import numpy as npclasses, counts = np.unique(y_train.values.ravel(), return_counts=True)print("Classes:", classes)print("Counts:", counts)
Classes: [0 1]
Counts: [2909 157]
This shows the distribution of the binary stroke target (0 = no stroke, 1 = stroke).
Setup a binary classification model
def create_model(seed=42): random.seed(seed) model = Sequential() model.add(Input(X_train.shape[1:])) model.add(Dense(32, "leaky_relu")) model.add(Dense(16, "leaky_relu")) model.add(Dense(1, "sigmoid"))return model
Since this is a binary classification problem, we use the sigmoid activation function. The output can be any value between 0 and 1, being the implied probability of a positive outcome. The output is strictly one neuron.
<keras.src.callbacks.history.History at 0x124b32e90>
While BCE is difficult to interpret, we can ask the model to output other metrics (e.g. accuracy) to monitor during training. While we want the BCE to be minimised, we want accuracy to be as high as possible.
Here we include accuracy as a metric to monitor during training.
CPU times: user 7.48 s, sys: 262 ms, total: 7.75 s
Wall time: 7.55 s
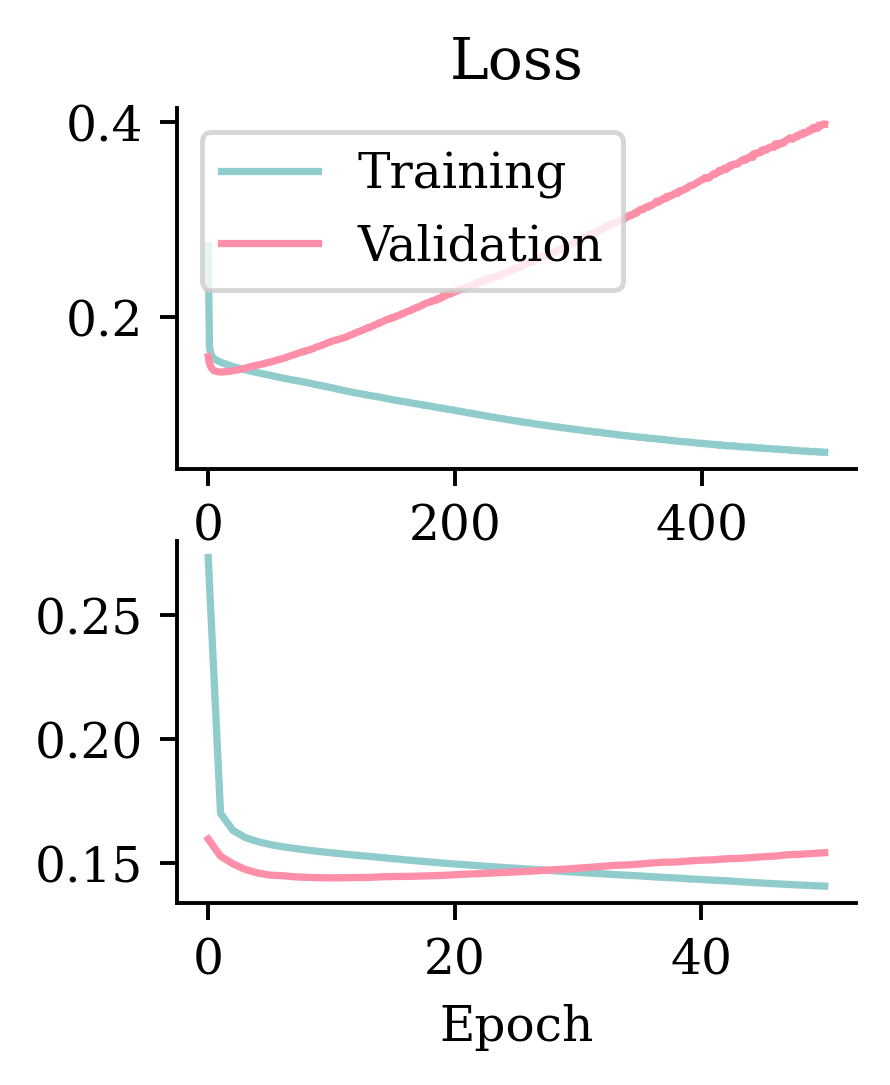
Stopped after 51 epochs.
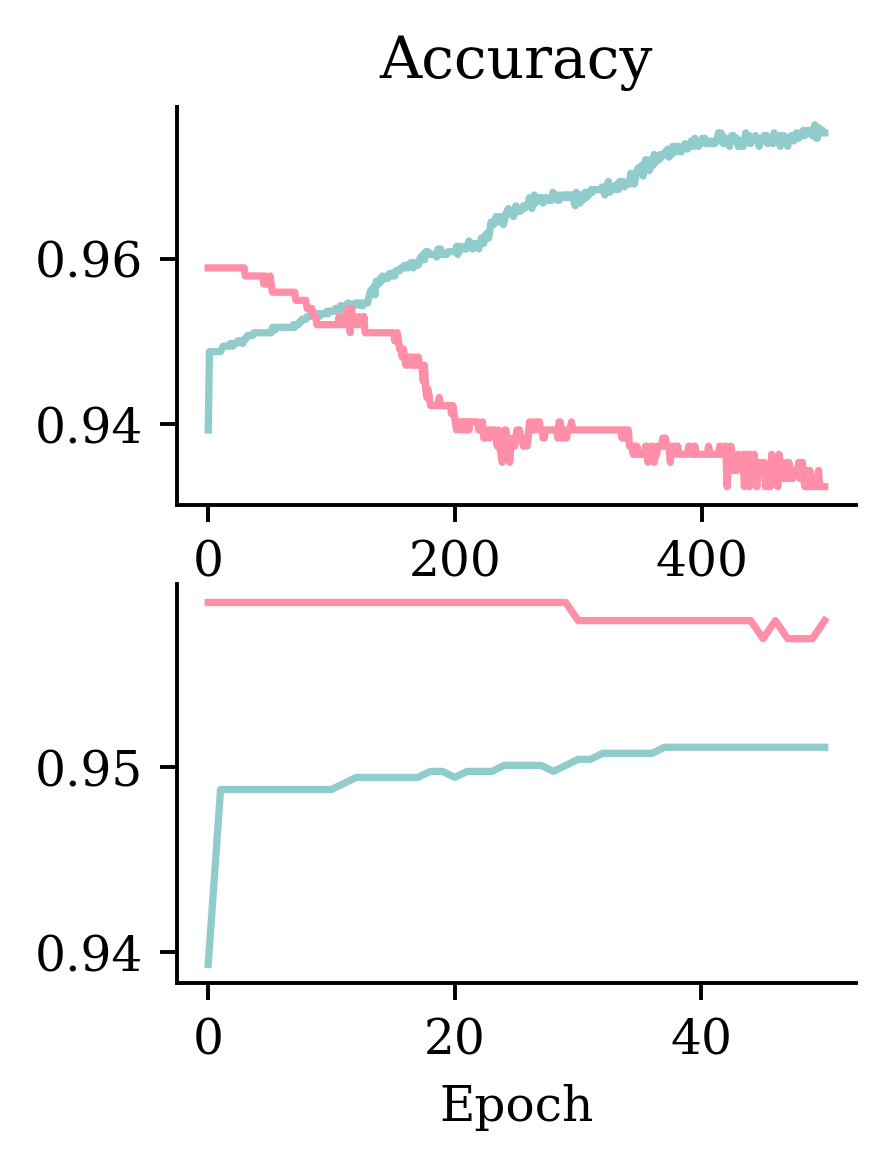
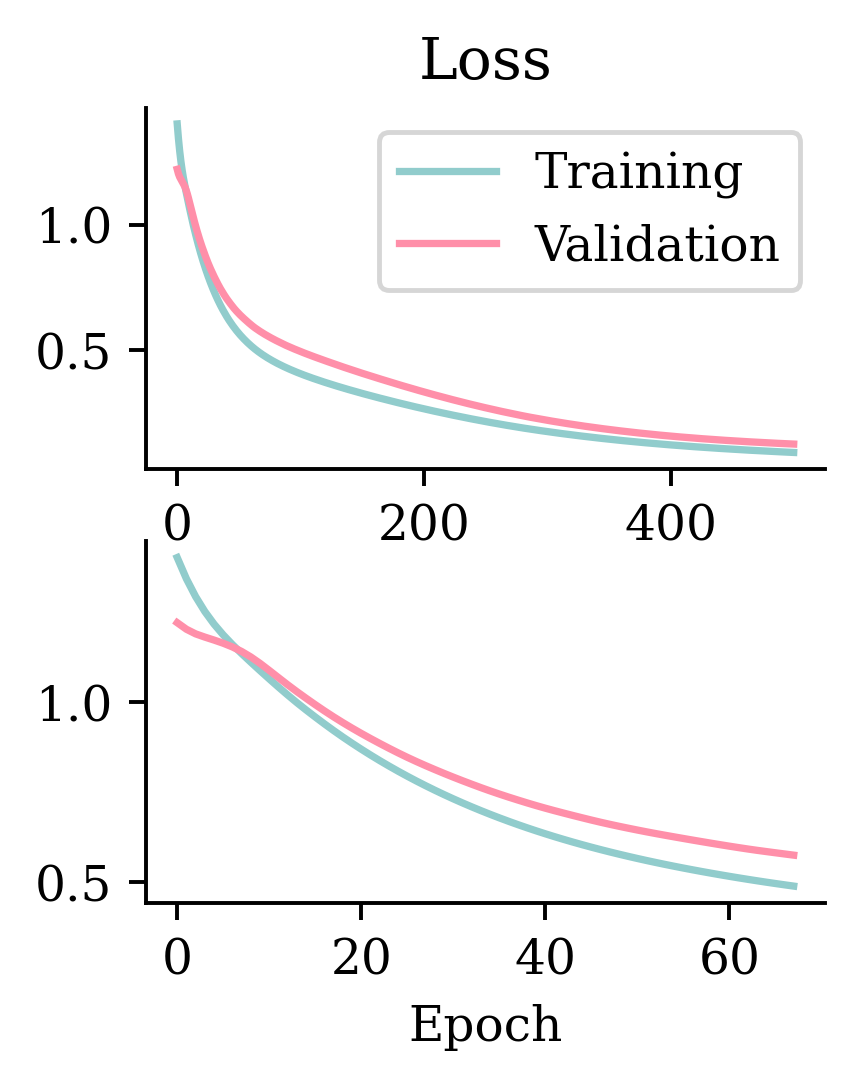
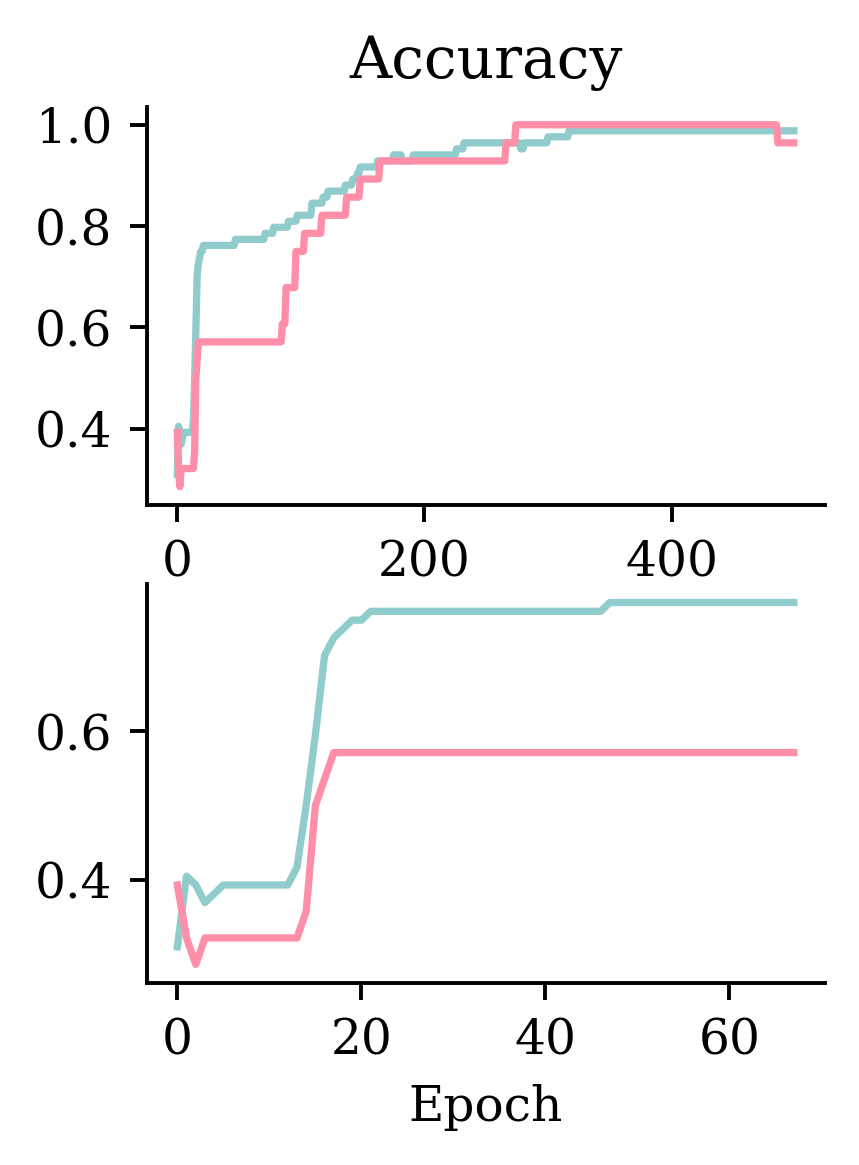
Early stopping is used to prevent overfitting by monitoring validation accuracy.
In this case, the early stopping is not based on minimising the validation BCE, but on maximising the validation accuracy. If the model doesn’t see an increase in accuracy after 50 epochs, it stops and goes back to the model 50 epochs earlier where accuracy was maximised.
Left hand side plots show how loss behaved without and with early stopping. Right hand side plots show how accuracy performed without and with early stopping.
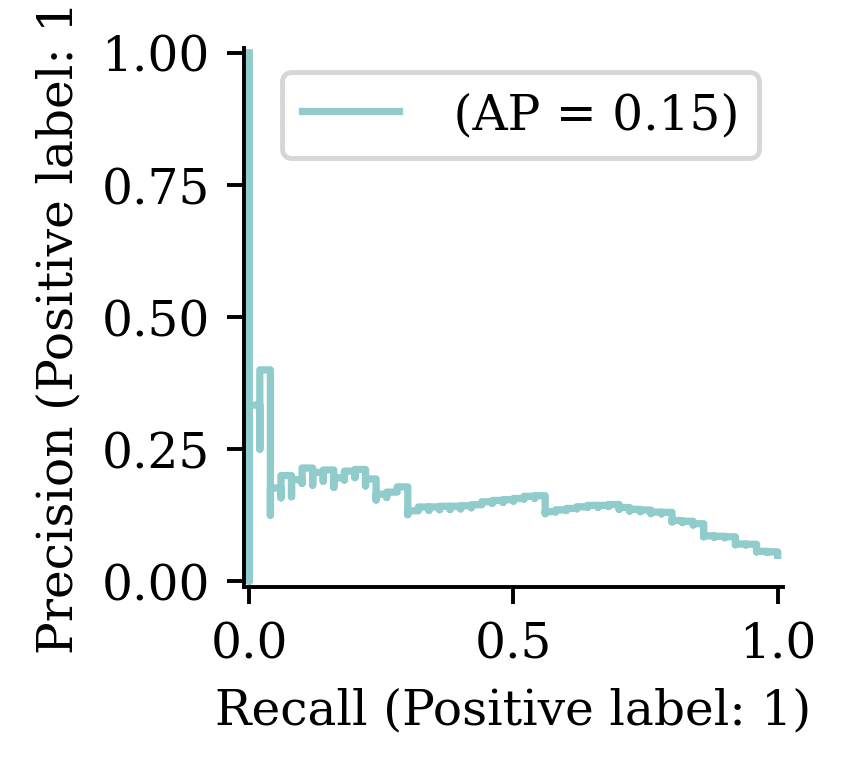
Creates an instance pr_auc to store the AUC (Area Under Curve) metric for the PR (Precision-Recall) curve
3
Compiles the model with an appropriate loss function, optimizer and relevant metrics. Since the above problem is a binary classification, we would optimize the binary_crossentropy, chose to monitor both accuracy and AUC and pr_auc.
Epoch 81: early stopping
Restoring model weights from the end of the best epoch: 31.
Tracking AUC and pr_auc on top of the accuracy is important, particularly in the cases where there is a class imbalance. Suppose a data has 95% True class and only 5% False class, then, even a random classifier that predicts True 95% of the time will have a high accuracy. To avoid such issues, it is advisable to monitor both accuracy and AUC.
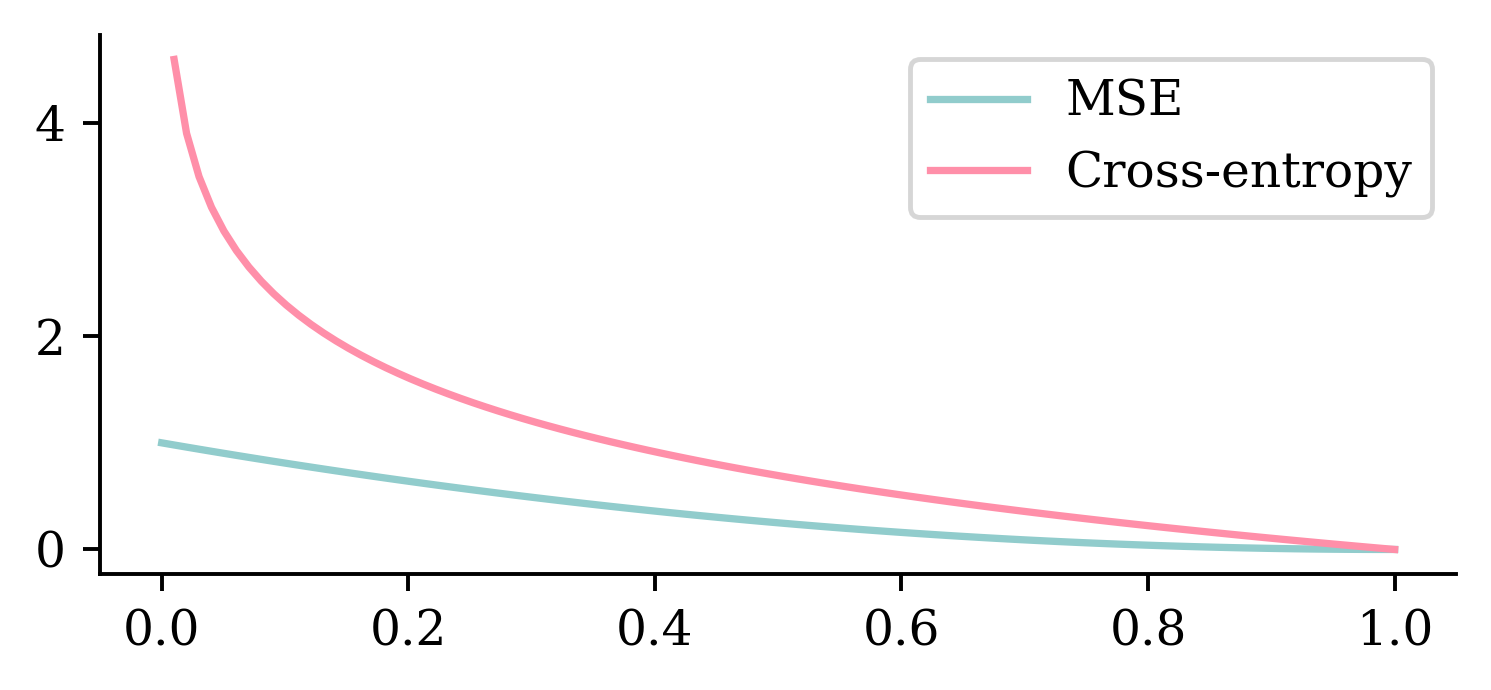
p = np.linspace(0, 1, 100)plt.plot(p, (1- p) **2)plt.plot(p, -np.log(p))plt.legend(["MSE", "Cross-entropy"]);
/var/folders/sc/b5vy9t2d2_scccwgx6kbk8w80000gp/T/ipykernel_77711/1829931169.py:3: RuntimeWarning:
divide by zero encountered in log
The above plot shows how MSE and cross-entropy penalize wrong predictions. The x-axis indicates the severity of misclassification. Suppose the neural network predicted that there is near-zero probability of an observation being in class “1” when the actual class is “1”. This represents a strong misclassification. The above graph shows how MSE does not impose heavy penalties for the misclassifications near zero. It displays a linear increment across the severity of misclassification. On the other hand, cross-entropy penalises bad predictions strongly. Also, the misclassification penalty grows exponentially. This makes cross entropy more suitable.
Overweight the minority class
Another way to treat class imbalance would be to assign a higher weight to the minority class during model fitting.
Fits the model by assigning a higher weight to the misclassification in the minor class. This above class weight assignment says that misclassifying an observation from class 1 will be penalized 10 times more than misclassifying an observation from class 0. The weights can be assigned in relation to the level of data imbalance.
Epoch 64: early stopping
Restoring model weights from the end of the best epoch: 14.
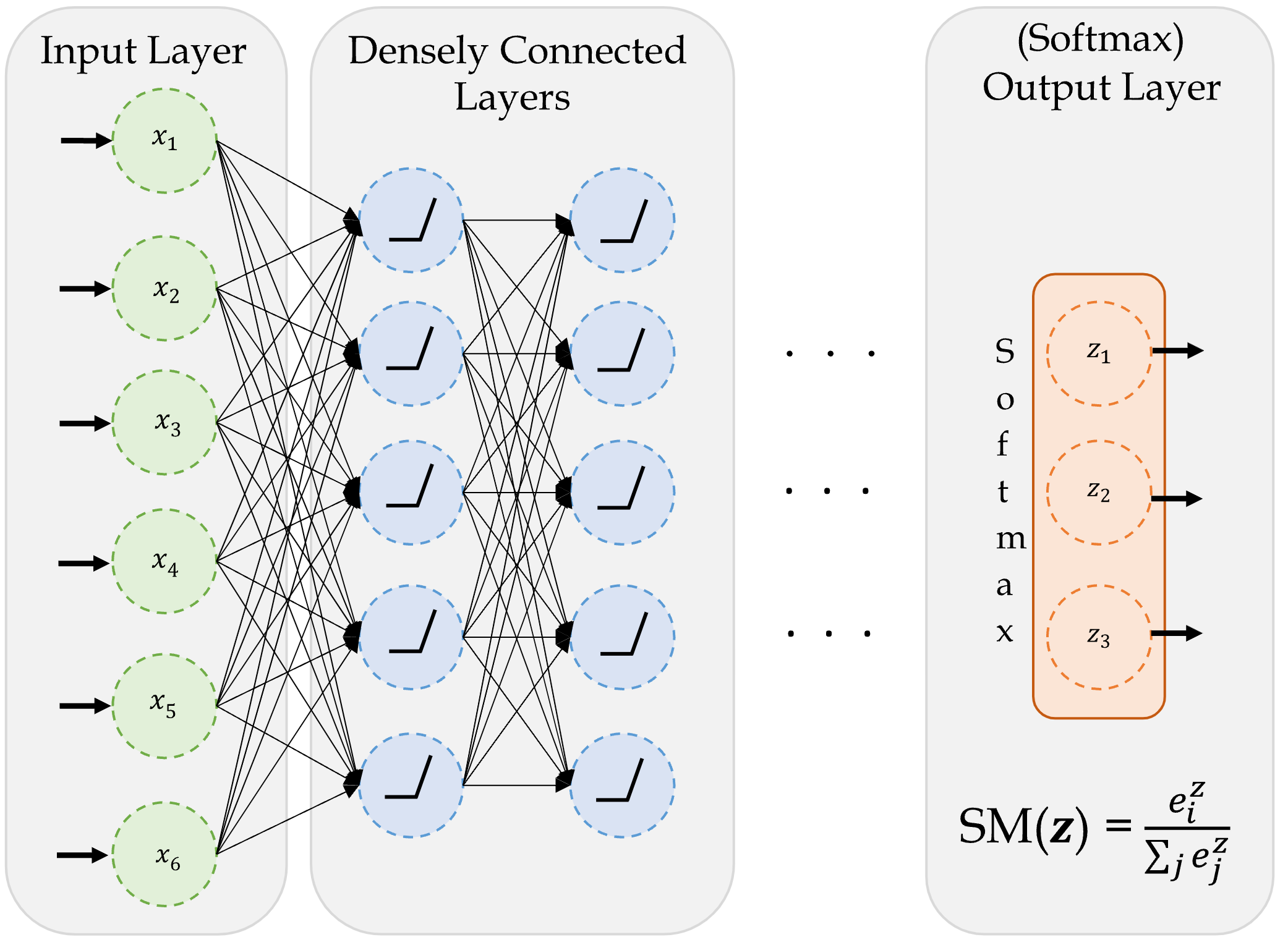
A basic network for classifying into three categories.
Since the task is a classification problem, we use softmax activation function. The softmax function takes in the input and returns a probability vector, which tells us about the probability of a data point belonging to a certain class.
Create a classifier model
NUM_FEATURES =len(features.columns)NUM_CATS =len(np.unique(target))print("Number of features:", NUM_FEATURES)print("Number of categories:", NUM_CATS)
Number of features: 4
Number of categories: 3
The output layer contains the same number of neurons as the number of categories in the target variable.
Since the problem at hand is a classification problem, we define the optimizer and loss function accordingly. Optimizer is adam and the loss function is sparse_categorical_crossentropy. If the response variable represents the category directly using an integer (i.e. if the response variable is not one-hot encoded), we must use sparse_categorical_crossentropy. If the response variable (y label) is already one-hot encoded we can use categorical_crossentropy.
Track accuracy as the model trains
model = build_model()model.compile("adam", "sparse_categorical_crossentropy", metrics=["accuracy"])model.fit(X_train, y_train, epochs=5, verbose=2);
We can also specify which loss metric to monitor in assessing the performance during the training. The metric that is usually used in classification tasks is accuracy, which tracks the fraction of all predictions which identified the class accurately. The metrics are not used for optimizing. They are only used to keep track of how well the model is performing during the optimization. By setting verbose=2, we are printing the progress during training, and we can see how the loss is reducing and accuracy is improving.
Use build_model to make a new empty neural network to train
2
Compiles the model with optimizer, loss function and metric
3
Defines the early stopping object as usual, with one slight change. The code is specified to activate the early stopping by monitoring the validation accuracy (val_accuracy), not the loss.
4
Fits the model
CPU times: user 422 ms, sys: 37.5 ms, total: 459 ms
Wall time: 435 ms
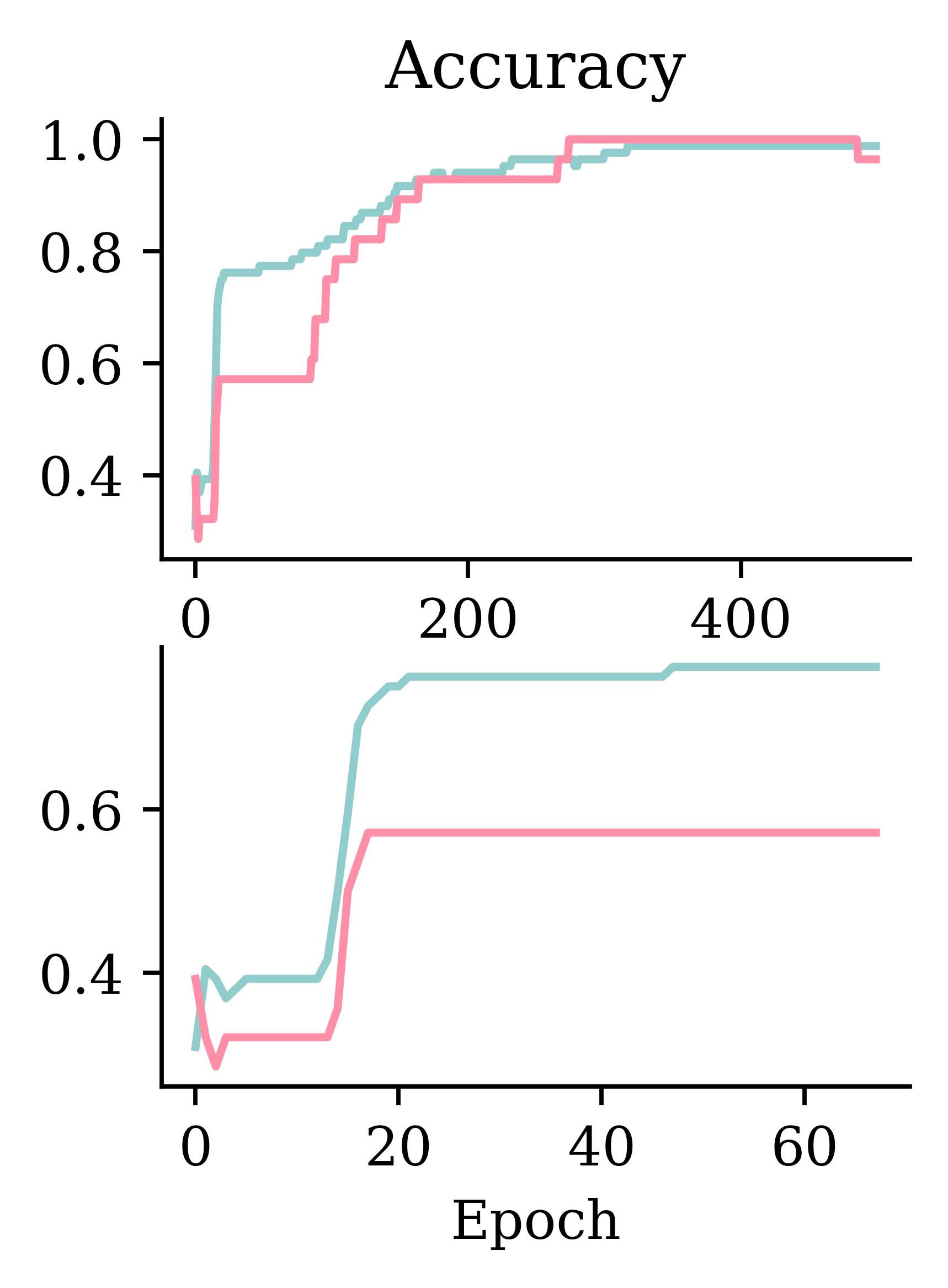
Stopped after 70 epochs.
Left hand side plots show how loss behaved without and with early stopping. Right hand side plots show how accuracy performed without and with early stopping.
What is the softmax activation?
It creates a “probability” vector: \text{Softmax}(\boldsymbol{x}) = \frac{\mathrm{e}^x_i}{\sum_j \mathrm{e}^x_j} \,.
In NumPy:
out = np.array([5, -1, 6])(np.exp(out) / np.exp(out).sum()).round(3)
array([0.27, 0. , 0.73])
In Keras:
out = keras.ops.convert_to_tensor([[5.0, -1.0, 6.0]])keras.ops.round(keras.ops.softmax(out), 3)
tensor([[0.2690, 0.0010, 0.7310]])
Prediction using classifiers
y_test[:4]
array([[2],
[2],
[1],
[1]])
The response variable y is an array of numeric integers, each representing a class to which the data belongs. However, the model.predict() function returns an array with probabilities not an array with integers. The array displays the probabilities of belonging to each category.
If the target is a categorical variable with only two options, this is a binary classification problem. The neural network’s output layer should have one neuron with a sigmoid activation function. The loss function should be binary cross-entropy. In Keras, this is called loss="binary_crossentropy".
If the target has more than two options, this is a multi-class classification problem. The neural network’s output layer should have as many neurons as there are classes with a softmax activation function. The loss function should be categorical cross-entropy. In Keras, this is done with loss="sparse_categorical_crossentropy".
If the number of classes is c, then:
Target
Output Layer
Loss Function
Binary (c=2)
1 neuron with sigmoid activation
Binary Cross-Entropy
Multi-class (c > 2)
c neurons with softmax activation
Categorical Cross-Entropy
Optionally output logits
If you find that the training is unstable, you can try to use a linear activation in the final layer and have the loss functions implement the activation function.
If the number of classes is c, then:
Target
Output Layer
Loss Function
Binary (c=2)
1 neuron with linear activation
Binary Cross-Entropy (from_logits=True)
Multi-class (c > 2)
c neurons with linear activation
Categorical Cross-Entropy (from_logits=True)
Code examples
Binary
model = Sequential([# Skipping the earlier layers Dense(1, activation="sigmoid")])model.compile(loss="binary_crossentropy")
Multi-class
model = Sequential([# Skipping the earlier layers Dense(n_classes, activation="softmax")])model.compile(loss="sparse_categorical_crossentropy")
Binary (logits)
from keras.losses import BinaryCrossentropymodel = Sequential([# Skipping the earlier layers Dense(1, activation="linear")])loss = BinaryCrossentropy(from_logits=True)model.compile(loss=loss)
Multi-class (logits)
from keras.losses import SparseCategoricalCrossentropymodel = Sequential([# Skipping the earlier layers Dense(n_classes, activation="linear")])loss = SparseCategoricalCrossentropy(from_logits=True)model.compile(loss=loss)
Package Versions
from watermark import watermarkprint(watermark(python=True, packages="keras,matplotlib,numpy,pandas,seaborn,scipy,torch"))