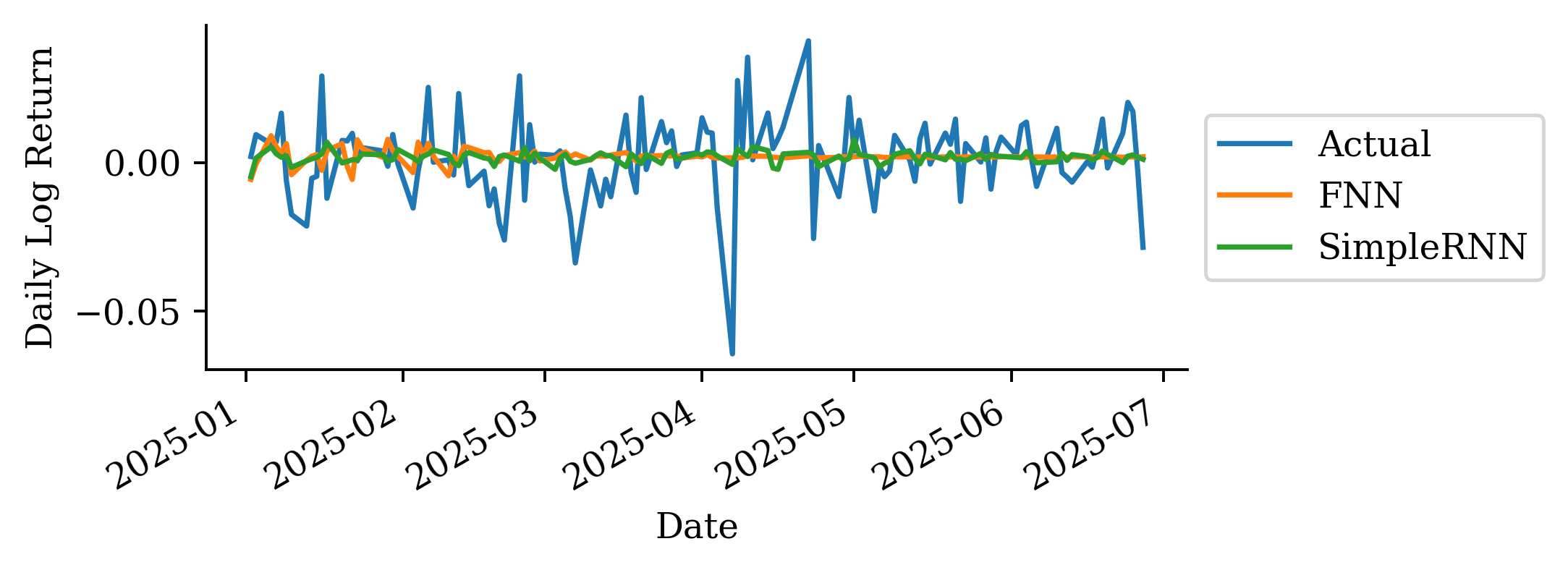
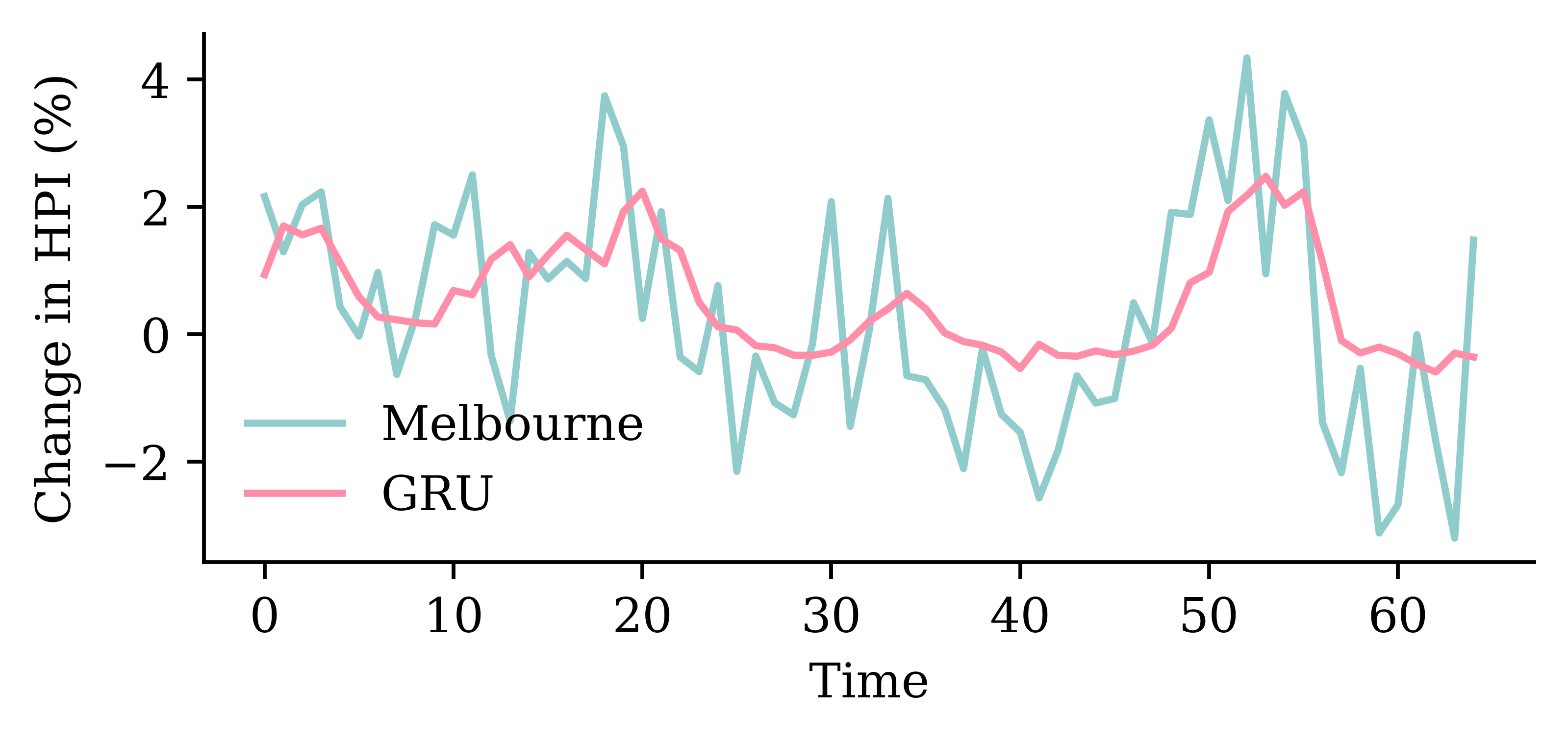
The predictions look okay for the first 2-3 months but then after that is more optimistic. Although, at the end of the forecast, the MS FNN prediction converges again to the actual price.
Based on MSE the FNN is better than the persistence forecast but worse than the other two.
Recurrent Neural Networks
Basic facts of RNNs
A recurrent neural network is a type of neural network that is designed to process sequences of data (e.g. time series, sentences).
A recurrent neural network is any network that contains a recurrent layer.
A recurrent layer is a layer that processes data in a sequence.
An RNN can have one or more recurrent layers.
Weights are shared over time; this allows the model to be used on arbitrary-length sequences.
Applications
Forecasting: revenue forecast, weather forecast, predict disease rate from medical history, etc.
Classification: given a time series of the activities of a visitor on a website, classify whether the visitor is a bot or a human.
Event detection: given a continuous data stream, identify the occurrence of a specific event. Example: Detect utterances like “Hey Alexa” from an audio stream.
Anomaly detection: given a continuous data stream, detect anything unusual happening. Example: Detect unusual activity on the corporate network.
Origin of the name of RNNs
A recurrence relation is an equation that expresses each element of a sequence as a function of the preceding ones. More precisely, in the case where only the immediately preceding element is involved, a recurrence relation has the form
u_n = \psi(n, u_{n-1}) \quad \text{ for } \quad n > 0.
Example: Factorial n! = n (n-1)! for n > 0 given 0! = 1.
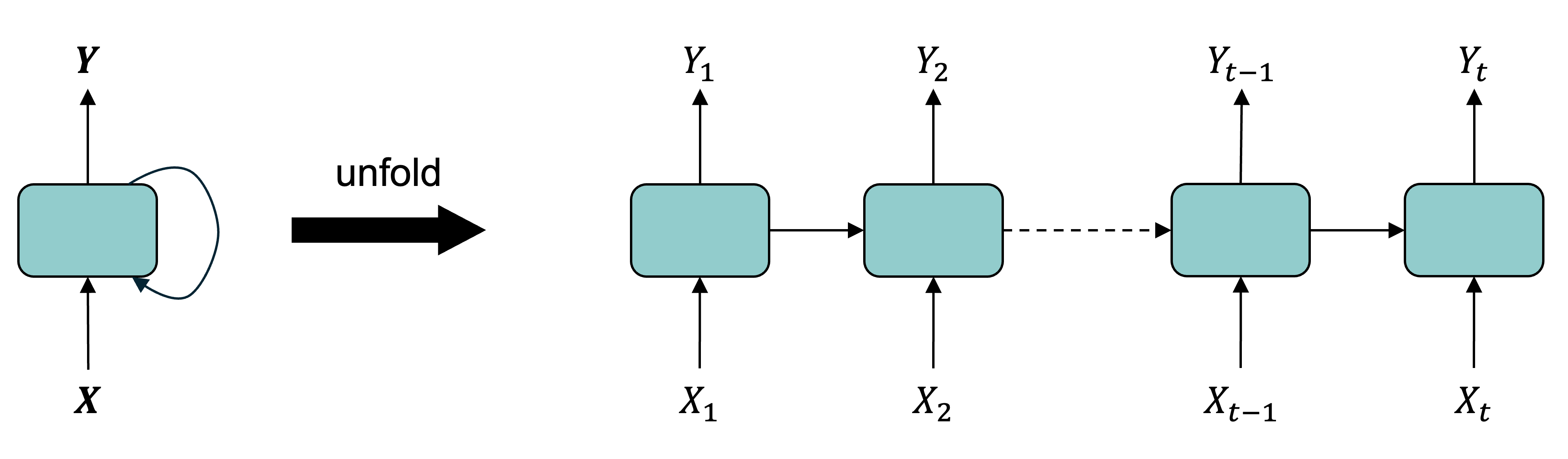
Diagram of an RNN cell
The RNN processes each data in the sequence one by one, while keeping memory of what came before.
Schematic of a recurrent neural network. E.g. SimpleRNN, LSTM, or GRU.
The RNN combines an input X_n with a processed state using inputs X_1,...,X_{n-1} to produce the output Y_n. RNNs have a cyclic information processing structure that enables them to pass information sequentially from previous inputs. RNNs can capture dependencies and patterns in sequential data, making them useful for analysing time series data.
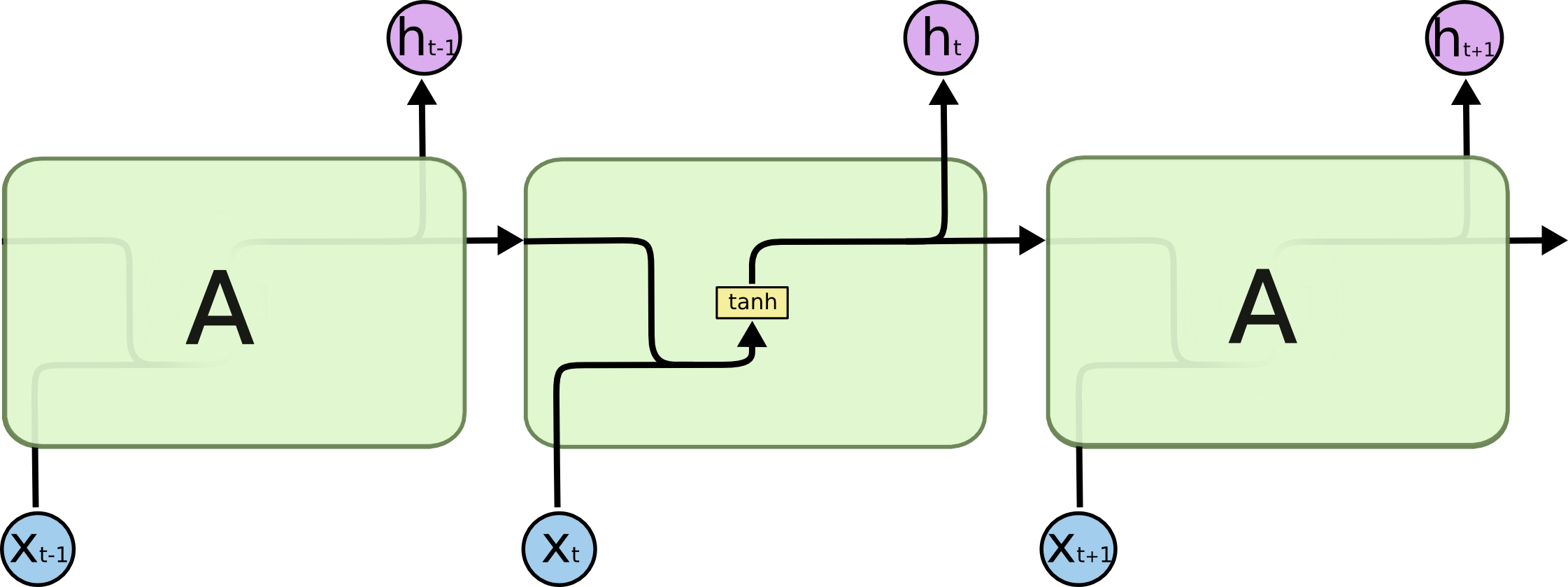
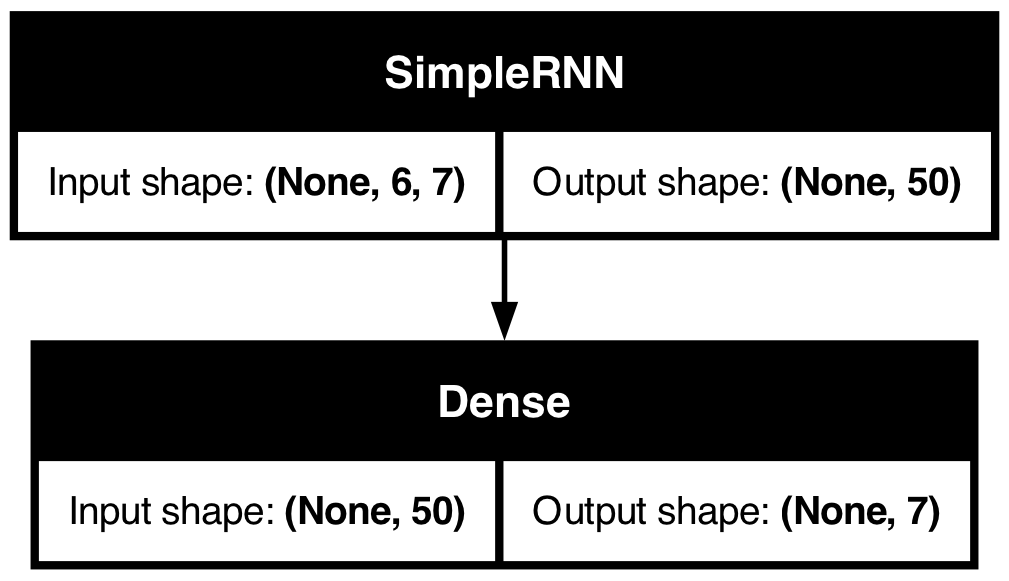
A SimpleRNN cell
Diagram of a SimpleRNN cell.
All the outputs before the final one are often discarded.
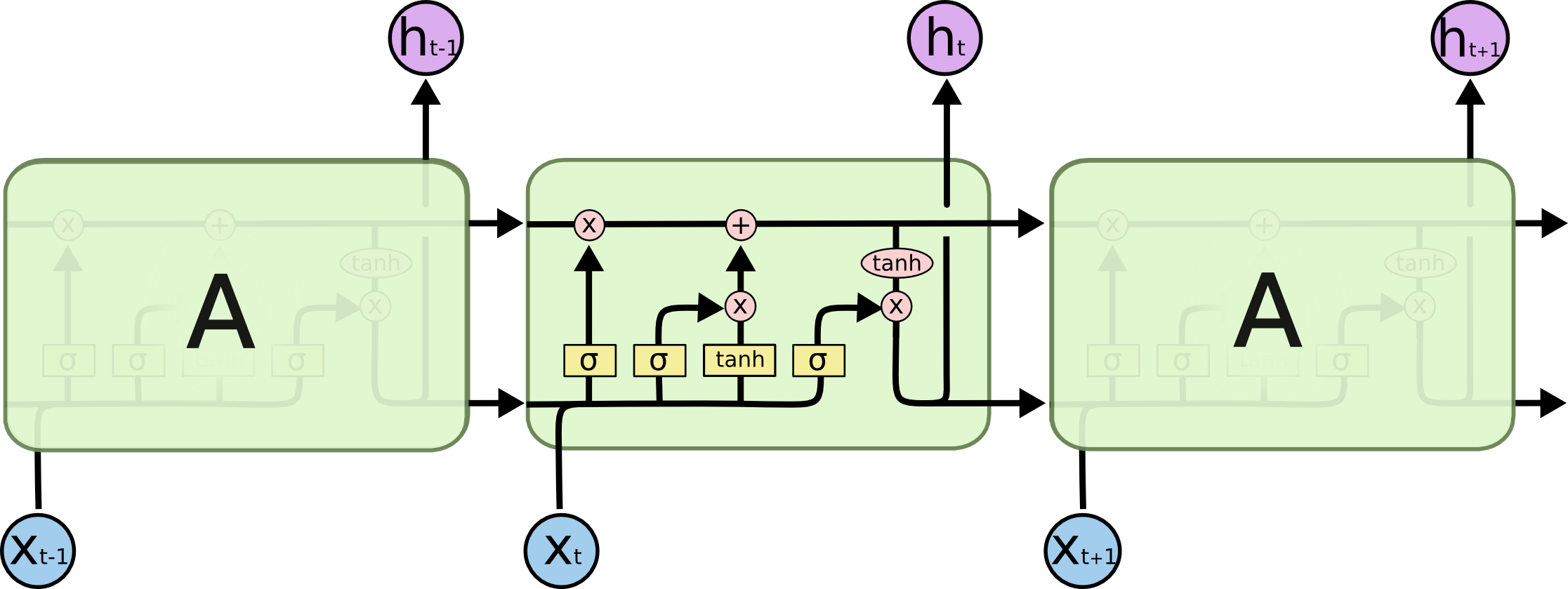
LSTM internals
Simple RNN structures encounter vanishing gradient problems, hence, struggle with learning long term dependencies. LSTM are designed to overcome this problem. LSTMs have a more complex network structure (contains more memory cells and gating mechanisms) and can better regulate the information flow.
GRU internals
GRUs are simpler compared to LSTM, hence, computationally more efficient than LSTMs.
Diagram of a GRU cell.
Stock prediction with recurrent networks
SimpleRNN
from keras.layers import SimpleRNN, Reshapemodel = Sequential([ Rescaling(1/0.02), Reshape((-1, 1)), SimpleRNN(64, activation="tanh"), Dense(1)]) # Linear activation for log returnsmodel.compile(optimizer="adam", loss="mean_absolute_error")
es = EarlyStopping(patience=15, restore_best_weights=True)model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=500, callbacks=[es], verbose=0)model.summary()
At each time step, a simple Recurrent Neural Network (RNN) takes an input vector x_t, incorporates it with the information from the previous hidden state {y}_{t-1} and produces an output vector at each time step y_t. The hidden state helps the network remember the context of the previous inputs and states, enabling it to make informed predictions about what comes next in the sequence. In a simple RNN, the output at time (t-1) is the same as the hidden state at time t.
SimpleRNN (in batches)
The difference between RNN and RNNs with batch processing lies in the way how the neural network handles sequences of input data. With batch processing, the model processes multiple (b) input sequences simultaneously. The training data is grouped into batches, and the weights are updated based on the average error across the entire batch. Batch processing often results in more stable weight updates, as the model learns from a diverse set of examples in each batch, reducing the impact of noise in individual sequences.
Say we operate on batches of size b, then \boldsymbol{Y}_t \in \mathbb{R}^{b \times d}.
The main equation of a SimpleRNN, given \boldsymbol{Y}_0 = \boldsymbol{0}, is \boldsymbol{Y}_t = \psi\bigl( \boldsymbol{X}_t \boldsymbol{W}_x + \boldsymbol{Y}_{t-1} \boldsymbol{W}_y + \boldsymbol{b} \bigr) . Here,
\begin{aligned}
&\boldsymbol{X}_t \in \mathbb{R}^{b \times m}, \boldsymbol{W}_x \in \mathbb{R}^{m \times d}, \\
&\boldsymbol{Y}_{t-1} \in \mathbb{R}^{b \times d}, \boldsymbol{W}_y \in \mathbb{R}^{d \times d}, \text{ and } \boldsymbol{b} \in \mathbb{R}^{d}.
\end{aligned}
Selects the first two slices along the first dimension. Since the tensor of dimensions (4,3,2), X[:2] selects the first two slices (0 and 1) along the first dimension, and returns a sub-tensor of shape (2,3,2).
Selects the last two slices along the first dimension. The first dimension (axis=0) has size 4. Therefore, X[2:] selects the last two slices (2 and 3) along the first dimension, and returns a sub-tensor of shape (2,3,2).
1from keras.layers import SimpleRNN2random.seed(1234)3model = Sequential([SimpleRNN(output_size, activation="sigmoid")])4model.compile(loss="binary_crossentropy", metrics=["accuracy"])5hist = model.fit(X, y, epochs=500, verbose=False)6model.evaluate(X, y, verbose=False)
1
Imports the SimpleRNN layer from the Keras library
2
Sets the seed for the random number generator to ensure reproducibility
3
Defines a simple RNN with one output node and sigmoid activation function
4
Specifies binary crossentropy as the loss function (usually used in classification problems), and specifies “accuracy” as the metric to be monitored during training
5
Trains the model for 500 epochs and saves output as hist
6
Evaluates the model to obtain a value for the loss and accuracy
[8.05906867980957, 0.5]
The predicted probabilities on the training set are:
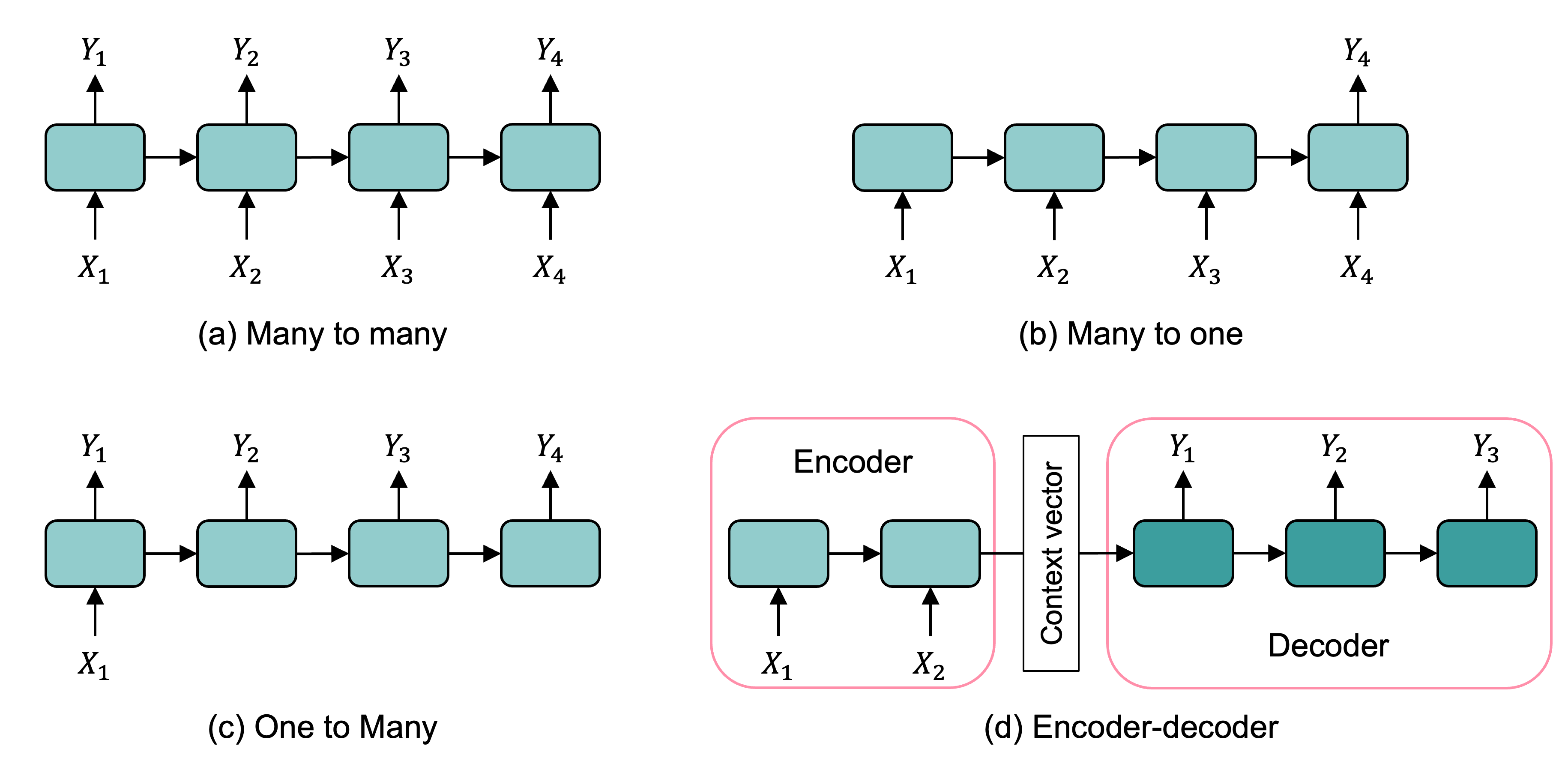
Categories of recurrent neural networks: sequence to sequence, sequence to vector, vector to sequence, encoder-decoder network.
Input and output sequences
Sequence to sequence: Useful for predicting time series such as using prices over the last N days to output the prices shifted one day into the future (i.e. from N-1 days ago to tomorrow.)
Sequence to vector: ignore all outputs in the previous time steps except for the last one. Example: give a sentiment score to a sequence of words corresponding to a movie review.
Input and output sequences
Vector to sequence: feed the network the same input vector over and over at each time step and let it output a sequence. Example: given that the input is an image, find a caption for it. The image is treated as an input vector (pixels in an image do not follow a sequence). The caption is a sequence of textual description of the image. A dataset containing images and their descriptions is the input of the RNN.
The Encoder-Decoder: The encoder is a sequence-to-vector network. The decoder is a vector-to-sequence network. Example: Feed the network a sequence in one language. Use the encoder to convert the sentence into a single vector representation. The decoder decodes this vector into the translation of the sentence in another language.
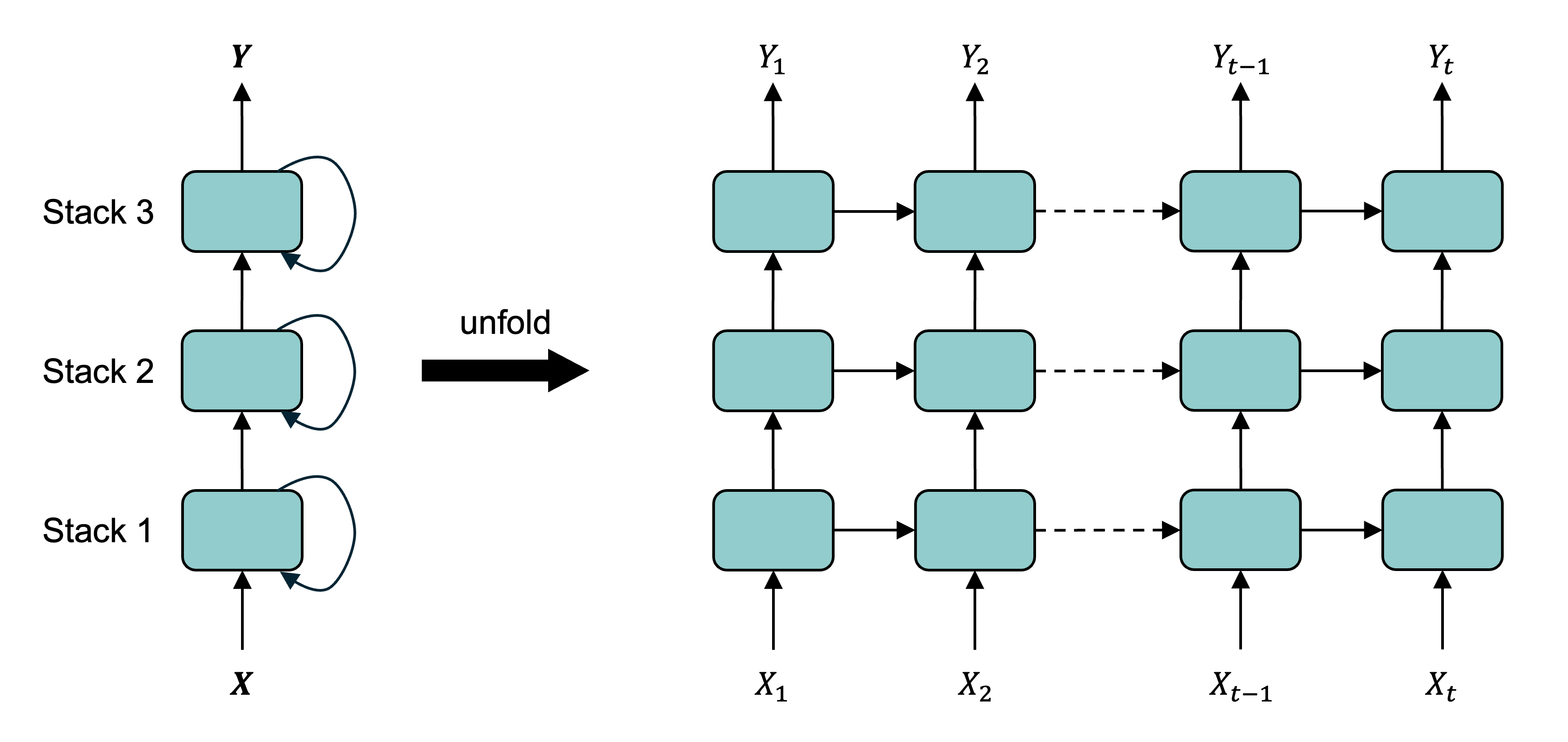
Recurrent layers can be stacked.
Deep RNN unrolled through time.
The output from a hidden state can be used as input for another hidden layer of RNN processing. This is called stacking, or a stacked RNN.
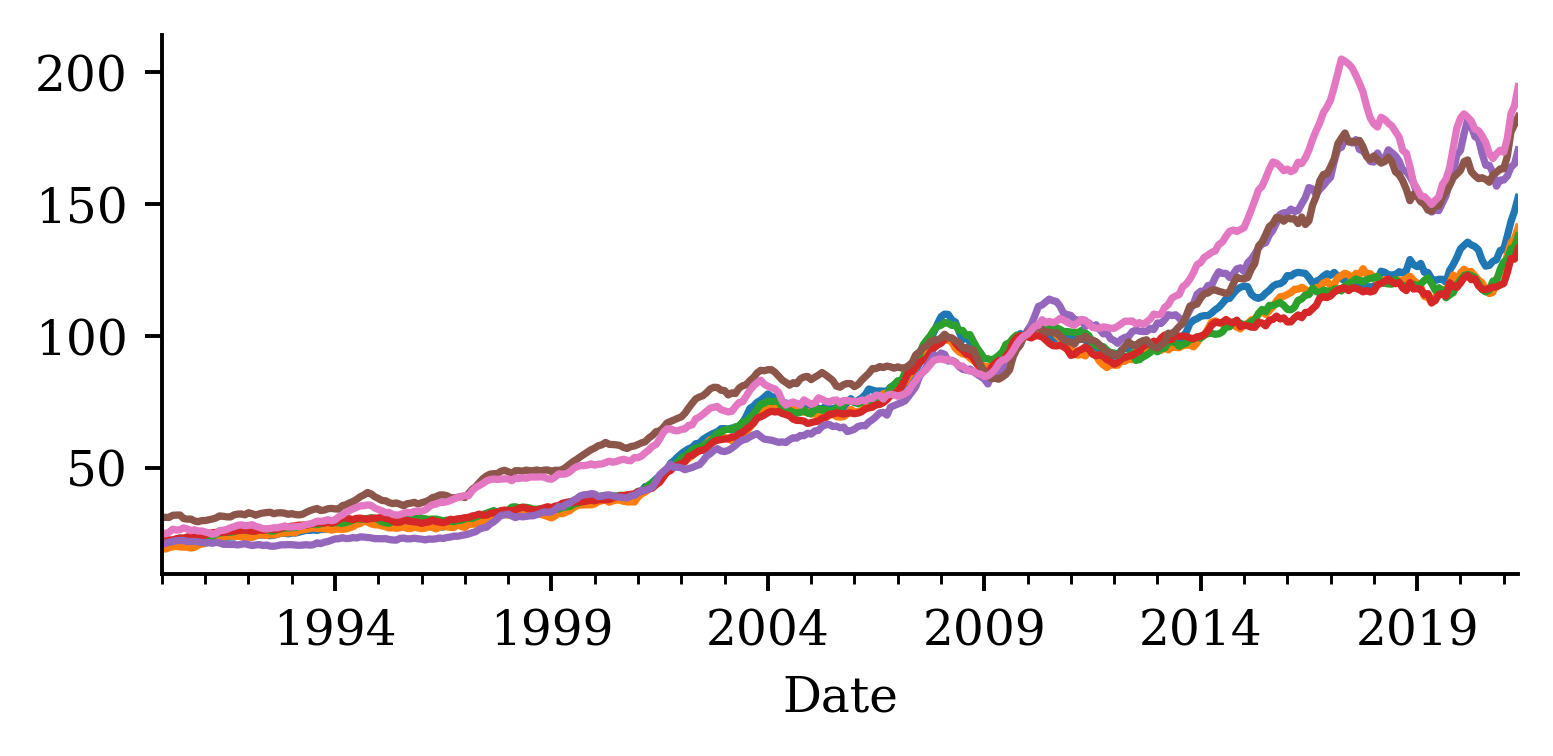
CoreLogic Hedonic Home Value Index
Australian House Price Indices
Note
I apologise in advance for not being able to share this dataset with anyone (it is not mine to share).
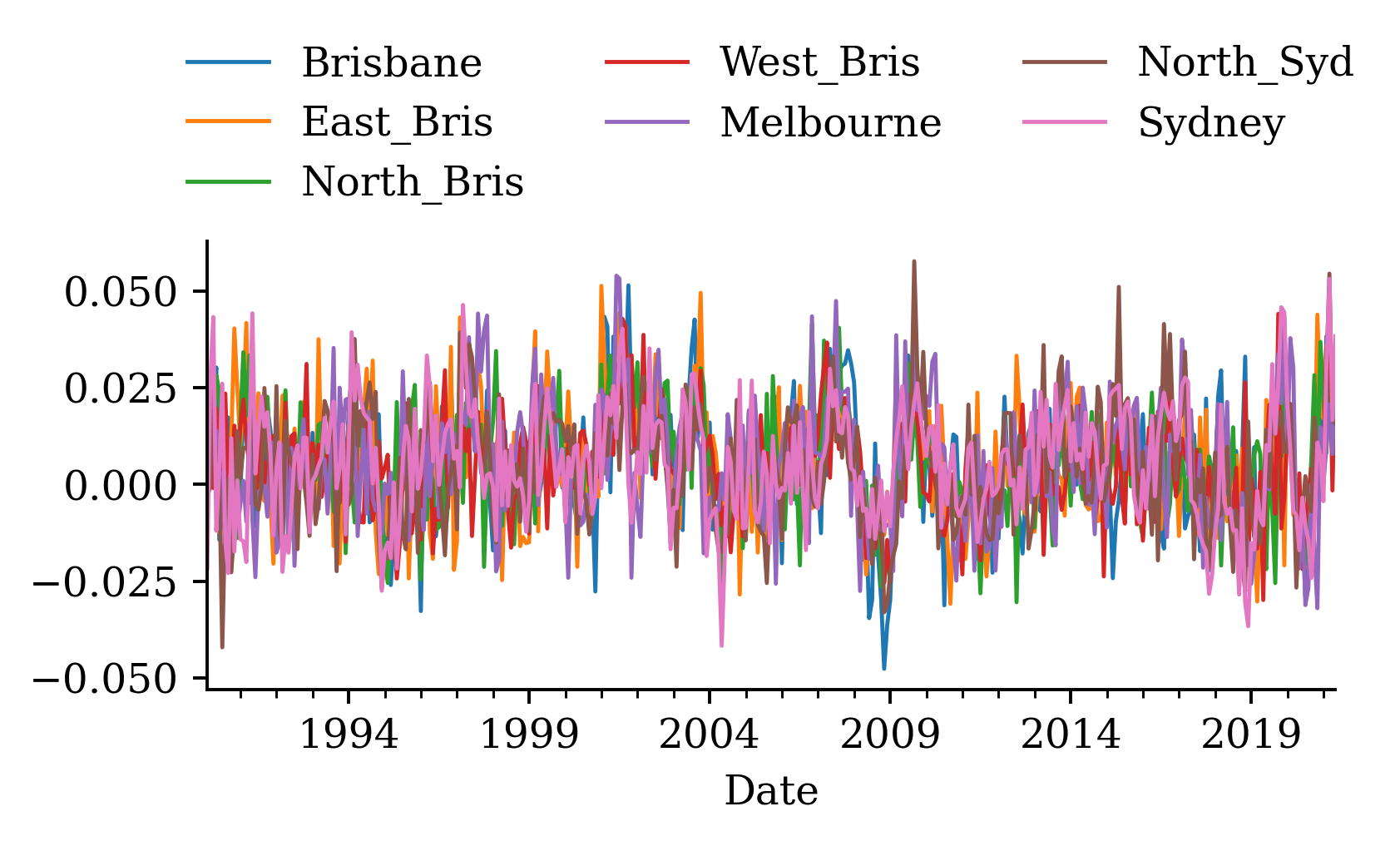
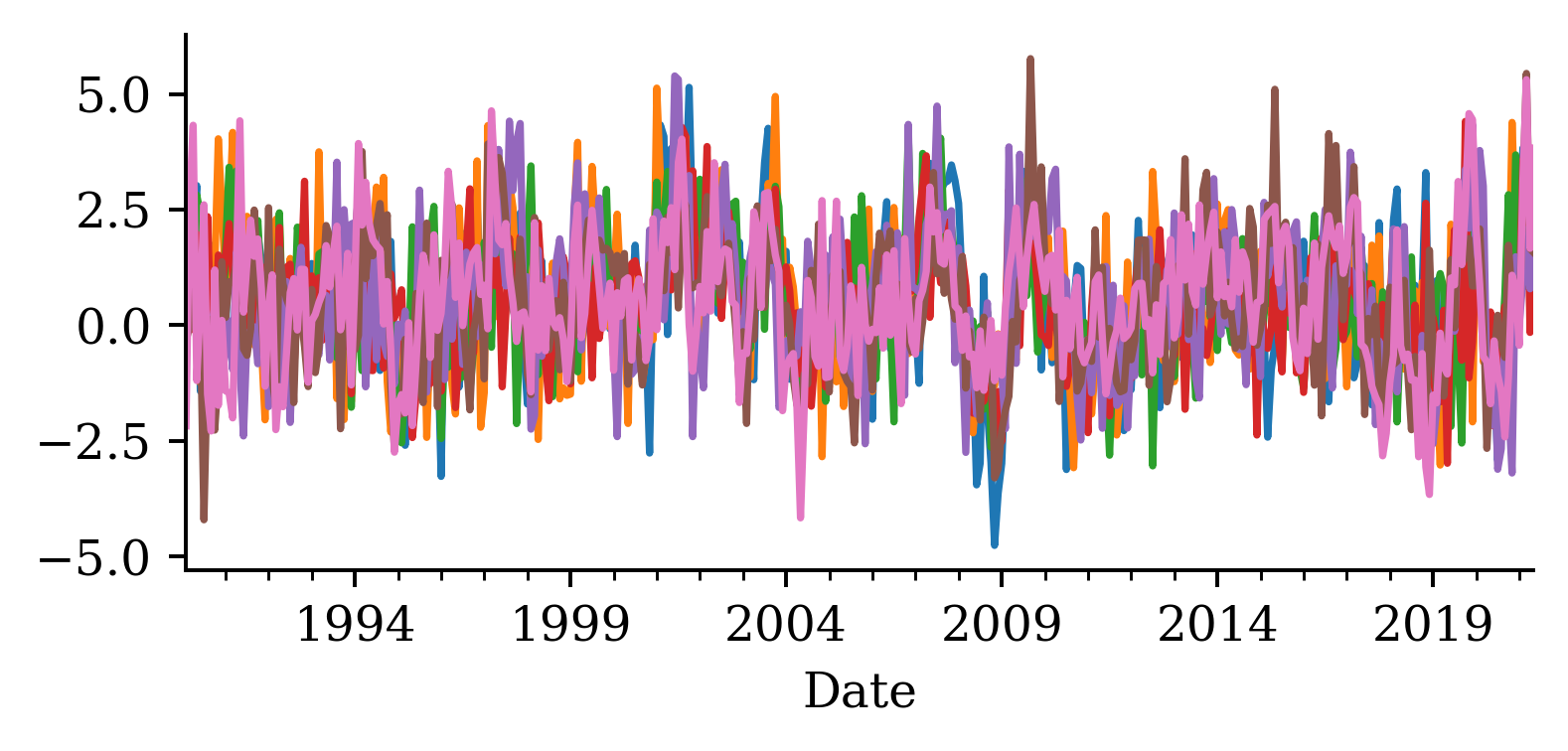
We can use numpy to convert a time series into subsequences/chunks using a sliding window.
integers = np.arange(10)seq_len =3X = np.stack([integers[i : i + seq_len] for i inrange(len(integers) - seq_len)])y = integers[seq_len:]for i inrange(len(X)):print(X[i].tolist(), int(y[i]))
def make_sequences(data, targets, seq_len, start_index=0, end_index=None): data = np.asarray(data, dtype=np.float32) targets = np.asarray(targets, dtype=np.float32)if end_index isNone: end_index =len(data) n = end_index - start_index - seq_len +1 X = np.stack([data[start_index + i : start_index + i + seq_len] for i inrange(n)]) y = targets[start_index : start_index + n]return X, y
# Num. of input time series.num_ts = changes.shape[1]# How many prev. months to use.seq_length =6# Predict the next month ahead.ahead =1# The index of the first target.delay = seq_length + ahead -1
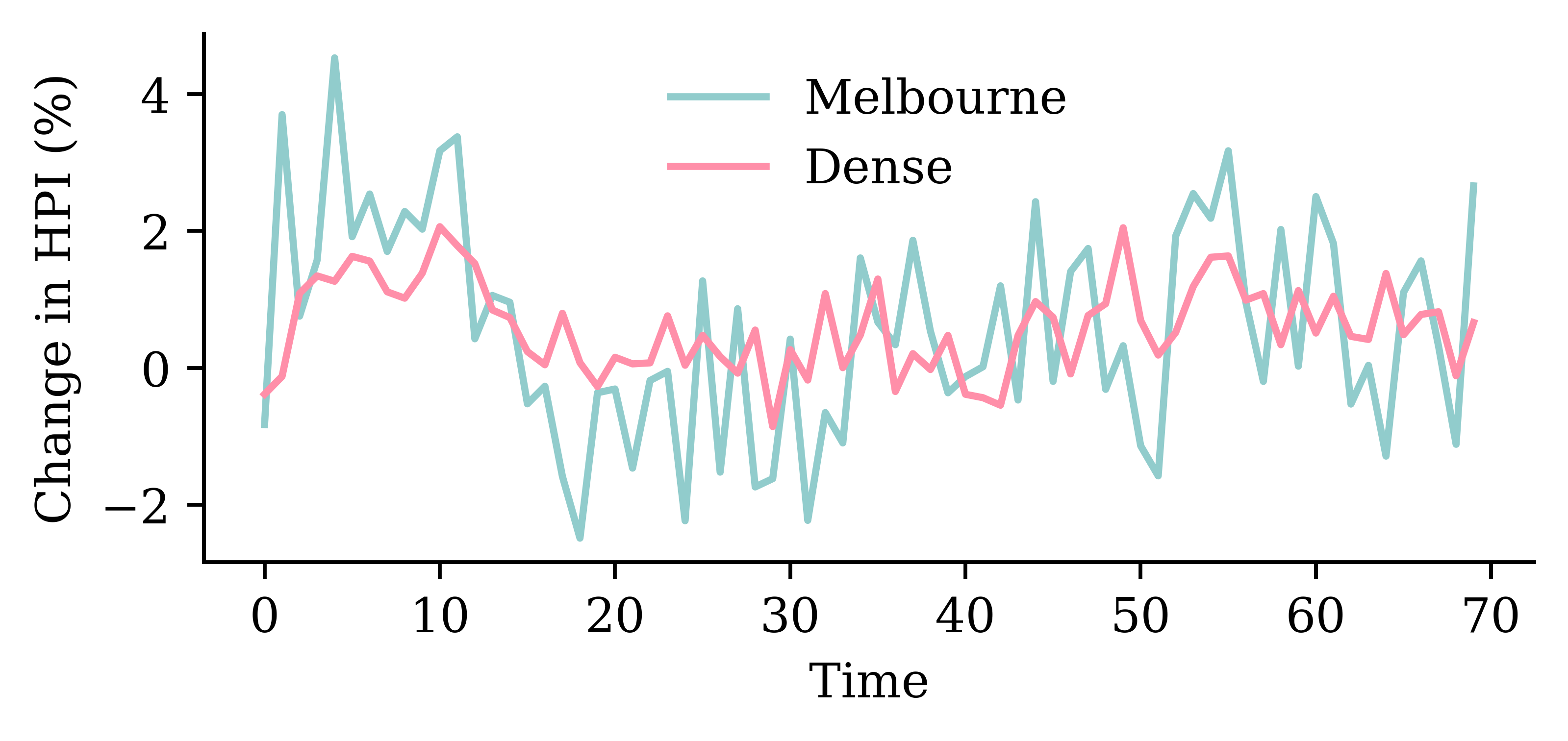
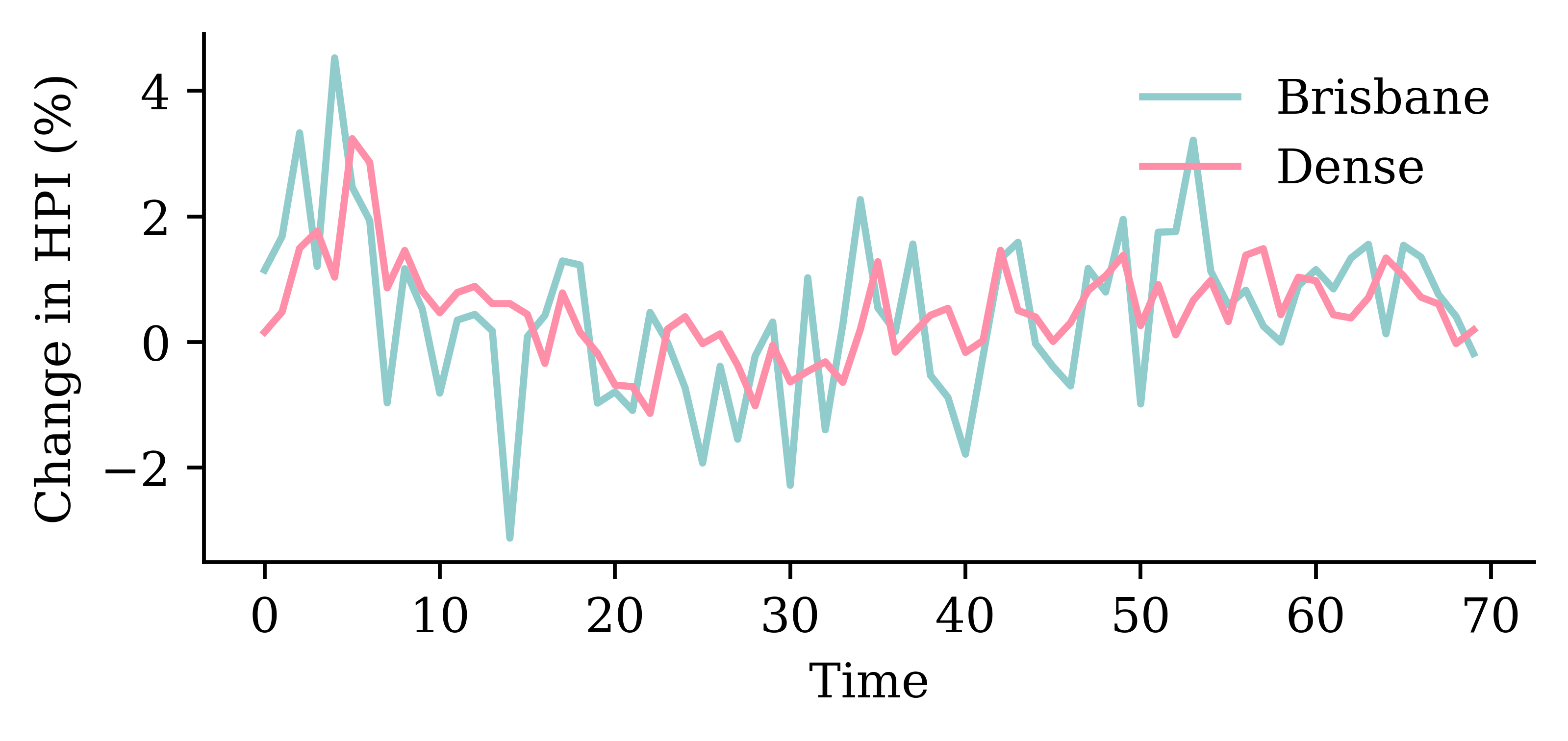
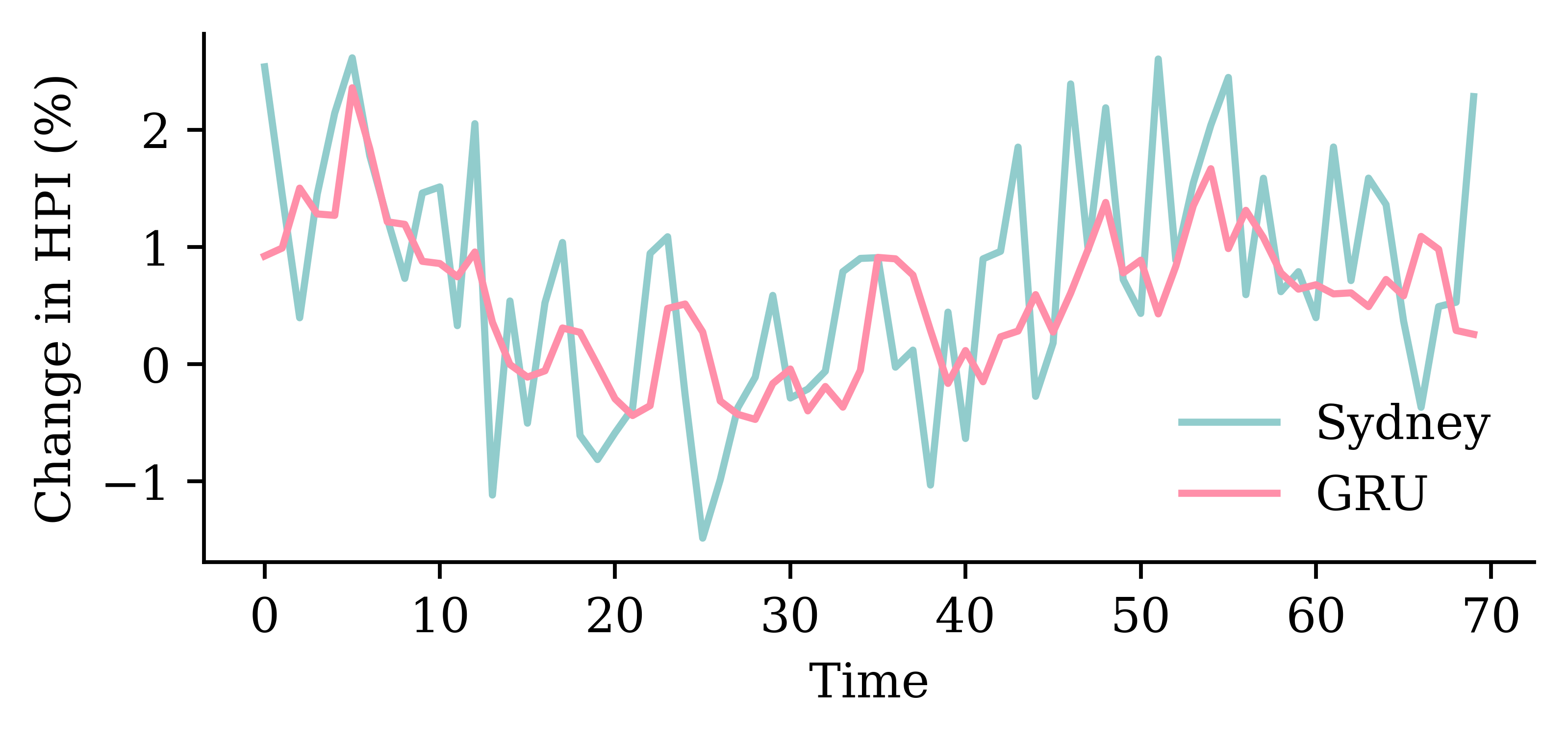
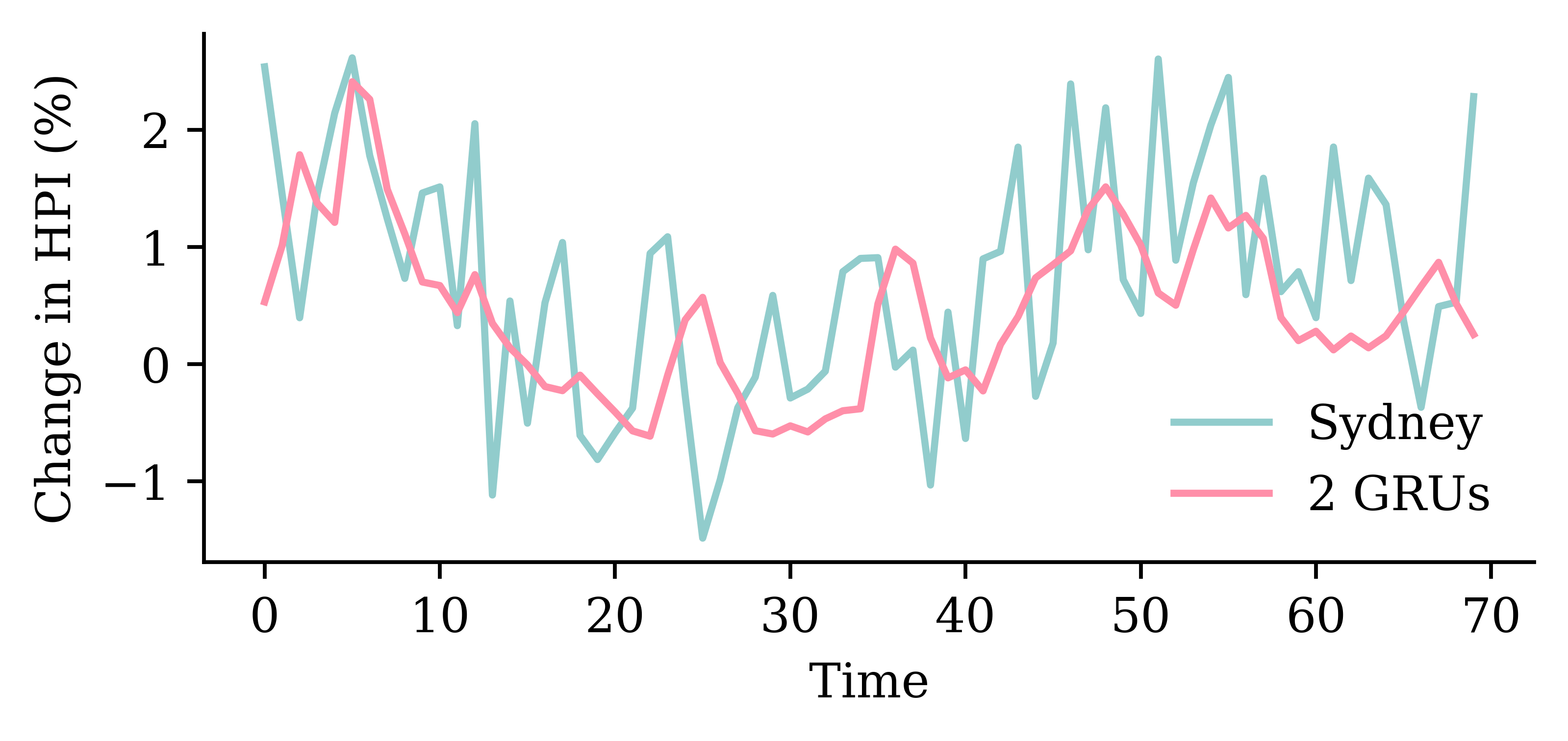
# Which suburb to predict.target_suburb = changes["Sydney"]X_train, y_train = make_sequences( changes[:-delay], target_suburb[delay:], seq_length, end_index=num_train,)
This model has 3191 parameters.
Epoch 76: early stopping
Restoring model weights from the end of the best epoch: 26.
CPU times: user 790 ms, sys: 55.8 ms, total: 846 ms
Wall time: 811 ms
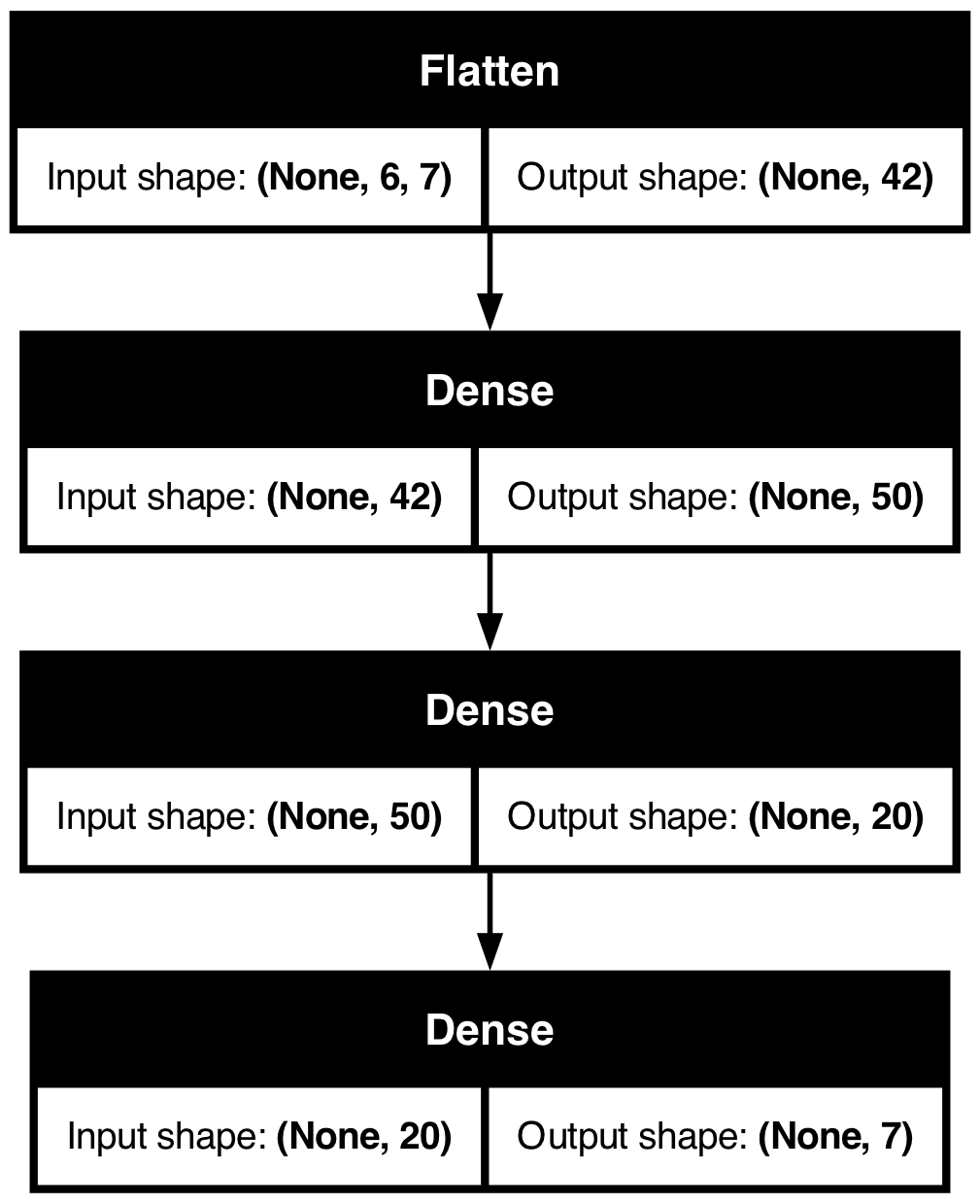
Plot the model
from keras.utils import plot_modelplot_model(model_dense, show_shapes=True)
Assess the fits
model_dense.evaluate(X_val, y_val, verbose=0)
1.3529319763183594
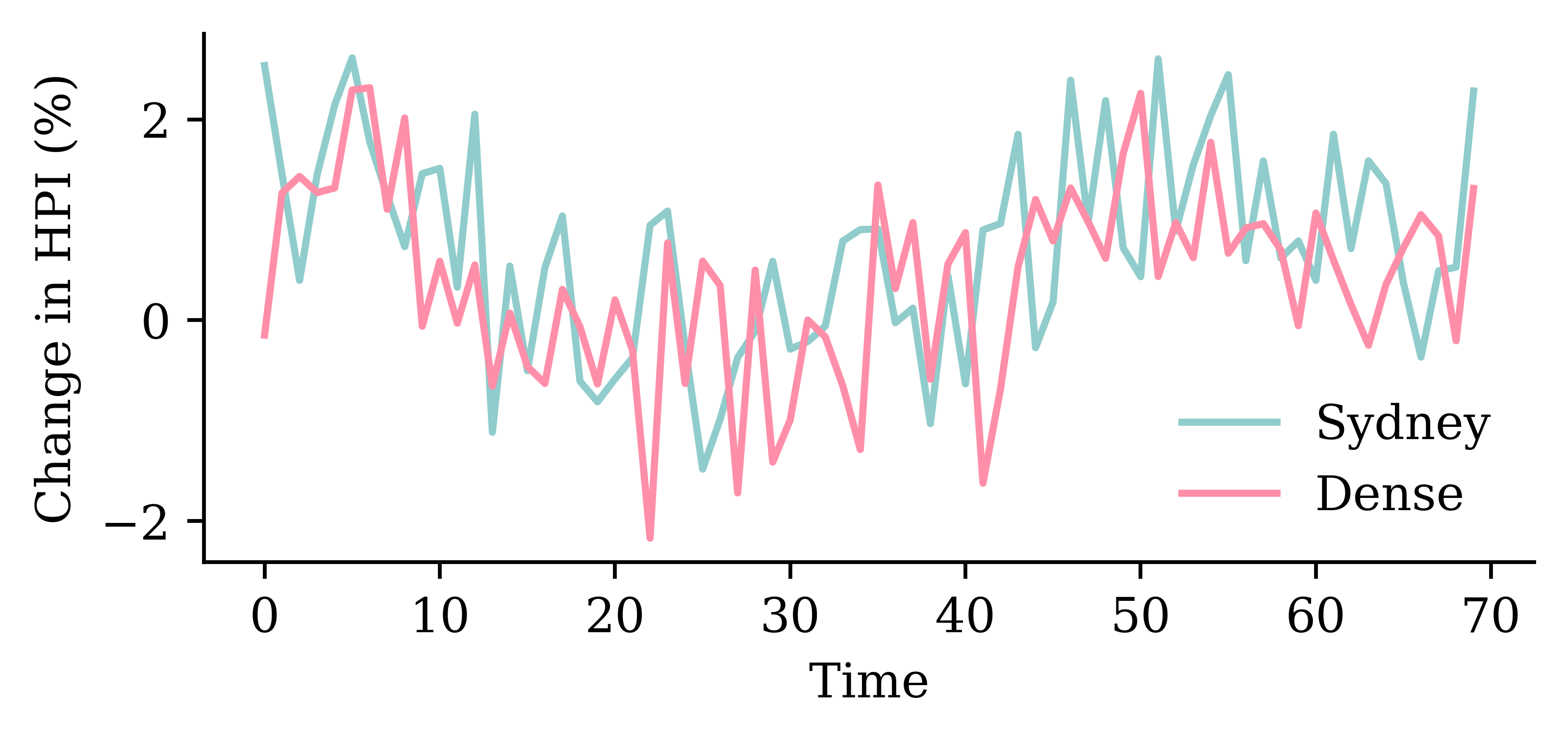
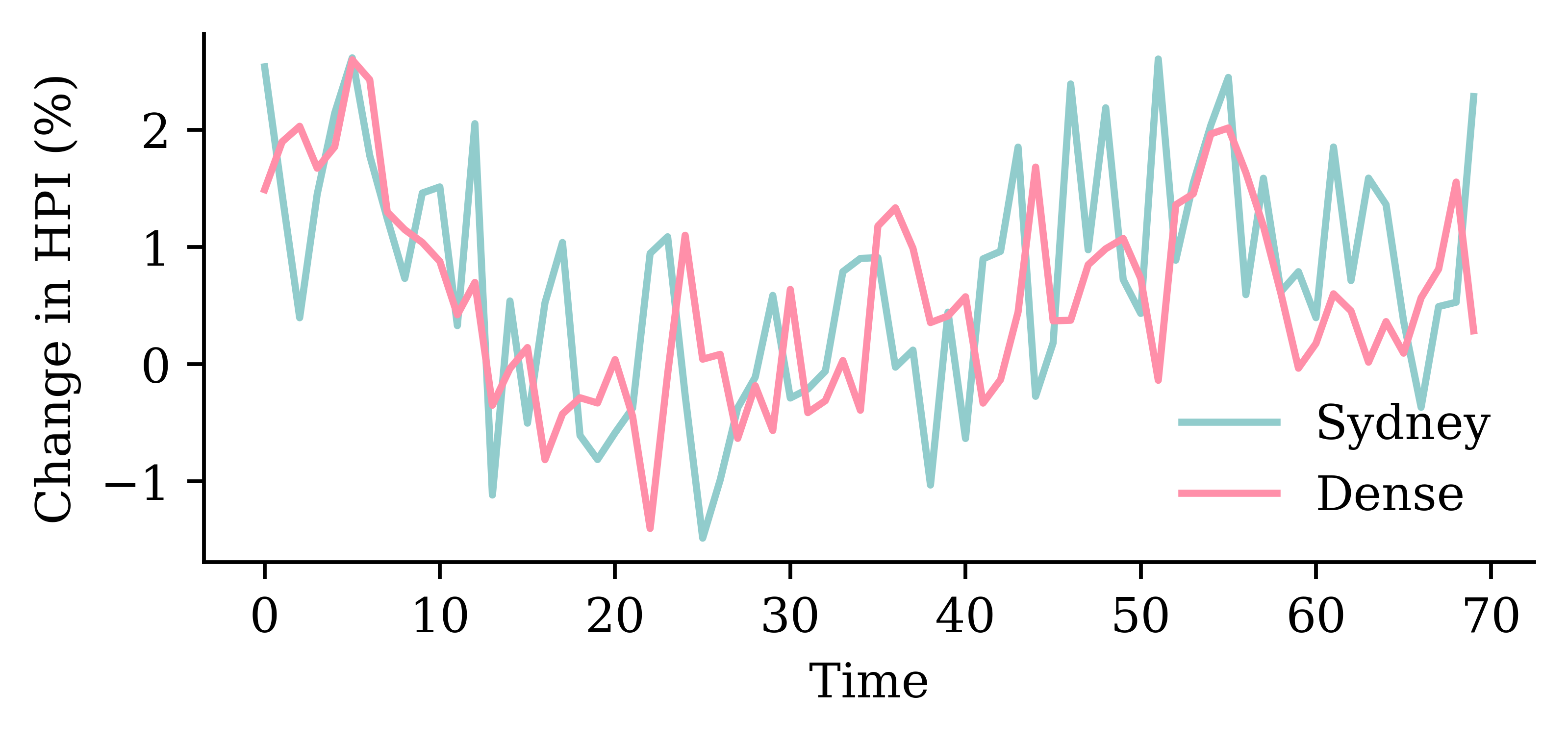
Code
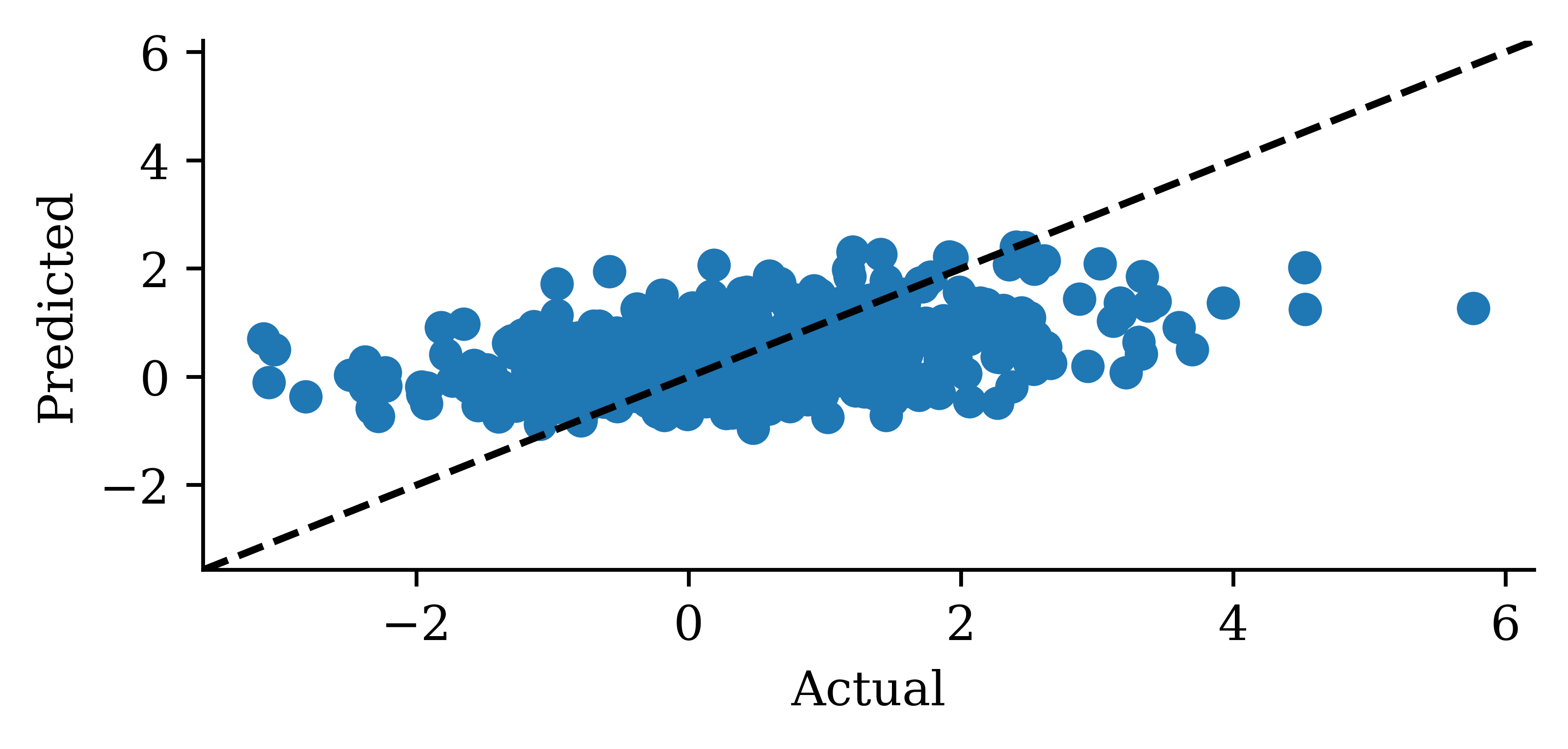
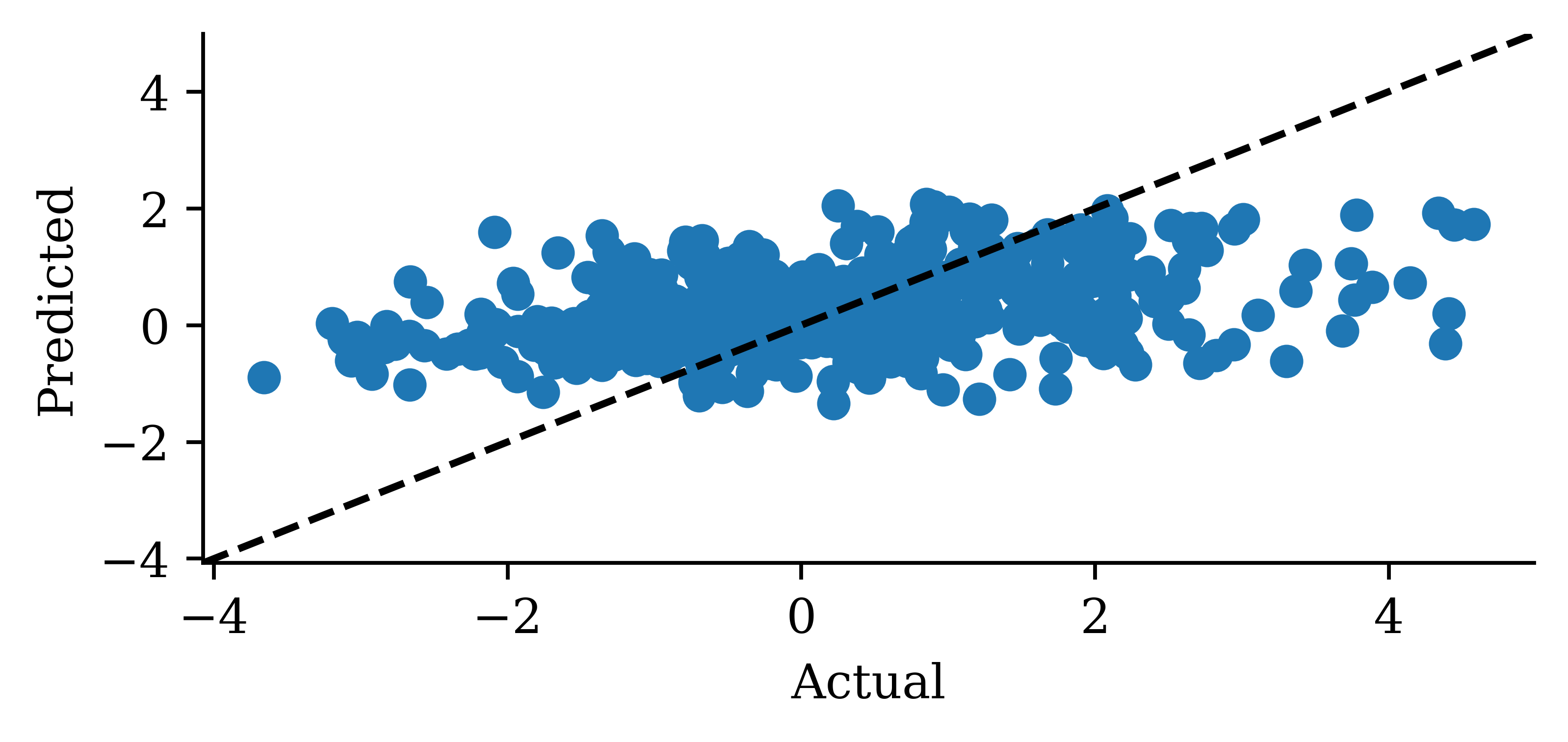
y_pred = model_dense.predict(X_val, verbose=0)plt.plot(y_val, label="Sydney")plt.plot(y_pred, label="Dense")plt.xlabel("Time")plt.ylabel("Change in HPI (%)")plt.legend(frameon=False);
This model has 2951 parameters.
Epoch 53: early stopping
Restoring model weights from the end of the best epoch: 3.
CPU times: user 1.04 s, sys: 48.1 ms, total: 1.09 s
Wall time: 1.06 s
Plot the model
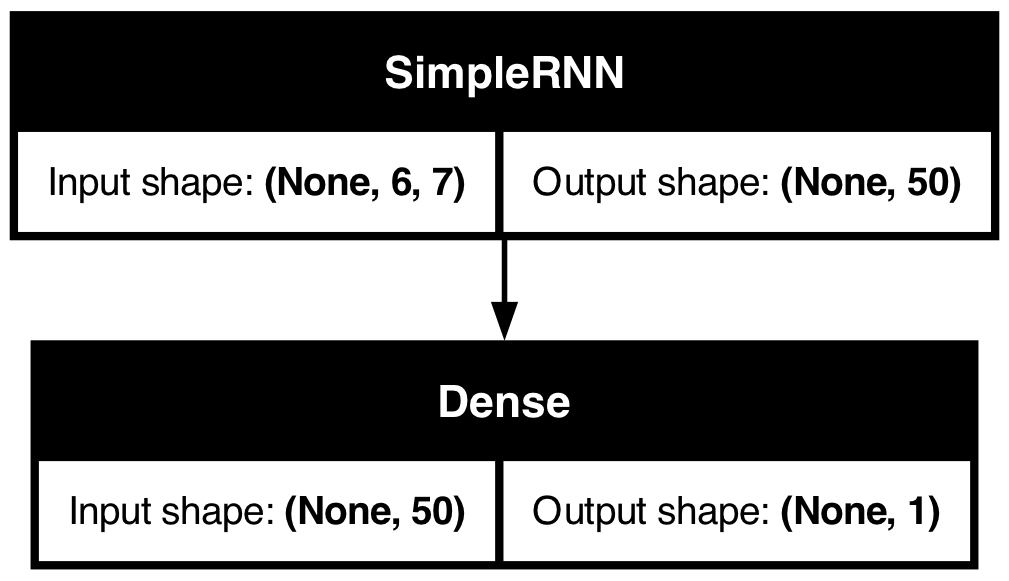
plot_model(model_simple, show_shapes=True)
Assess the fits
model_simple.evaluate(X_val, y_val, verbose=0)
0.8649981021881104
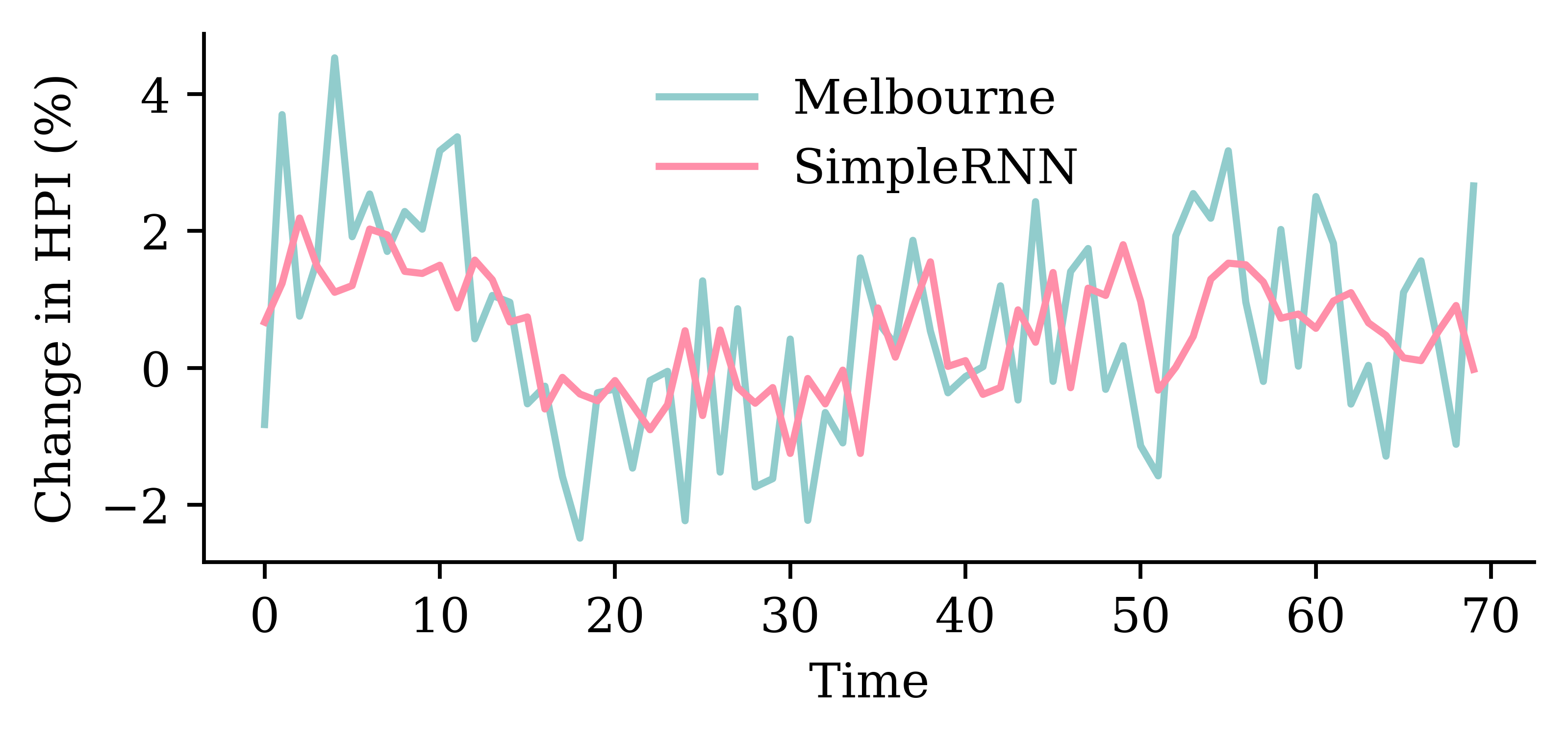
Code
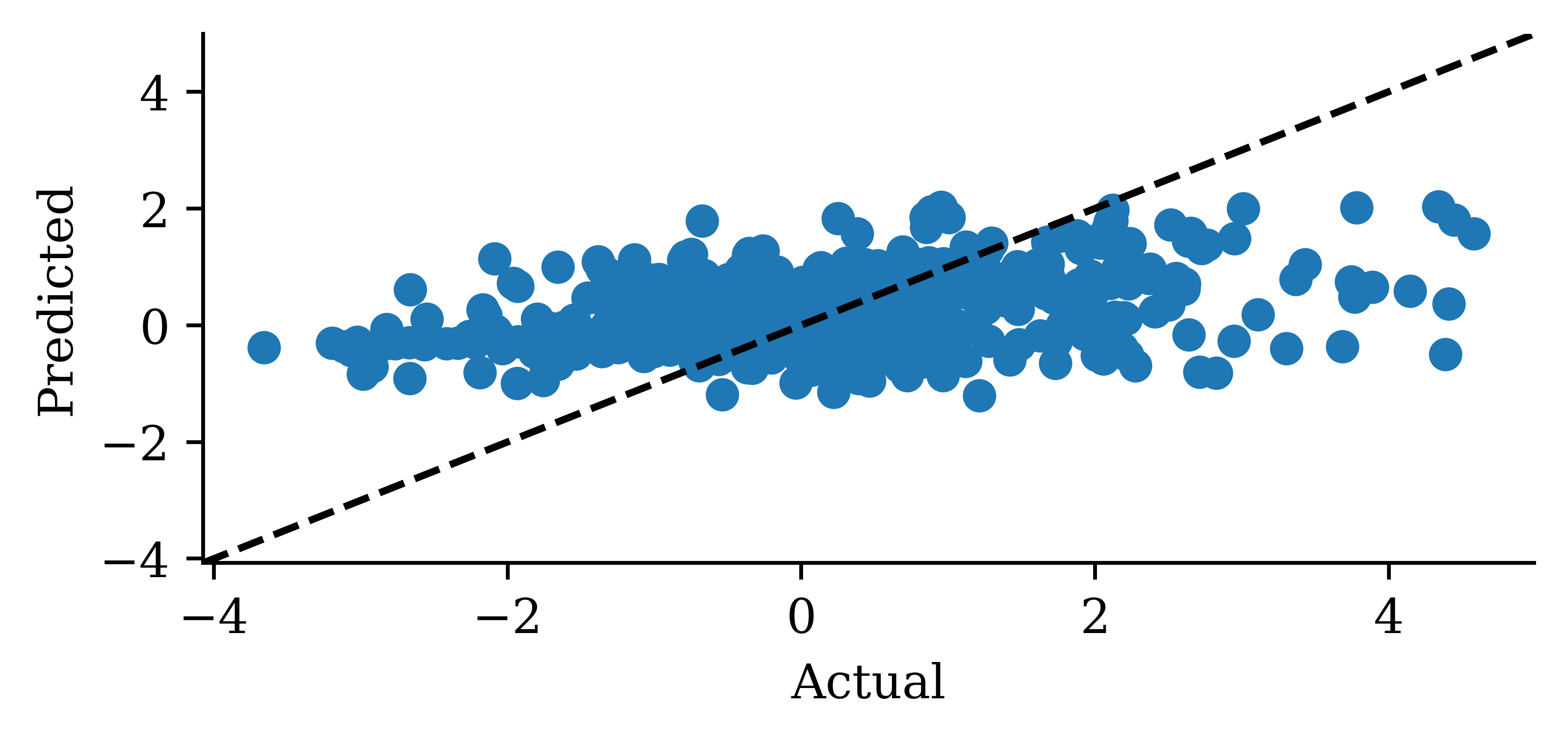
y_pred = model_simple.predict(X_val, verbose=0)plt.plot(y_val, label="Sydney")plt.plot(y_pred, label="SimpleRNN")plt.xlabel("Time")plt.ylabel("Change in HPI (%)")plt.legend(frameon=False);
Epoch 58: early stopping
Restoring model weights from the end of the best epoch: 8.
CPU times: user 1.45 s, sys: 61.3 ms, total: 1.51 s
Wall time: 1.48 s
Assess the fits
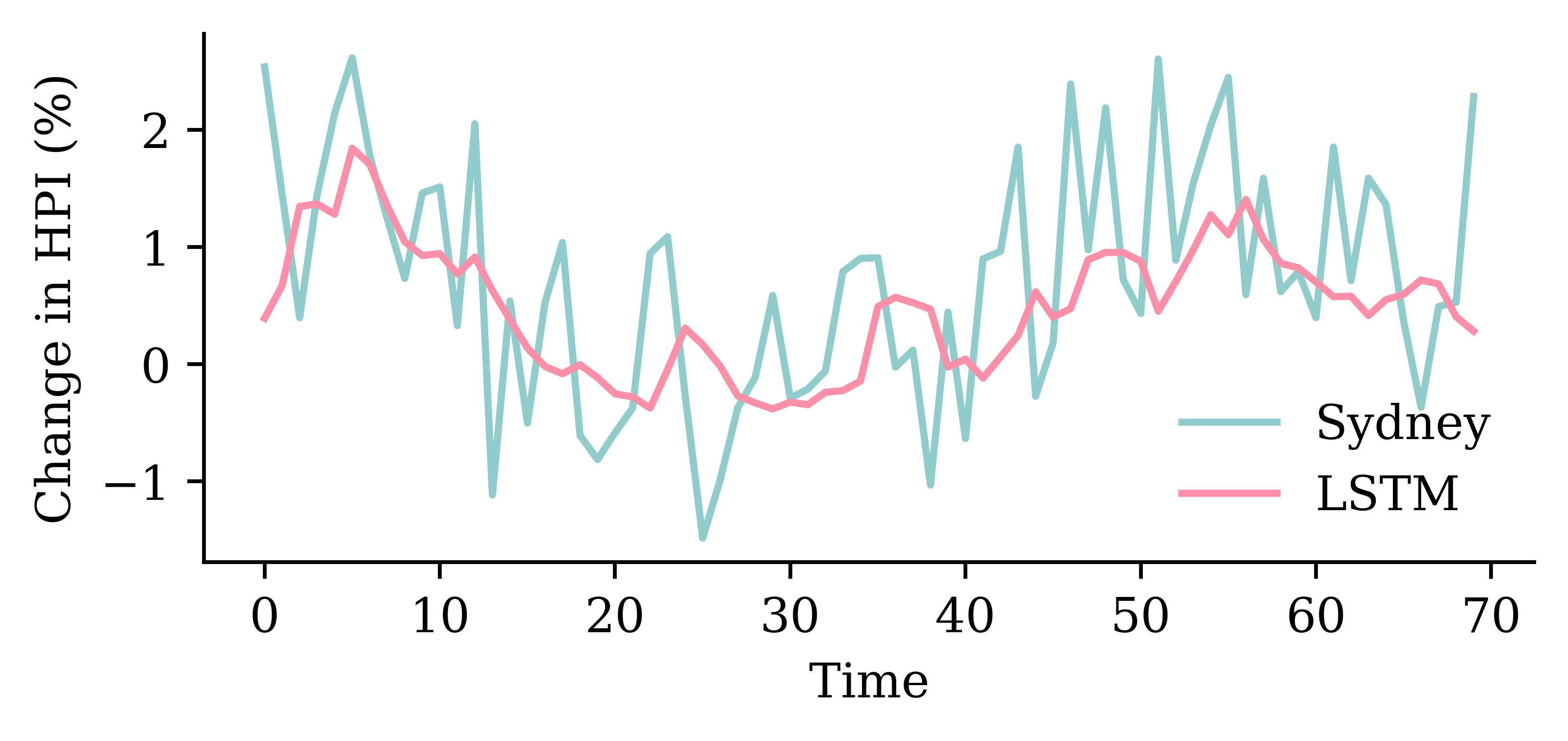
model_lstm.evaluate(X_val, y_val, verbose=0)
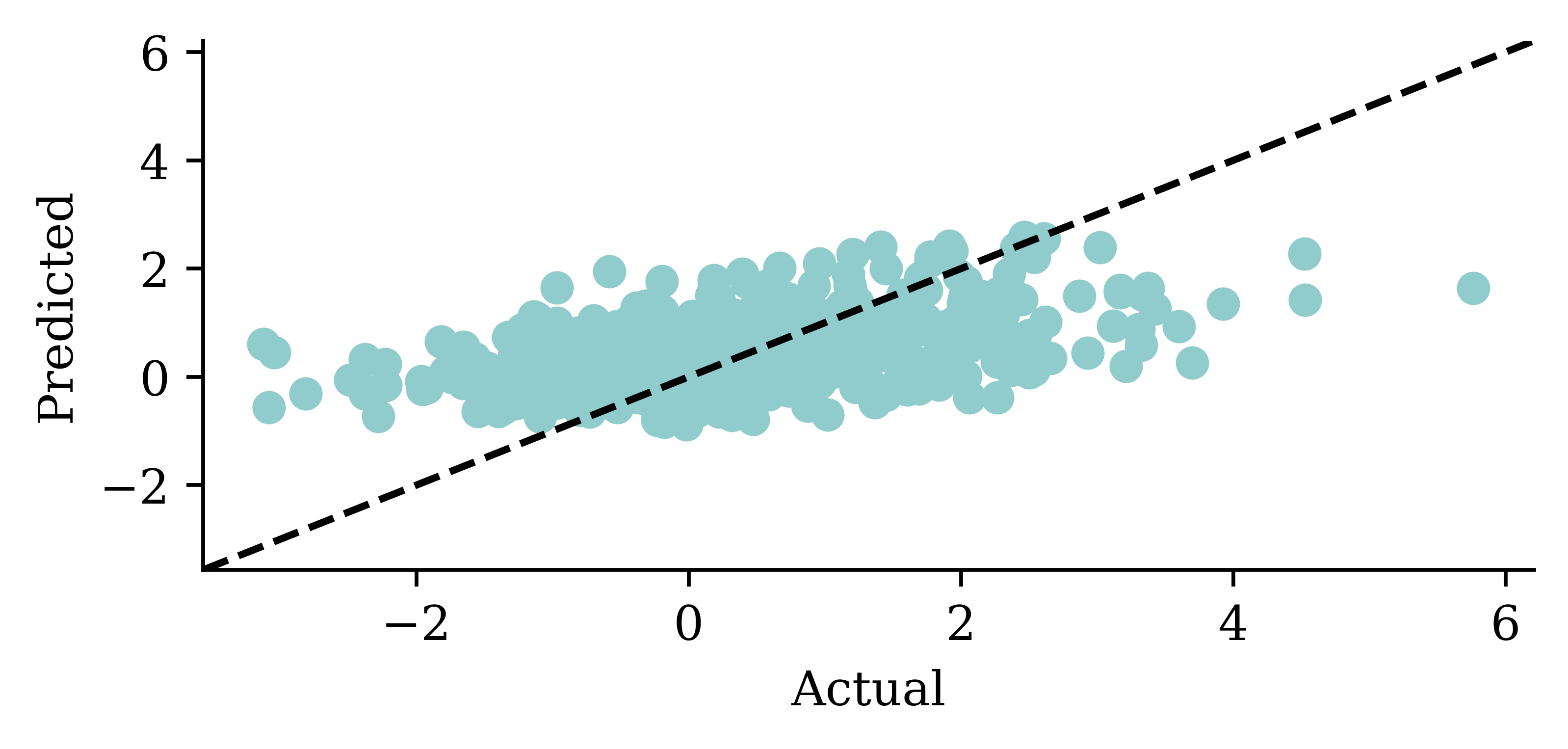
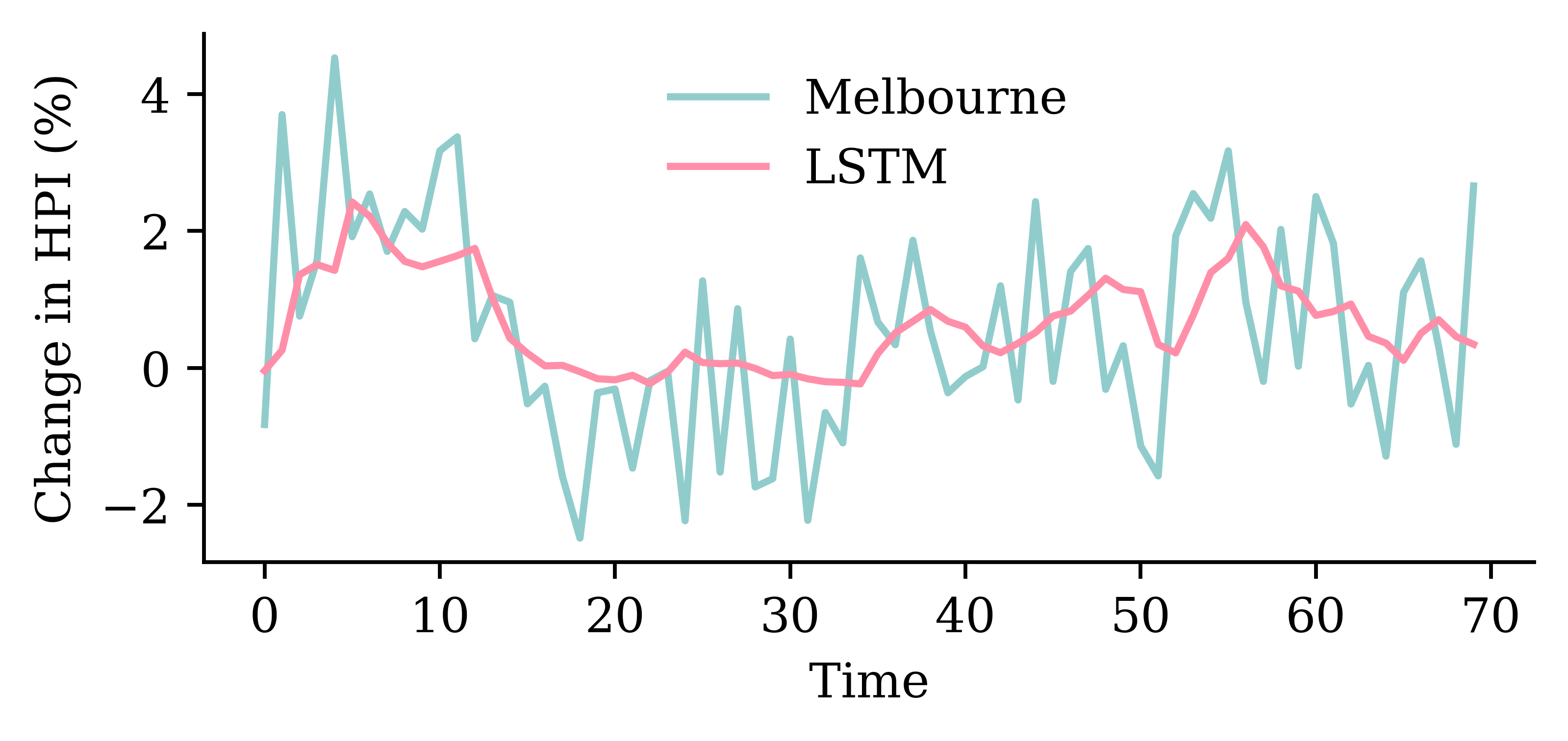
0.8229678273200989
Code
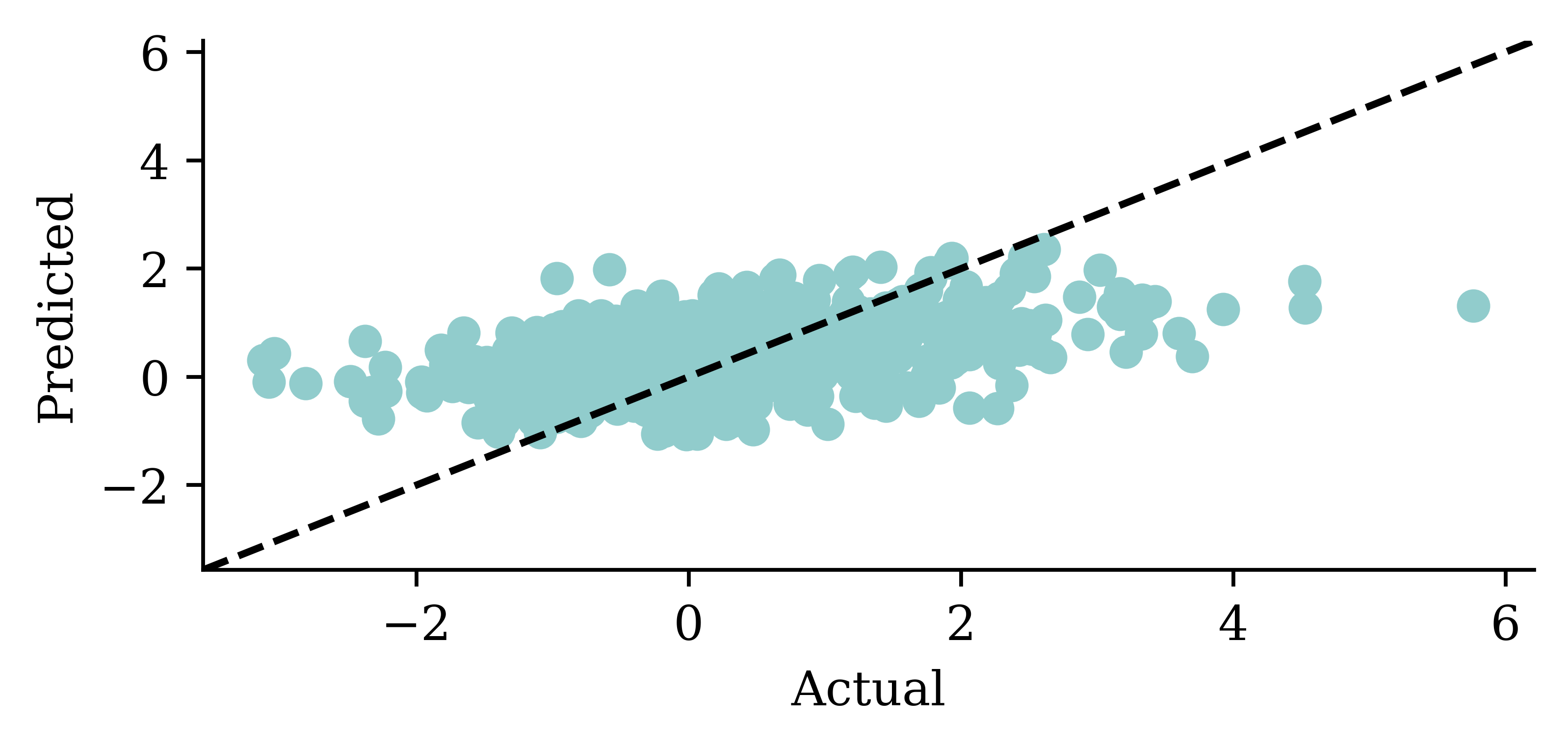
y_pred = model_lstm.predict(X_val, verbose=0)plt.plot(y_val, label="Sydney")plt.plot(y_pred, label="LSTM")plt.xlabel("Time")plt.ylabel("Change in HPI (%)")plt.legend(frameon=False);
Epoch 59: early stopping
Restoring model weights from the end of the best epoch: 9.
CPU times: user 1.55 s, sys: 58.7 ms, total: 1.61 s
Wall time: 1.57 s
Assess the fits
model_gru.evaluate(X_val, y_val, verbose=0)
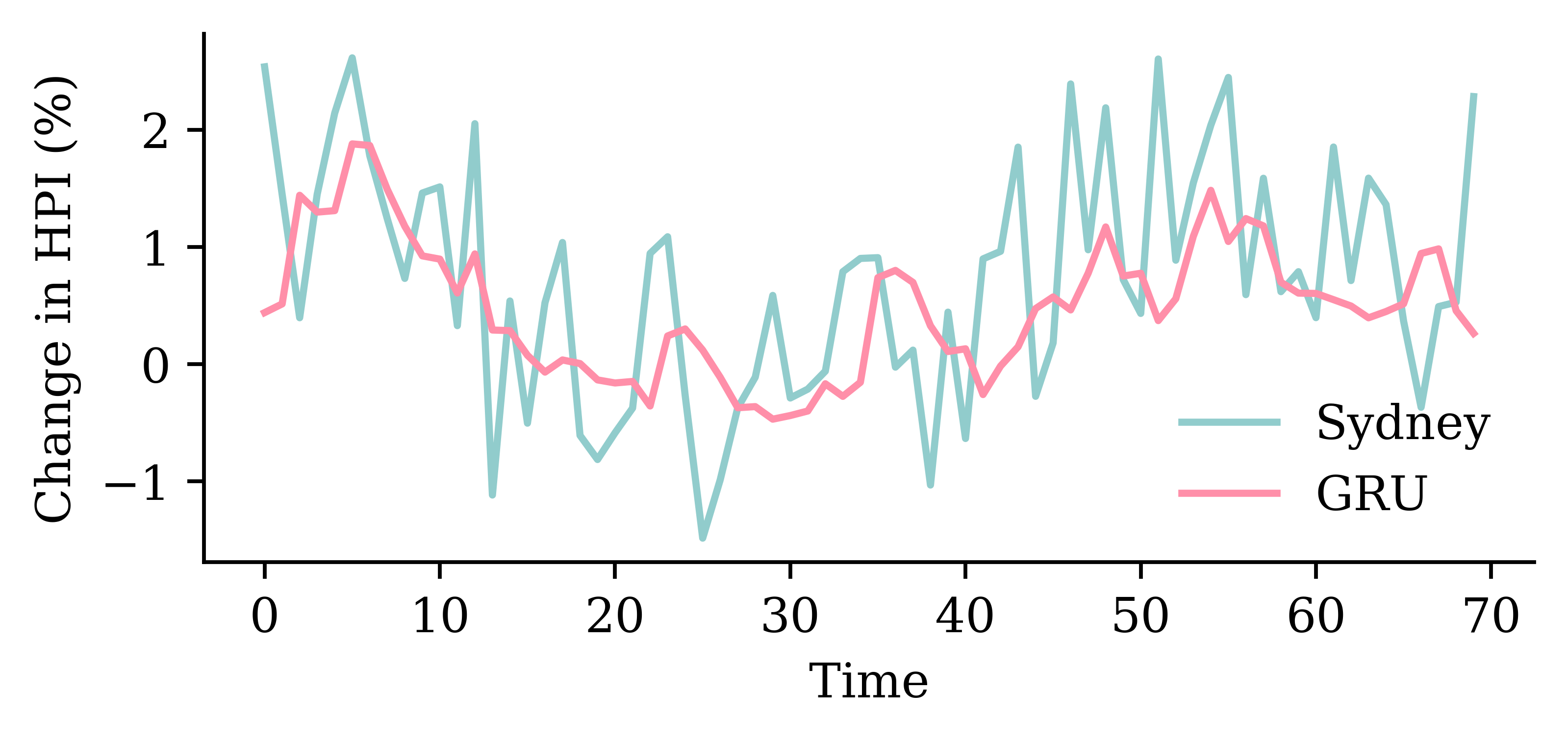
0.813169002532959
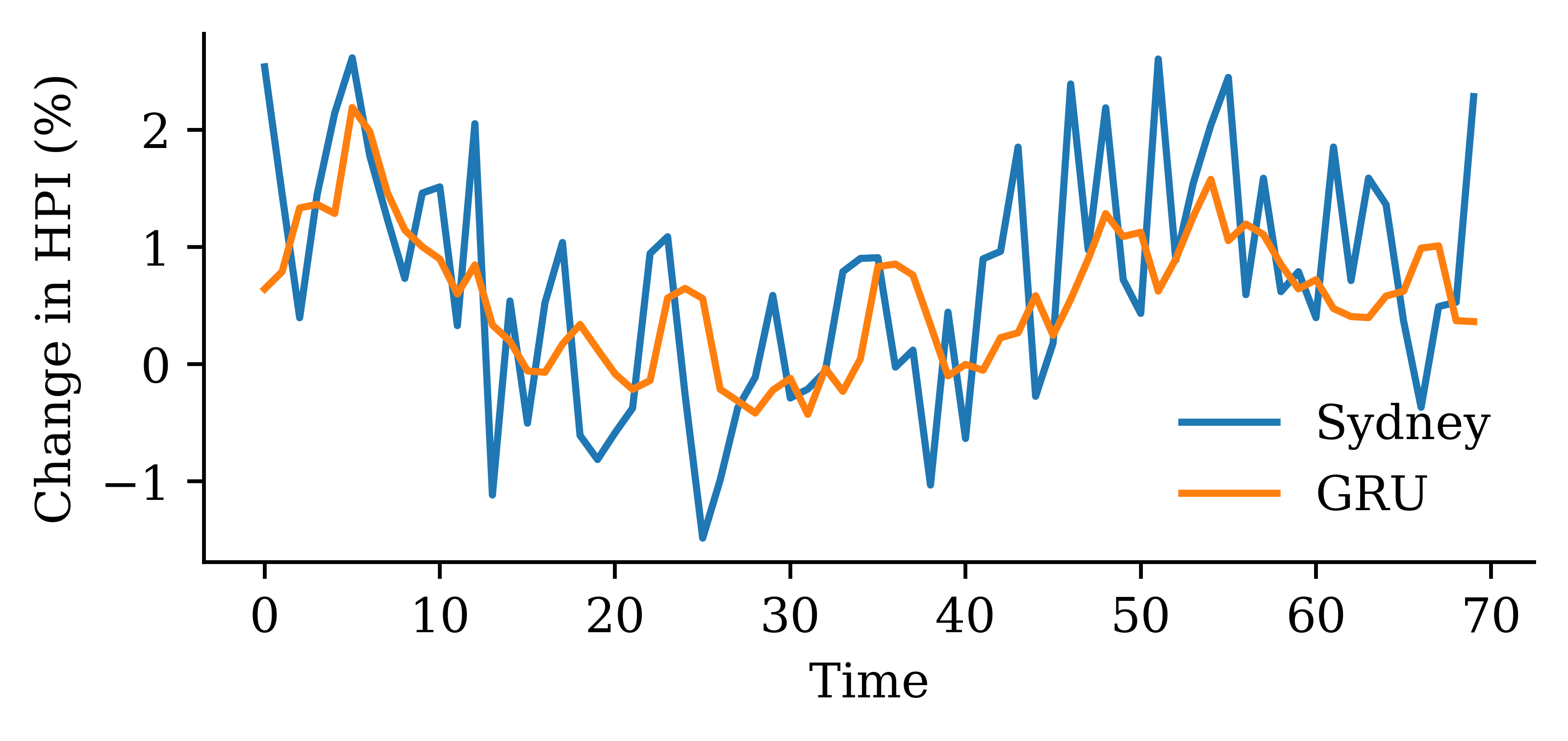
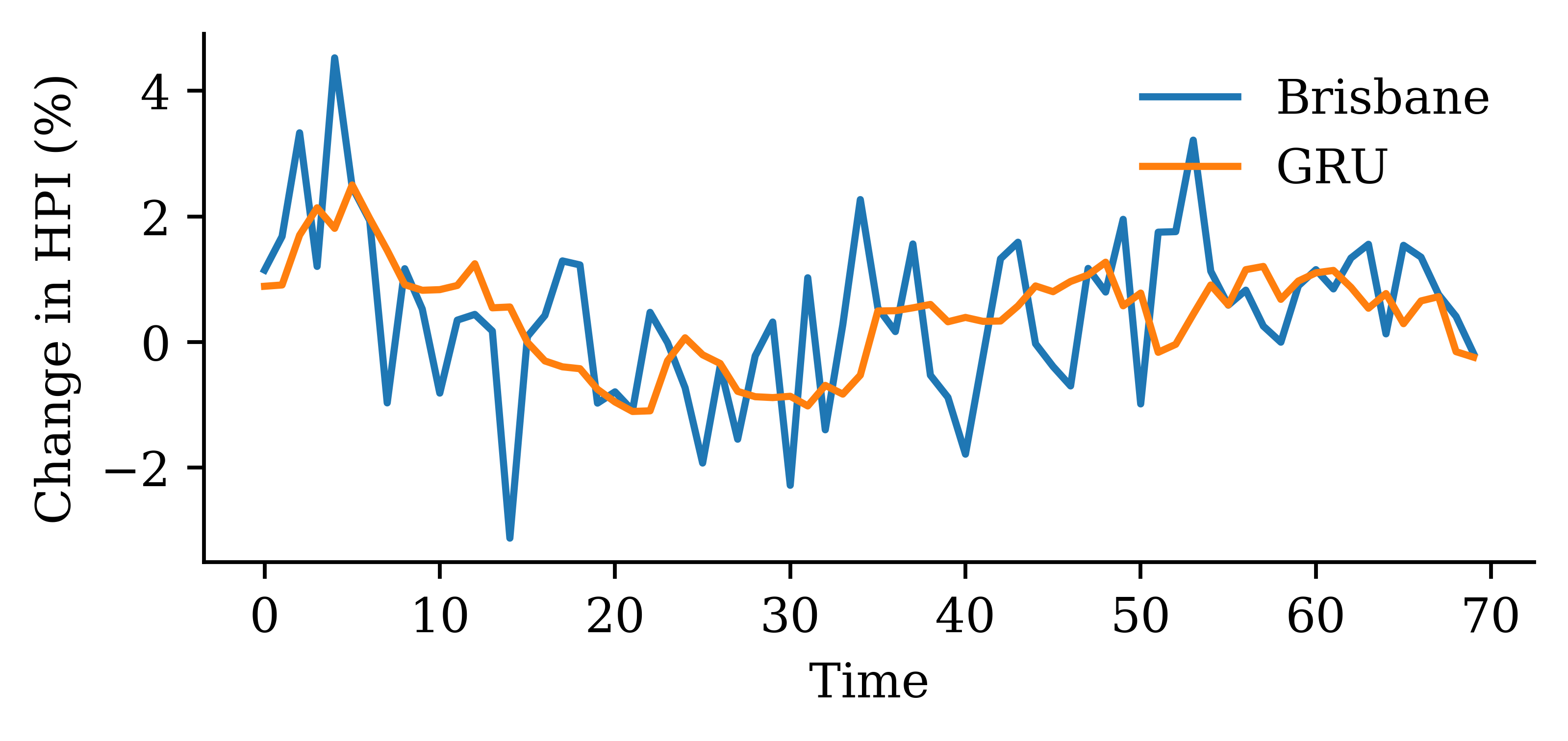
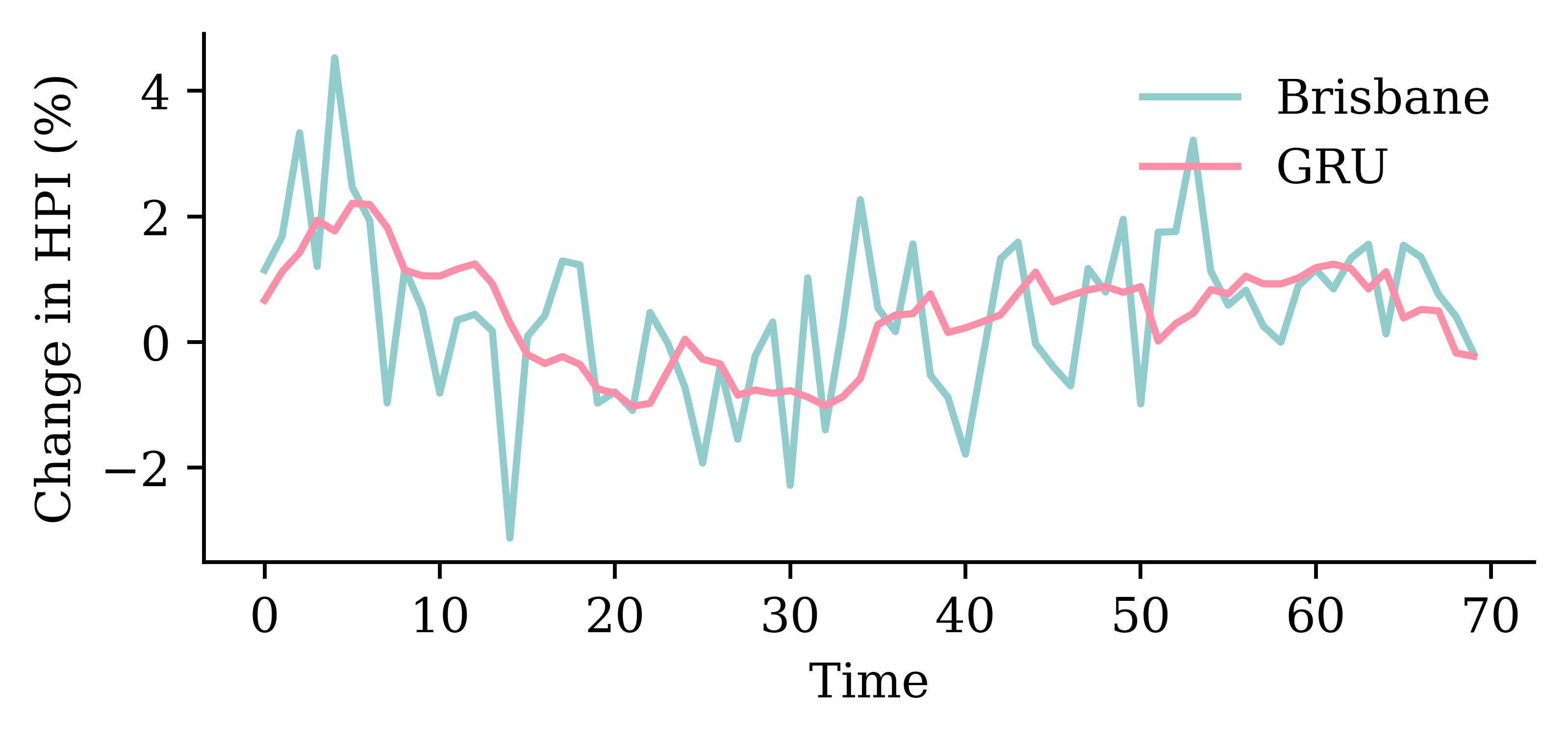
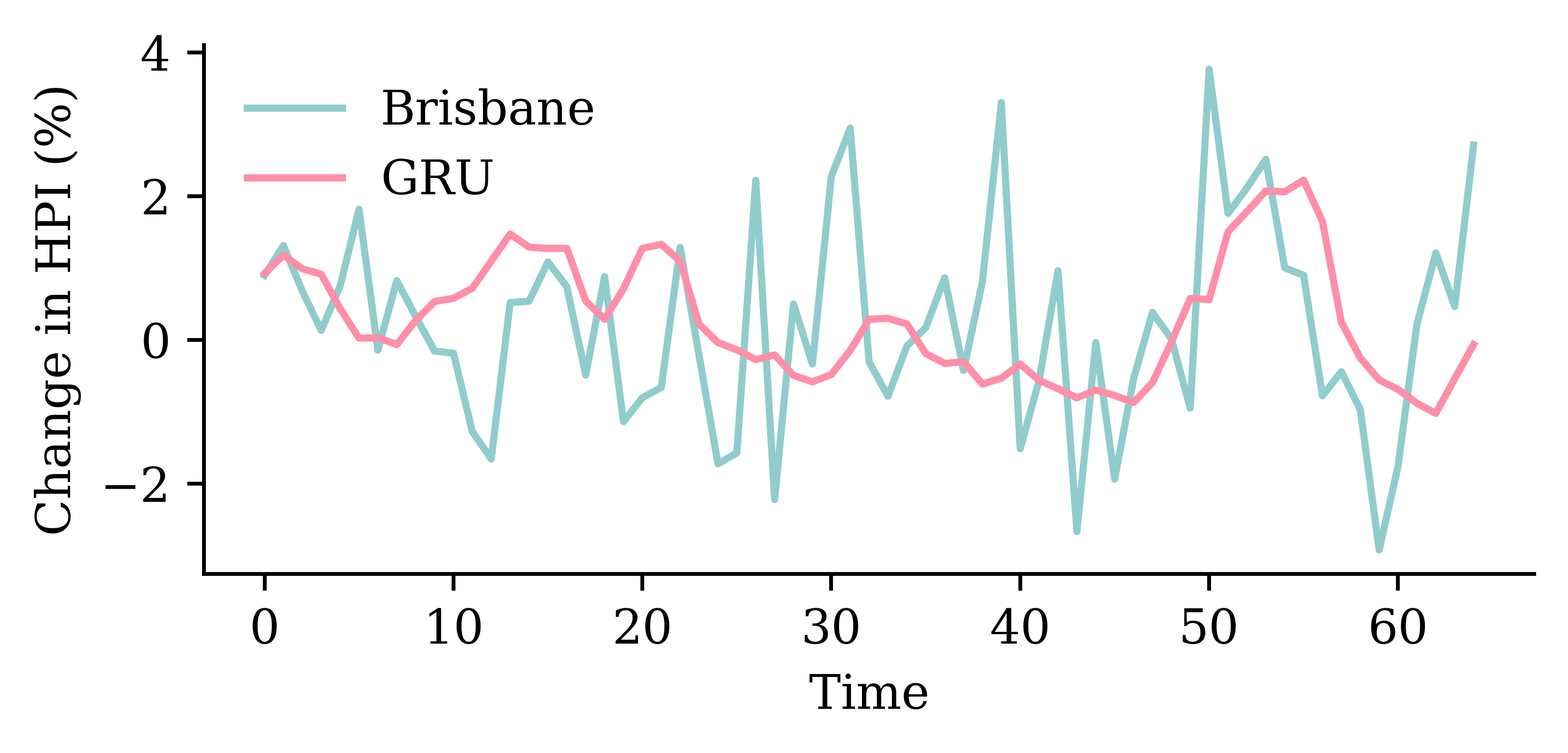
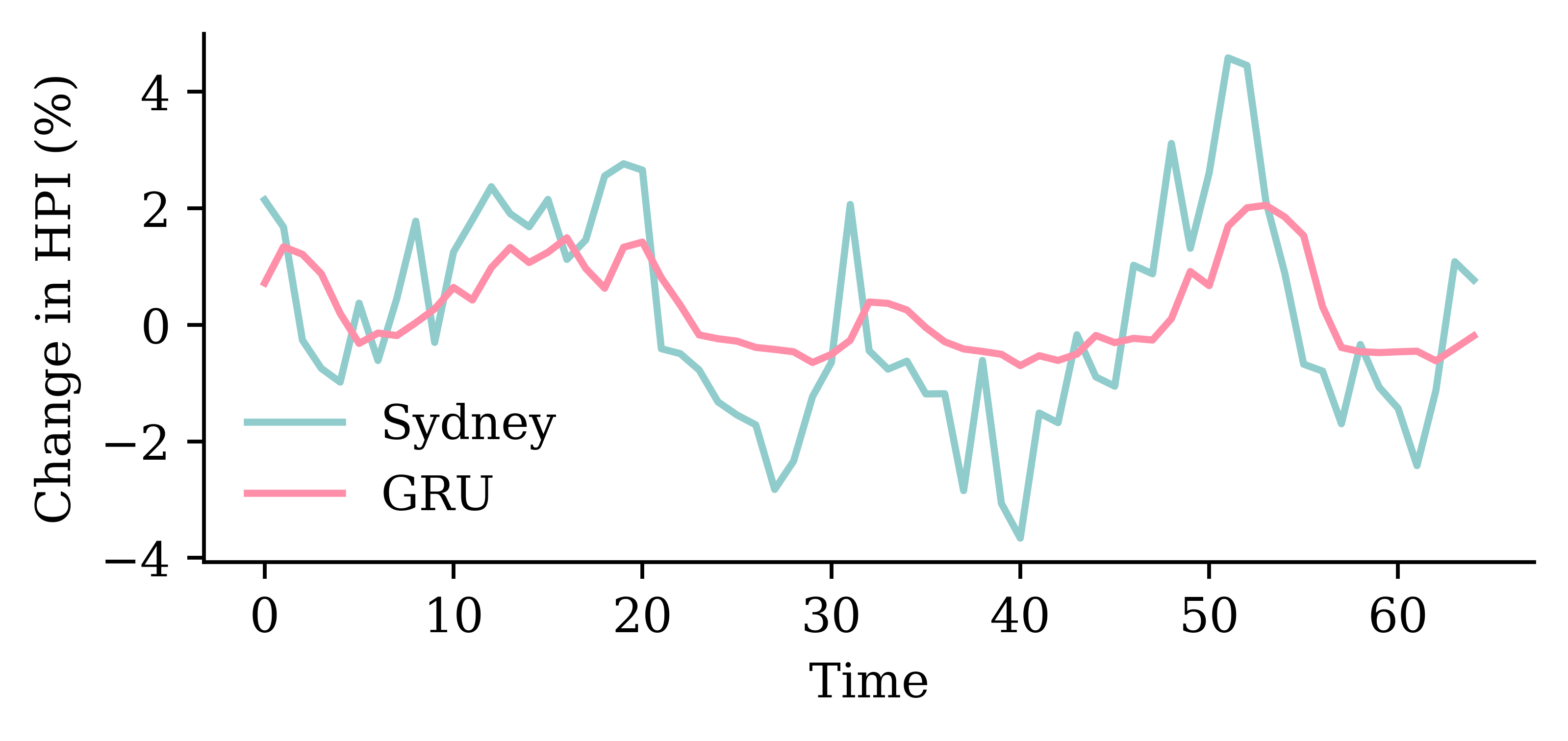
Code
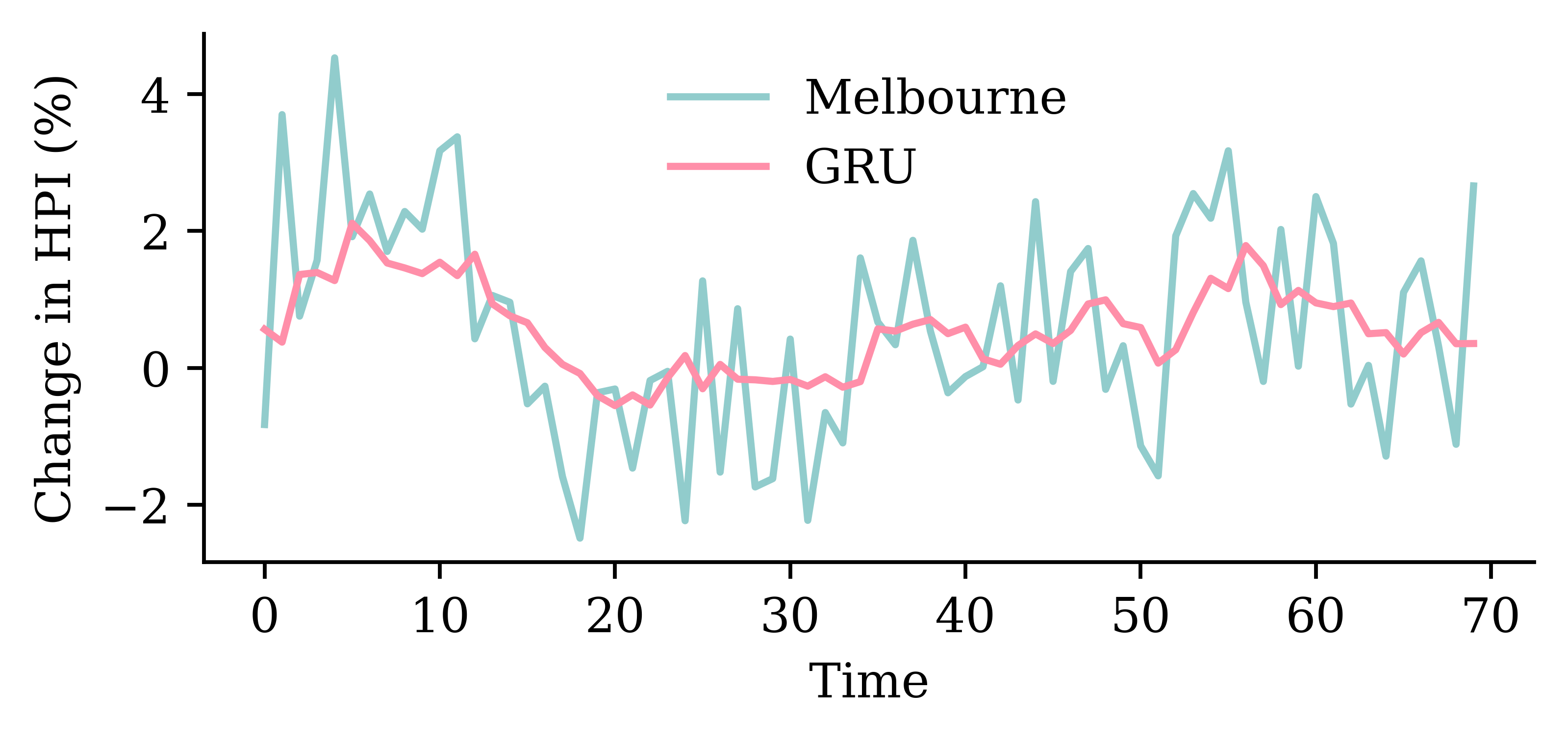
y_pred = model_gru.predict(X_val, verbose=0)plt.plot(y_val, label="Sydney")plt.plot(y_pred, label="GRU")plt.xlabel("Time")plt.ylabel("Change in HPI (%)")plt.legend(frameon=False);
Epoch 57: early stopping
Restoring model weights from the end of the best epoch: 7.
CPU times: user 2.56 s, sys: 105 ms, total: 2.66 s
Wall time: 2.6 s
Assess the fits
model_two_grus.evaluate(X_val, y_val, verbose=0)
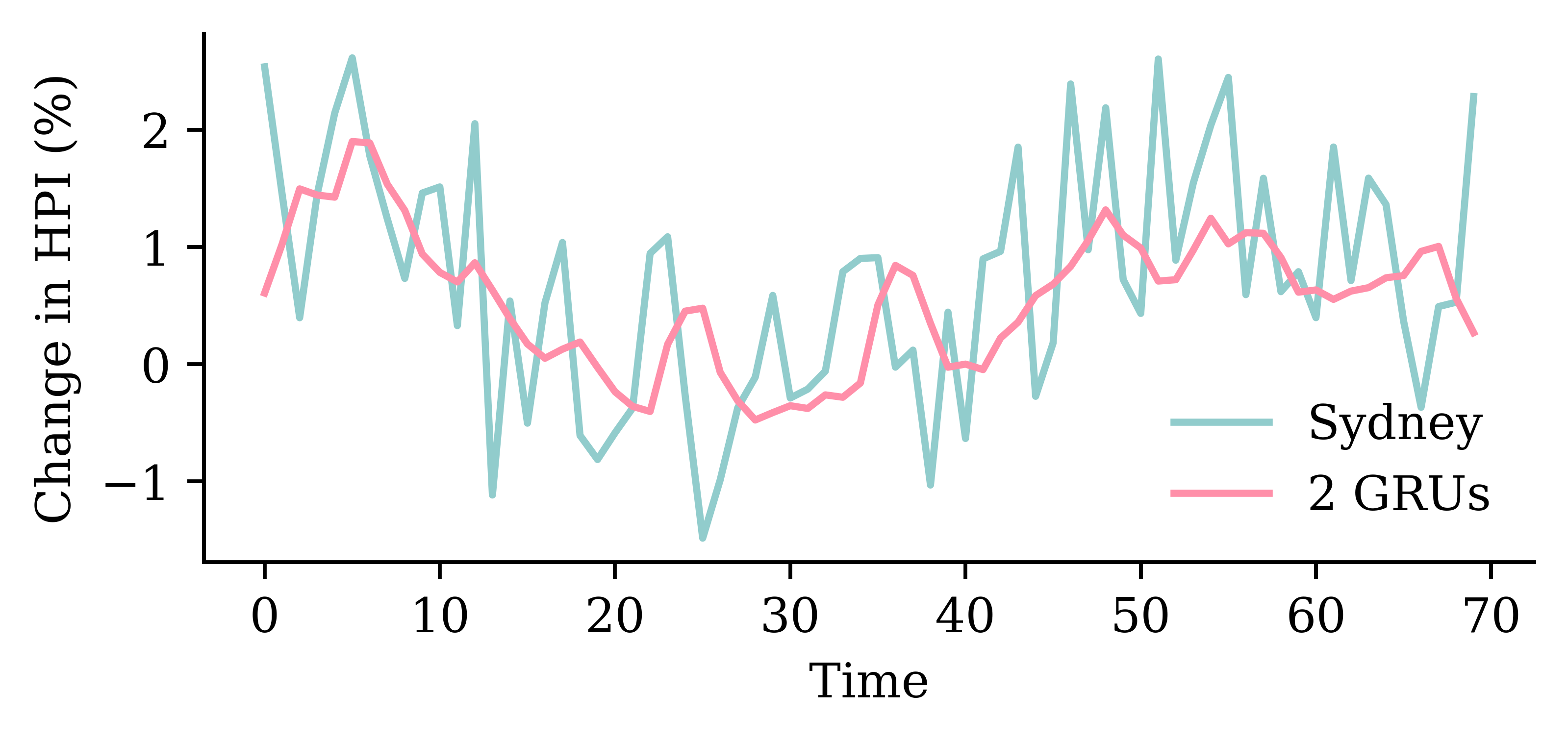
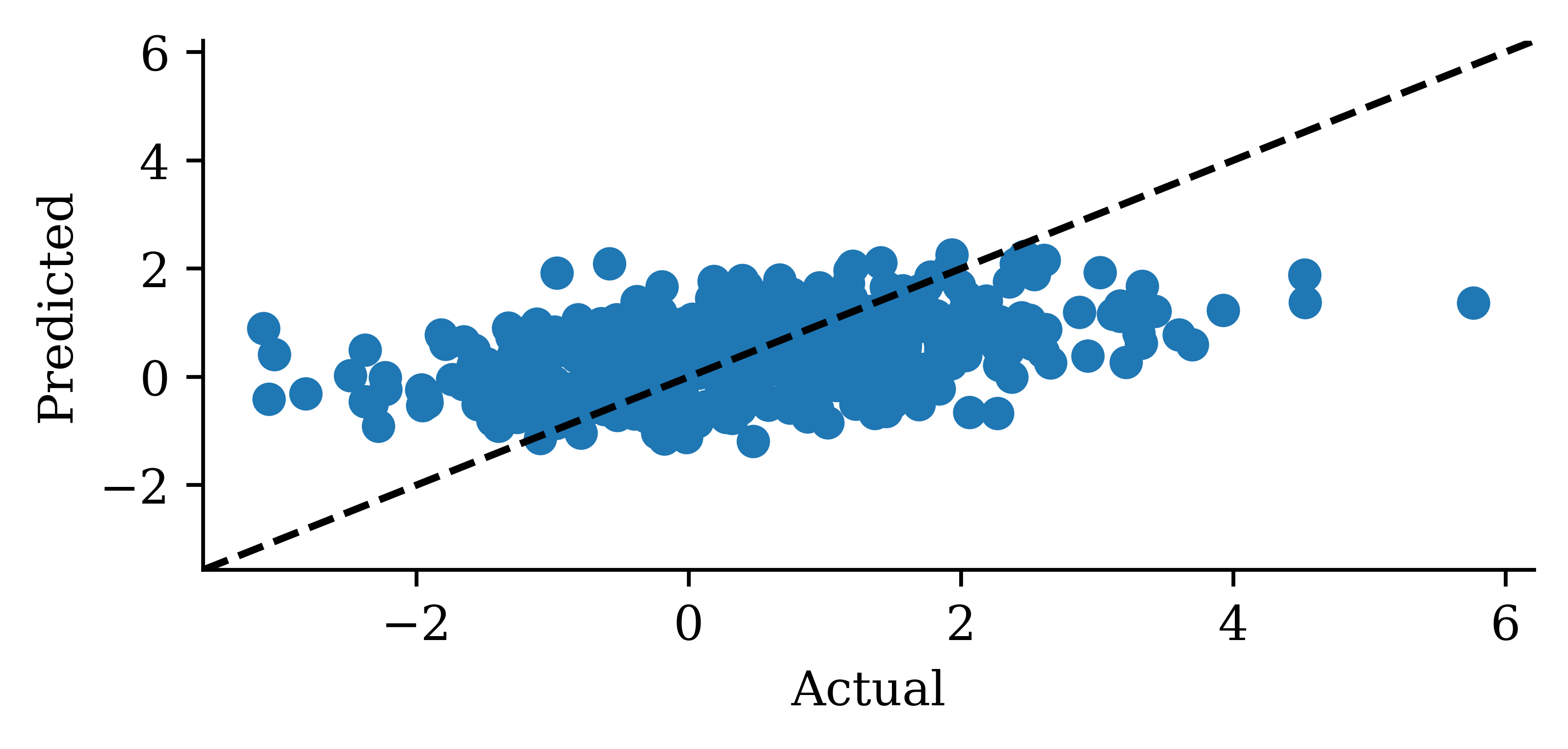
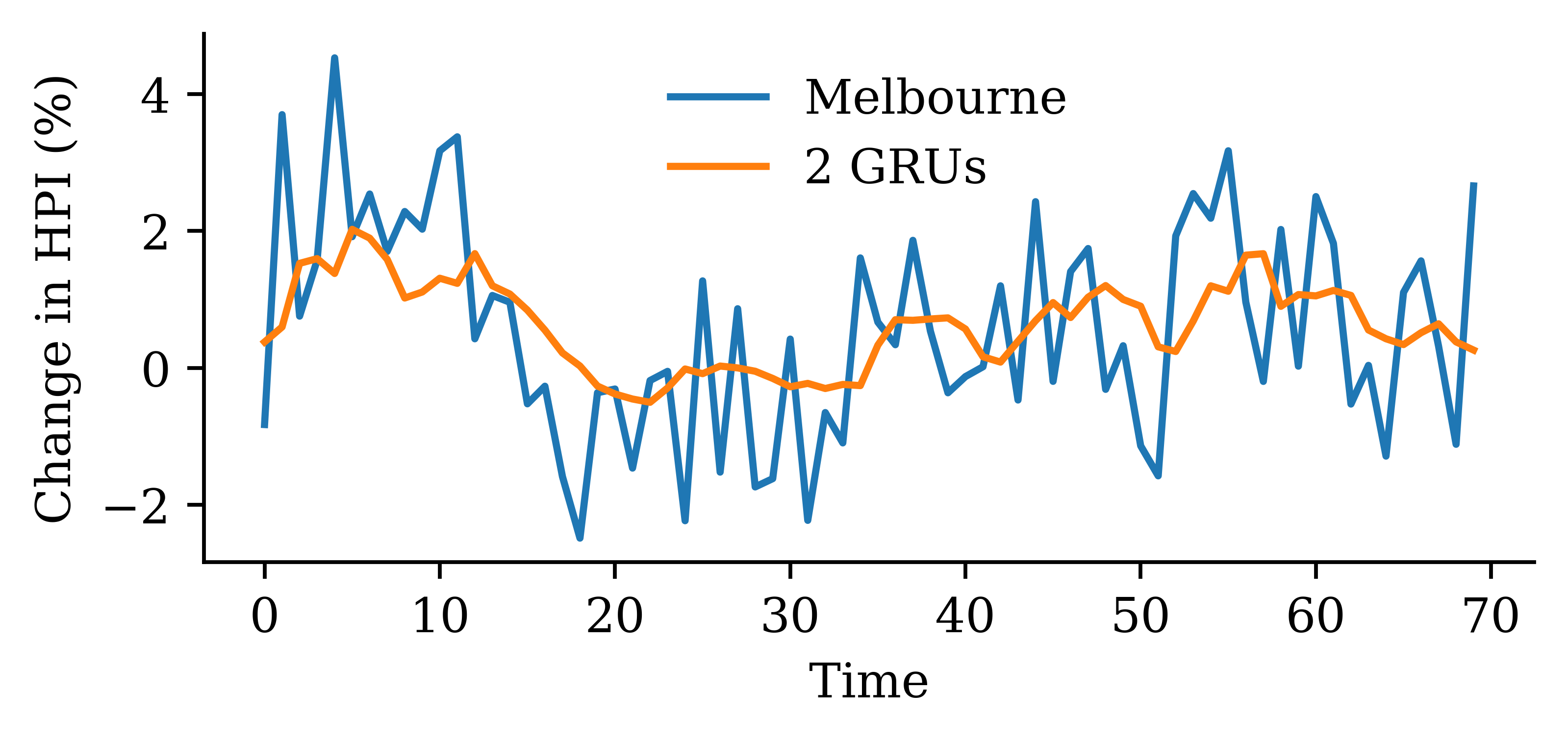
0.7832801342010498
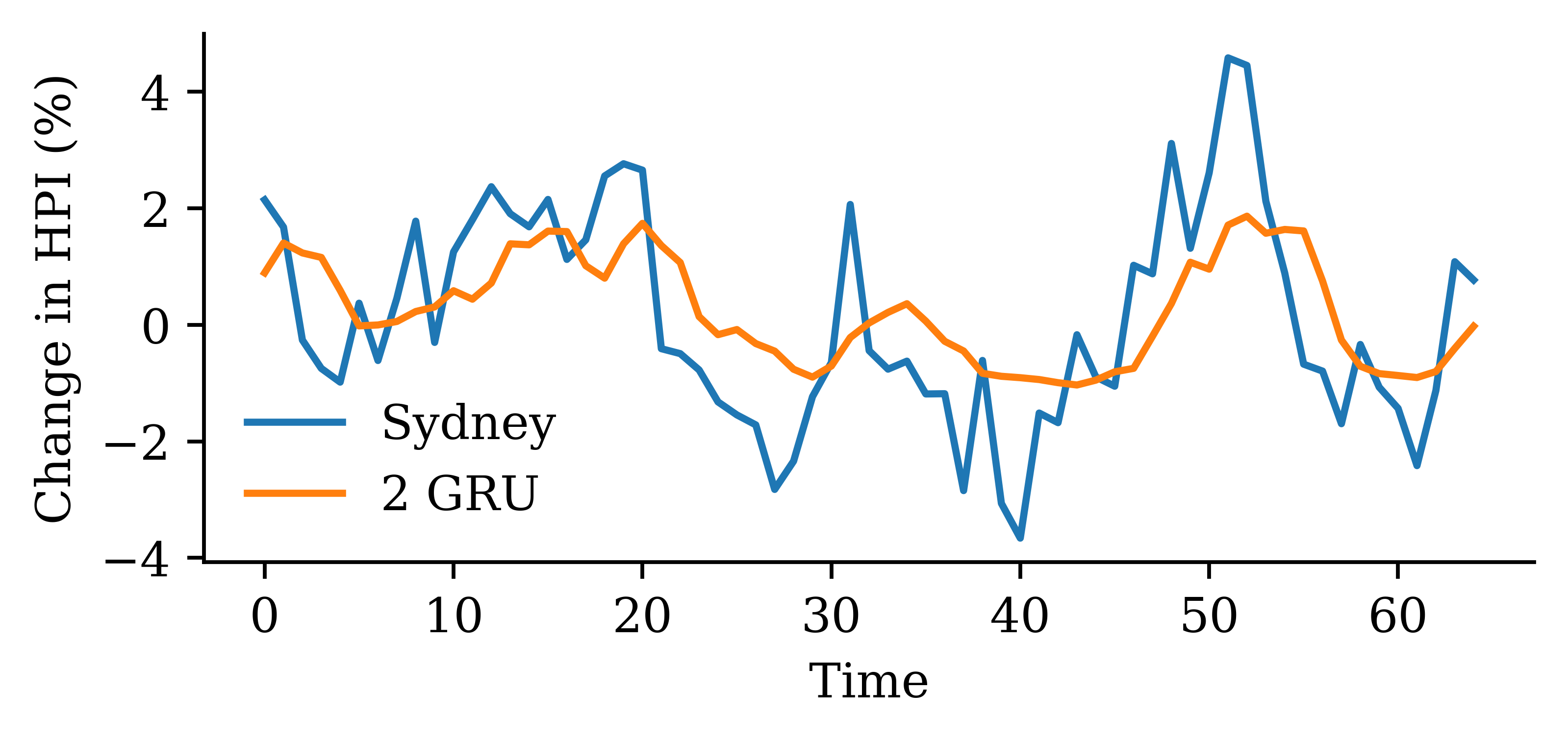
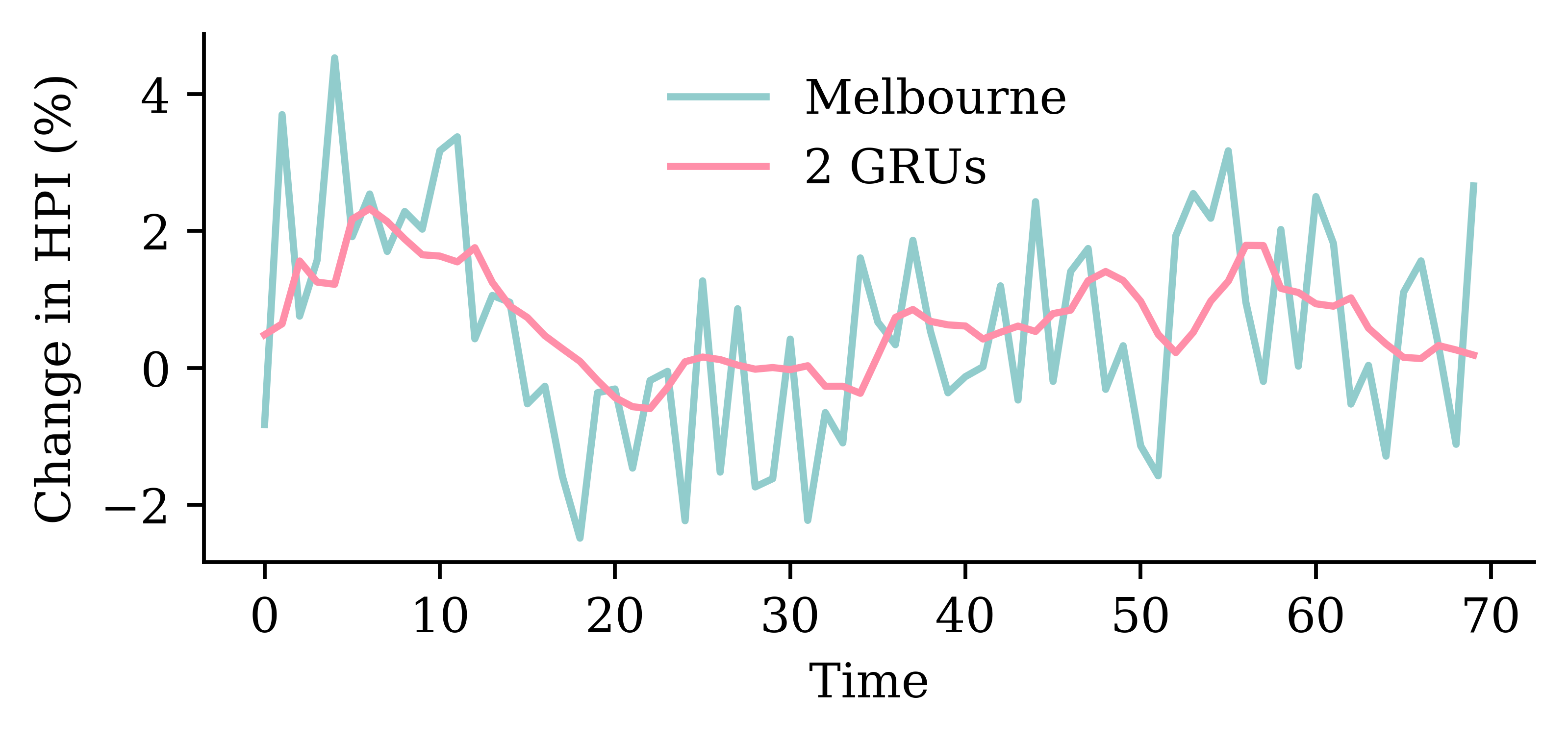
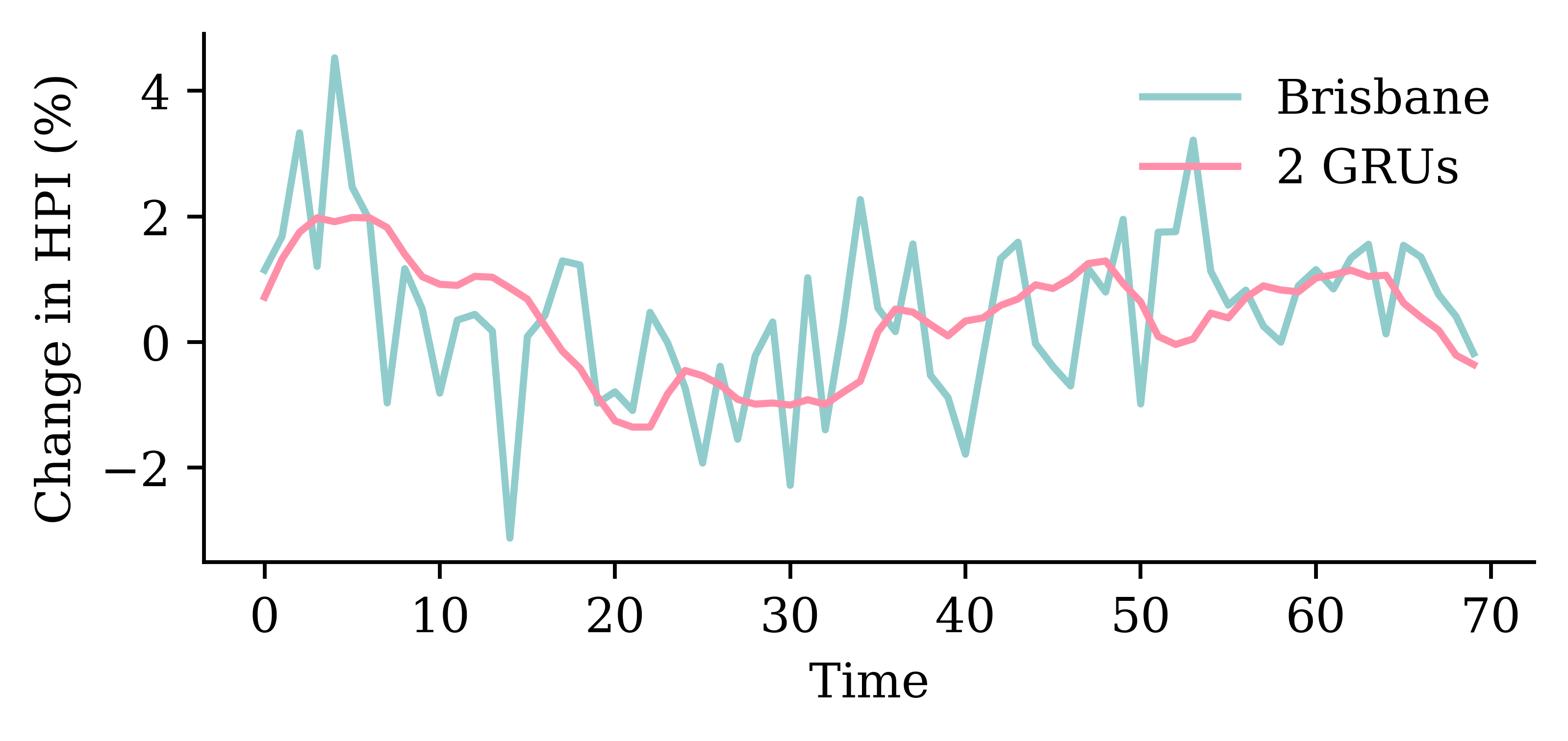
Code
y_pred = model_two_grus.predict(X_val, verbose=0)plt.plot(y_val, label="Sydney")plt.plot(y_pred, label="2 GRUs")plt.xlabel("Time")plt.ylabel("Change in HPI (%)")plt.legend(frameon=False);
This model has 3317 parameters.
Epoch 70: early stopping
Restoring model weights from the end of the best epoch: 20.
CPU times: user 751 ms, sys: 51.8 ms, total: 803 ms
Wall time: 771 ms
This model has 3257 parameters.
Epoch 69: early stopping
Restoring model weights from the end of the best epoch: 19.
CPU times: user 1.3 s, sys: 57 ms, total: 1.36 s
Wall time: 1.32 s
Epoch 76: early stopping
Restoring model weights from the end of the best epoch: 26.
CPU times: user 1.77 s, sys: 75.7 ms, total: 1.84 s
Wall time: 1.8 s
Epoch 69: early stopping
Restoring model weights from the end of the best epoch: 19.
CPU times: user 1.72 s, sys: 63.5 ms, total: 1.79 s
Wall time: 1.75 s
Epoch 74: early stopping
Restoring model weights from the end of the best epoch: 24.
CPU times: user 3.15 s, sys: 123 ms, total: 3.27 s
Wall time: 3.2 s